从 0 到 1 搭建技术中台之 ID 生成服务实践
前言
ID 生成器在前后端系统内都比较常见,应用场景广泛,如:订单 ID、账户 ID 、流水号、消息 ID 等等。常见的 ID 类型如下:
UUID 和 GUID:GUID 和 UUID 本质类似,GUID 来源于微软。一个 UUID 是一个 16 字节 (128 bit) 的数字。UUID 由网卡 MAC 地址、时间戳、名字空间 ( Namespace )、随机或伪随机数、时序等元素进行生成。优点:在特定范围内可以保证全局唯一;生成方便,单机管理即可。缺点:所占空间比较大;无序,在插入数据库时可能会引起大规模数据位置变动,性能不友好。
数据库自增 ID:主要基于关系数据库如 MySQL 的 auto_increment 自增键,在业务量不是很大时使用比较方便。基于数据库自增字段也有一些变种,如下面会介绍到的号段模式。优点:实现成本低,直接基于 DB 实现,不需要引入额外组件;能够实现单调自增,递增场景友好。缺点:需要考虑高可用、横向扩展问题。
snowflake :雪花算法由毫秒时间戳 ( 41 位) + 机器 ID( workerId 10 位) + 自增序列 ( 12 位),理论上最多支持 1024 台机器每秒生产 400w 个 ID。雪花算法综合考虑了性能、全局唯一、趋势自增、可用性等,是一种非常理想的 ID 生成算法,也是伴鱼内部使用最为广泛的 ID 生成算法。
伴鱼内部也有很多 ID 生成的需求,像是我们的订单、支付单、一对一课程、绘本、 IM 聊天消息、账号等等。ID 类型上也基本脱离不了上面几种,但是使用质量上参差不齐。
背景
第一阶段:各自封装
伴鱼早期业务量比较少,各系统基本都是有自己的 ID 生成模块,有基于 TiDB 自增 ID 的,有基于 UUID 的,也有基于雪花算法的,其中雪花算法也被称为 snowflake ,使用最为广泛。各自封装模块比较简单,但是实现分散、各系统模块的质量也很难统一保证。
第二阶段:集成框架
为了解决上述分散实现的问题,我们统一实现了一个综合各类 ID 生成功能的基础库,供业务方统一调用。统一基础库解决了分散调用问题,但是对于 snowflake 这种带有 workerId 的算法,需要业务系统关注 workerId 分配的逻辑。于是,我们把 snowflake 的逻辑封装到了服务治理框架内,服务启动时,由框架来负责 workerId 的分配和服务内的唯一性。
第三阶段:idgen 服务
封装到框架后,同一服务的不同实例之间可以很好的处理 workerId 的分配问题。但是, workerId 的逻辑也使得服务内多个实例成为了有状态实例, K8s 部署也只能使用 StatefulSet 。最近两年,伴鱼业务量突飞猛进,系统数量暴增,业务对系统的稳定性、弹性提出了更高的要求,我们需要 ID 生成逻辑非常稳定、高效,我们需要服务实例都是无状态实例 Deployment ,使服务具备快速滚动升级、弹性伸缩的能力。基于这样的背景,我们决定提供一个单独的 ID 生成服务,需求如下:
支持 DB 号段和 snowflake 两种模式
ID 生成器自身的可用性、稳定性非常高,具备时钟校准能力
TP99 必须非常低
兼容现有逻辑,业务迁移要非常方便
服务使用 Deployment 部署
伴鱼的 ID 生成器能基本经历了以上三个阶段,可能有人会有疑问: 开源 ID 生成服务也不少,为什么不直接使用开源项目呢?这里有三点考虑:
开源 ID 生成服务基本以 Java 实现为主,比如 Leaf、tinyid ,我司的技术栈以 Go 为主。
历史原因,我司之前都是使用 slowId (后面有介绍,防止 js 中精度丢失的简单处理)的方式,即使直接使用开源项目也一定要进行二次开发。
ID 生成本身并不复杂,以上开源项目也缺少必要的时钟回退、多节点时钟校验等优化。综合考虑下来,我们还是决定自己开发,后续也有开源的计划,期望能为 Go 社区做些贡献。
基于以上背景和需求,我们打造了伴鱼第一代 ID 生成服务: idgen 。
系统设计
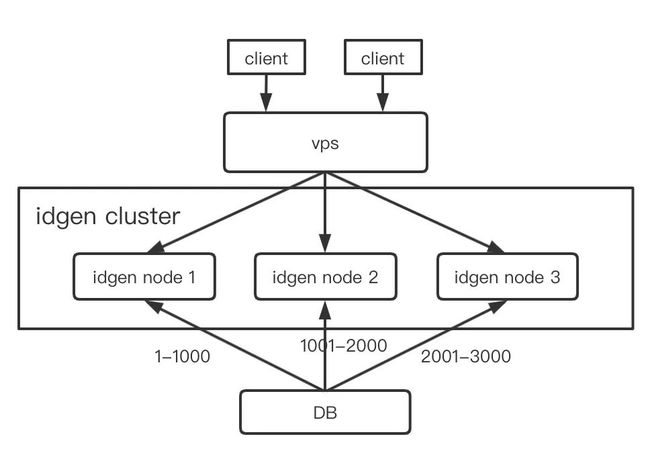
DB 号段模式
号段模式可以理解为对 DB 自增 ID 方案的优化,本质是利用批量获取的方式,定期获取一个号段,缓存在本地供外部使用,减轻 DB 的压力,提升对外服务性能。交互形式如下:
snowflake 模式
snowflake 是 Twitter 于 2010 年首次对外公开,其值为 64 位整数,可以做到全局唯一。构造如下:

系统优化
号段模式优化
双 buffer 提升性能、减少毛刺
DB 号段模式的原理比较简单,但是上面的实现方案也有一定的潜在风险。首先,任一节点的号段耗尽时都需要从 DB 中取出下一个号段再返回 ID ,这个延迟会造成一定的请求毛刺。其次,如果请求 DB 的时候出现网络错误、慢查询,对于可用性方面也带来了一定的挑战。
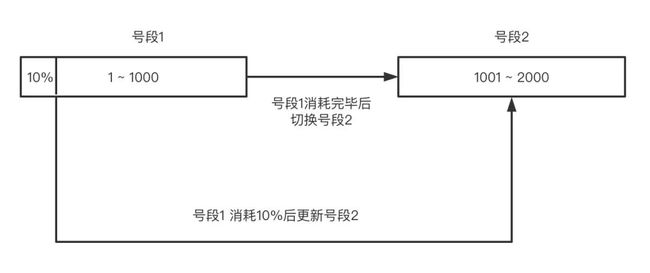
针对毛刺问题,我们可以同时分配两个 buffer ,当其中一个 buffer 消耗到一定阈值时,异步更新下一个 buffer,这个阈值是可调整的。双 buffer 交互方式如下:
动态步长
一个号段的使用时间是由消费速度和 buffer 长度决定的。为了尽最大可能提升可用性, buffer 自然是越长越好,这样在 DB 出问题时,我们还能抗一段时间。但是, buffer 太长有坏处,如果程序异常退出、正常重启,buffer 太长很容易造成巨大的 ID 空洞。所以我们根据 ID 消耗速度和规划时间,动态调整 buffer 的长度,尽量在提升可用性的同时避免 ID 空洞。
snowflake 优化
snowflake workerId 分配机制
workerId 在 snowflake 内必须保证全局不重复,范围在 0-1023 之间 (如果调整各个段落的位数,会发生变化)。可以通过对实例打标记的方式,分配 workerId ,但是打标记会给实例带来一定的状态,我们还是期望实例是无状态的 ( idgen 服务通过 K8s Deployment 模式部署)。etcd 可以充当全局 coordinator 的角色,通过 etcd 原子分配的方式,我们可以比较容易获取到全局唯一的 workerId 。
snowflake 容错机制
snowflake 本身的容错有两点,一是防止自身节点时钟回拨,另一点是防止节点自身时钟不正确。
时钟回拨
对于时钟回拨,我们会在 etcd 内记录节点上次的时间,节点启动时,根据节点 ID 从 etcd 取回之前的时间。如果判定回拨非常少,我们可以等待回拨时间过后,正常启动。如果回拨过大,节点直接启动失败并报错,报错后人为介入处理。这里还有一个细节,节点是定时上报的,假设每 interval 秒上报一次当前时间,如果节点失败后被快速拉起,新节点和旧节点之间可能存在时间冲突的风险。对于这种情况,我们采取上报时间为 now + interval 秒的方式,这样新节点需要超过这个时间戳,问题自然解决 (或者新节点启动时等待 timestamp + interval 秒以上,启动不是太顺滑,不推荐)。
多节点时钟校验
对于时钟错误,机房都会有 NTP 调整时钟,一般机器都不会有问题。为了进一步降低时钟错误风险,每个节点会定期上报自己的节点信息 ( IP / Port) 到 etcd ,同时每个节点都有一个 rpc 方法,可供外界获取本节点的时间戳。一个新节点启动时,会通过 etcd 注册的其他节点信息,并发调用 rpc 方法获取其他节点的时间戳,然后一一对比,如果差异过大,则代表本节点时间戳可能有问题,直接报错,人为介入处理。
这里大家可能会有两个个疑问:
一是为什么不采用把各个节点上报时间戳到 etcd ,新启动节点直接取 etcd 内的时间戳进行逐个判断呢?
这里主要考虑时间校准的准确性,如果各节点定期上报时间戳,各节点时间戳差异会比较大,这会导致我们判断时间偏差的幅度比较大,准确性会下降。
二是如果第一个节点时间戳是错误的,后续正常节点启动怎么办?
首先,这种情况发生的几率非常低并且此时我们启动正常节点时肯定会报错,人为介入。报错时,直接停掉异常节点,然后逐个启动正常的新节点,第一个新节点启动时, etcd 内也没有其他节点信息,无需校验。
接口优化
批量获取
有一些业务会有这样的顾虑,虽然 idgen 服务进一步提升了服务稳定性和可用性,但是多了一次 rpc 调用,貌似也不是很划算。首先,这种 rpc 调用其实在整个业务逻辑里耗时占比微乎及微,所以一般都不会成为问题。但是,有的服务就是特别在意,比如它内部可能是个循环调用,每次 rpc 请求,循环 100 次调用 idgen 服务,针对这种情况,我们提供了一个批量获取 ID 的 rpc 方法。批量的个数和上限都是按照接口超时时间和每秒生产数做一个折中。这里其实还有其他方法可以进一步降低整体耗时,比如我们提供具备 pipeline 功能的 sdk ,业务系统看起来还是一个一个获取,其实 sdk 层面都是缓存 + 批量获取的方式,这样获取 ID 的性能也会比较好。
伴鱼特色
slowId
由于历史原因 (和前端 js 交互,使用 float 类型,js 没有 int64 类型,如果直接使用原生 snowflake 会出现精度损失),我司不少服务使用了 snowflake 的变种: 由 41 bit 毫秒级时间戳,10 bit 的 workId ,以及 1 位的自增序列组成的 ID 返回给前端,虽然没有精度损失,但是这种 ID 获取方式性能比较差 (每毫秒最多两个 ID )。所以,如果大家有跟前端 ID 交互,优先选择字符串类型,目前我司不少服务也已经逐渐迁移为标准 snowflake 。
业务迁移
idgen 服务上线后,开始推动业务系统进行接入。
迁移准备
我们首先通过代码扫描的方式,整理出一份当前使用到 id 生成库的服务列表。然后,逐个业务负责人沟通迁移,同时,我们也提供了 rpc 服务的简单封装函数,业务改动非常小,对接成本非常低。
切换时冲突
在对接的过程中我们发现,由于以前的服务使用了 0-X (实例部署个数) 这段 workerId ,如果 idgen 也使用这段 workerId ,在切换的过程中,有一定的概率造成 ID 重复。所以,我们在 idgen 服务增加了手工指定 workerId offset 的功能,优先将 idgen 的 workerId 调到一个比较大的起始区间,迁移冲突的问题就解决了(后续迁移完成之后,我们可以在调回到 0-X 区间)。
总结
目前 idgen 服务已经对接了大几十个服务,高峰期 TP99 在 3ms 左右,一直稳定运行。下一步,除了对接更多的服务,我们会进一步提升 idgen 的稳定性和性能,包括提供定制化的客户端、一定的 ID 缓存机制等等。另外,目前内部正在进行框架剥离,剥离后我们会把 idgen 开源出去,希望能为 Go 社区也提供一个企业级的 ID 生成项目。
