1. 问题描述
在调用PHP后台接口发现后台接口返回的json字符串Gson一直解析不通过:
List districts = null;
if (!TextUtils.isEmpty(myString))
{
Gson gson = new Gson();
try { districts = gson.fromJson(myString, new TypeToken<List>() {}.getType()); } catch (Exception e) { e.printStackTrace(); } } 异常提示的大概内容是:第一行第一列期望对象数组开头,实际却是字符串开头
以上myString 是个json字符串,内容如下:

2. 分析过程
(1) 将以上的json字符串复制到json在线检查,也是没通过
(2) json字符串保存在文件,在chrome浏览器打开此文件也没有显示json排版的格式;
(3) 仔细检查格式,没发现什么问题,根据异常提示的信息,很有可能是第一行第一列有特殊字符存在
(4) 仔细在EditPlus 编辑器查看上面的json字符串,发现 [ 很特别,不是正常的总括号
(5) 如果手动修改成正常的 [ , 复制到JSON在线检查里面,json合格,通过!
(6) 修改前的json字符串保存成一个文件,修改后的json字符串保存成一个文件
(7)为了进一步看出是这第一个什么字符,我改用了UltraEdit编辑器分别打开修改前的文件 和修改后的文件


然后分别 以16进制查看(编辑->16进制函数 -> 16进制编辑)
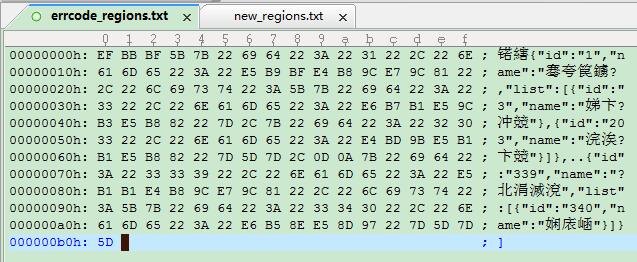
有特殊字符串的json字符串errorcode_region.txt 文件16进制查看内容如下:
没有特殊字符,修改后正常的json字符串 new_regions.txt 文件 16进制查看内容如下:
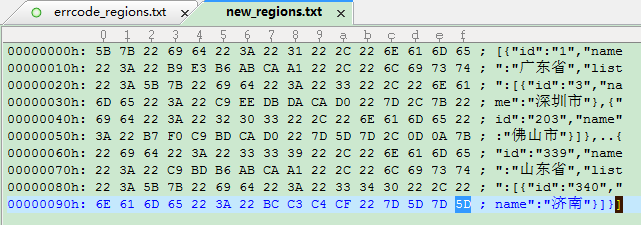
通过比较发现在正常的 [ 符号 多的特殊字符 16进制是 EF BB BF
通过 查看相关资料 它是 BOM (Byte Order Mark,字节序标记)的 UTF-8编码。就是说此json 字符串 是 带了 BOM的UTF-8 格式的。
以下是UTF-8 BOM的一些说明,参考 :UTF-8有BOM和无BOM的区别
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
UTF- 8编码的文件中,BOM占三个字节。如果用记事本把一个文本文件另存为UTF-8编码方式的话,用UE打开这个文件,切换到十六进制编辑状态就可以看到开 头的FFFE了。这是个标识UTF-8编码文件的好办法,软件通过BOM来识别这个文件是否是UTF-8编码,很多软件还要求读入的文件必须带BOM。可 是,还是有很多软件不能识别BOM。
在Firefox早期的版本里,扩展是不能有BOM的,不过Firefox 1.5以后的版本已经开始支持BOM了。现在又发现,PHP也不支持BOM。PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。
3. 解决办法
既然知道了问题原因:PHP后台返回的UTF-8格式的JSON字符串开头带了BOM,那解决办法就是 去掉 这个BOM。
怎样去掉呢? 不可能在客户端去掉,应该是在PHP后台根据接口名字,找到该接口对应的代码所在的PHP文件,将此PHP文件保存格式为UTF-8 无BOM 格式。
(1) 用EditPlus 另存为的时候,编码选择 UTF-8

如果选择的是 UTF-8 +BOM, 那就包含了 BOM
注: 用EditPlus 打开带BOM的文件的时候,会在底部显示 UF-8+ ![]()
打开不带BOM的文件的时候,会在底部显示 UTF-8
![]()
(2) 用UltraEdit 另存为的时候,编码选择 UTF-8 无BOM

如果选择的是 UTF-8 , 那就包含了 BOM