Shell练习题(五)
Shell练习题(五)
- 1.统计/var/log下的文件个数
- 2.for循环
- 3.批量添加用户
- 4.shell 脚本里的特殊字符 `$(( ))、$( )、``与${ }`
- 5.查找出uid大于10000的用户,然后删除,必须使用for循环。
- 6.根据IP地址检查网络192.168.1.0/24中存活的主机IP
- 7.Shell脚本统计文件行数的几方法
- 获取特定目录所有文件的行数
- 获取特定目录特定扩展名文件的行数
- 8.xargs 是给命令传递参数的一个过滤器
- 9.删除本机中若干文件,/root/file.list中记录了这些文件的绝对路径,请用脚本实现
- 10.取出/etc/passwd文件中shell出现的次数
- 11.文件整理
- 12. 打印出本机交换分区大小
- 13.问题:清除本机除了当前登陆用户以外的所有用户。
- 14.在目录/tmp下找到100个以abc开头的文件,然后把这些文件的第一行保存到文件new中。
- 15.把文件b中有的,但是文件a中没有的所有行,保存为文件c,并统计c的行数
- 16.取出文件aaa.txt的第4到7行
- 17.找出当前目录下txt结尾的文件
- 18.查找/usr目录下超过1M的文件
- 19.写一个定时任务5点到8点执行
- 20.mysql主从复制原理
- 21.DNS查询的两种模式
- 22.正向代理和反向代理
- 23.文件file1
- 24.补充
1.统计/var/log下的文件个数
find /var/log/ -type f | wc -l
2.for循环
for i in 的各种用法 :
for i in “file1” “file2” “file3” for i in /boot/* for i in /etc/*.conf for i in $(seq -w 10) --》等宽的01-10seq [选项]… 尾数 seq [选项]… 首数 尾数 seq [选项]… 首数 增量 尾数
-f, --format=格式 使用printf 样式的浮点格式
-s, --separator=字符串 使用指定字符串分隔数字(默认使用:\n)
-w, --equal-width 在列前添加0 使得宽度相同
-f选项:指定格式
[root@oracle11g ~]# seq -f "%3g" 9 11
9
10
11
%后面指定数字的位数,默认是%g。
如下%3g那么数字位数不足部分是空格。加个0,表示不足补分以0来填补。
这样的话数字位数不足补分是0,%前面的str是指定字符串
[root@oracle11g ~]# seq -f "%03g" 9 11
009
010
011
-w选项:指定输出数字同宽
[root@oracle11g ~]# seq -w 98 102
098
099
100
101
102
不能和-f一起用,输出是同宽的。
-s选项:指定分隔符(默认是回车)
[root@oracle11g ~]# seq -s" " -f"str%03g" 9 11
str009 str010 str011
指定 = 作为分隔符号:
[root@oracle11g ~]# seq -s'=' 1 5
1=2=3=4=5
for i in {1…10}
for i in $( ls )
$@: 所有位置变量的内容
$#: 位置变量的个数
$0: 文件名
$*: 所有位置变量的内容
产生十个随机数
for i in {0…9};do echo $RANDOM;done
for i in $(seq 10);do echo $RANDOM;done
3.批量添加用户
#!/bin/bash
for i in $(cat /root/users.txt) --》从列表文件读取文件名
do
useradd $i
echo "123456" | passwd --stdin $i --》通过管道指定密码字串
done
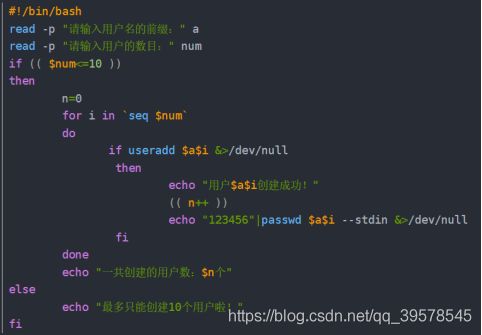
批量添加用户并且满足以下要求
[root@oracle11g ~]# 请输入用户名的前缀:stu
请输入用户数目:15
最多只能同时新建10个用户
[root@oracle11g ~]# bash add.sh
请输入用户名的前缀:sxkj
请输入用户的数目:2
用户sxkj1已经创建成功
用户sxkj2已经创建成功
一共创建的用户数:2个
4.shell 脚本里的特殊字符 $(( ))、$( )、``与${ }
数组(),数组元素个数${#array[@]} ,数组的所有元素${array[*]},字符串长度${#str}
shell 脚本里的 特殊字符 $(( ))、$( )、``与${ }的区别
1. 在bash中,$( )与` `(反引号)都是用来作命令替换的。
2. ${ }变量替换 、 ${} 里面还可以有 #*,##*,#*,##*,% *,%% *
file=/dir1/dir2/dir3/my.file.txt
可以用${ }分别替换得到不同的值:
${file#*/}: 删掉第一个 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}: 删掉最后一个 / 及其左边的字符串:my.file.txt
${file#*.}: 删掉第一个 . 及其左边的字符串:file.txt
${file##*.}: 删掉最后一个 . 及其左边的字符串:txt
${file%/*}: 删掉最后一个 / 及其右边的字符串:/dir1/dir2/dir3
${file%%/*}: 删掉第一个 / 及其右边的字符串:(空值)
${file%.*}: 删掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}: 删掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my
记忆的方法为:
#是去掉左边(键盘上#在 $ 的左边)
%是去掉右边(键盘上% 在$ 的右边)
单一符号是最小匹配;两个符号是最大匹配
3. $(( )) 可以 整数运算、进制转换、重定义变量值
[root@localhost ~]# echo $((2*3))
6
[root@localhost ~]# a=5;b=7;c=2
[root@localhost ~]# echo $((a+b*c))
19
[root@localhost ~]# echo $(($a+$b*$c))
19
4. ${name[*]} ${name[@]} ${#name[*]} 区别
在linux的shell里,${name}可以表示变量,也可以表示数组。
name后面加〔〕的,一般是数组,
${name[*]} 是数组所有元素(all of the elements)
${name[@]} 是数组每一个元素(each of the elements) ,循环数组用这个 。
${#name[*]} 是数组元素的个数,也可以写成 ${#name[@]}
${name:-Hello} 是指,如果${name}没有赋值,那么它等于Hello,如果赋值了,就保持原值,不用管问这个Hello了。
${!array_name[@]} 、${!array_name[*]} 获取数组的下标。
5. 单小括号 ()
命令组。括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用。括号中多个命令之间用分号隔开,最后一个命令可以没有分号,各命令和括号之间不必有空格。
命令替换。等同于`cmd`,shell扫描一遍命令行,发现了$(cmd)结构,便将$(cmd)中的cmd执行一次,得到其标准输出,再将此输出放到原来命令。有些shell不支持,如tcsh。
用于初始化数组。如:array=(a b c d) 【($str) 会把字符串按照 字段分隔符:空格、制表符、换行符 ,分割形成 数组】
取子串及替换

5.查找出uid大于10000的用户,然后删除,必须使用for循环。
#/bin/bash
u_uid=(`cat /etc/passwd | awk -F: '{print $3}'`)
u_name=(`cat /etc/passwd | awk -F: '{print $1}'`)
for i in `seq ${#u_uid[@] }`
do
if (( ${u_uid[i-1]} > 10000 ))
then
userdel -r ${u_name[i-1]}&&echo "${u_name[i-1]} delete ok"
fi
done
6.根据IP地址检查网络192.168.1.0/24中存活的主机IP
#!/bin/bash
for ip in 192.168.1.{1..254}
do
ping -c1 -w1 “${ip}” &> /dev/null
if [ $? -eq 0 ];then
echo “${ip} is ok”
fi
done
1、ping -c1 -w1 中-c1是指ping的次数,-w是指执行的最后期限,也就是执行的时间,单位为秒
2、&>/dev/null 是指标准输出和错误输出都输出到/dev/null上,而不在界面上显示;
关于ping命令的一个最经典的脚本:

7.Shell脚本统计文件行数的几方法
获取单个文件行数
文件:test1.sh
行数:20
方法一
awk '{print NR}' test1.sh|tail -n1
NR 行对应的行号
tail -n1 取最后一行
方法二
awk 'END{print NR}' test1.sh
方法三
grep -n "" test1.sh|awk -F: '{print'}|tail -n1
-n:显示匹配行及行号 grep -n "" test1.sh,显示行号和对应的内容
方法四
sed -n '$=' test1.sh
sed -n '$=' test1.sh 中'$='的详细含义
是统计services文件的行数,等同于cat test1.sh | wc -l 命令
加$是统计总的行数,不加$会依次显示所有行号。不加-n会打印出所有内容,并在最后一样显示总的行数。
获取特定目录所有文件的行数
#!/bin/bash
filesCount=0
linesCount=0
function funCount()
{
for file in ` ls $1 `
do
if [ -d $1"/"$file ];then
funCount $1"/"$file
else
declare -i fileLines
fileLines=`sed -n '$=' $1"/"$file`
let linesCount=$linesCount+$fileLines
let filesCount=$filesCount+1
fi
done
}
if [ $# -gt 0 ];then
for m_dir in $@
do
funCount $m_dir
done
else
funCount "."
fi
echo "filesCount = $filesCount"
echo "linesCount = $linesCount"
获取特定目录特定扩展名文件的行数
#!/bin/bash
extens=(".c" ".cpp" ".h" ".hpp")
filesCount=0
linesCount=0
function funCount()
{
for file in ` ls $1 `
do
if [ -d $1"/"$file ];then
funCount $1"/"$file
else
fileName=$1"/"$file
EXTENSION="."${fileName##*.}
echo "fileName = $fileName Extension = $EXTENSION"
if [[ "${extens[@]/$EXTENSION/}" != "${extens[@]}" ]];then
declare -i fileLines #将变量声明为整数
fileLines=`sed -n '$=' $fileName`
echo $fileName" : "$fileLines
let linesCount=$linesCount+$fileLines
let filesCount=$filesCount+1
fi
fi
done
}
if [ $# -gt 0 ];then
for m_dir in $@
do
funCount $m_dir
done
else
funCount "."
fi
echo "filesCount = $filesCount"
echo "linesCount = $linesCount"
8.xargs 是给命令传递参数的一个过滤器
find /sbin -perm +700 |ls -l #这个命令是错误的
find /sbin -perm +700 |xargs ls -l #这样才是正确的
写一行命令,将所有该机器的所有以“.log.bak“为后缀的文件,打包压缩
find -type f -name “*.log.bak” |xargs tar zcf /tmp/all.tar.gz
9.删除本机中若干文件,/root/file.list中记录了这些文件的绝对路径,请用脚本实现
#!/bin/bash
while read line
do
rm $line -f
done < /root/file.list
10.取出/etc/passwd文件中shell出现的次数
问题: 下面是一个/etc/passwd文件的部分内容。题目要求取出shell并统计次数,shell是指后面的/bin/bash,/sbin/nologin等,如下面/bin/bash出现4次,/sbin/nologin出现1次。
hyn:x:525:500::/home/hyn:/bin/bash
ljlxx:x:526:500::/home/ljlxx:/bin/bash
lzj:x:527:500::/home/lzj:/bin/bash
wfly:x:528:500::/home/wfly:/bin/bash
squid:x:23:23::/var/spool/squid:/sbin/nologin
答案:cat /etc/passwd|awk -F: ‘{print $7}’|sort|uniq -c
解析:
使用awk根据冒号分割内容,打印输出分割后的第7列,也就是shell所在列。然后调用sort命令排序并使用uniq -c统计每个shell出现的次数。
11.文件整理
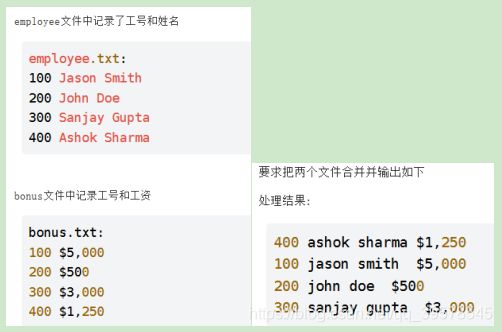
参考答案:
paste employee.txt bonus.txt | awk '{print $1,$2,$4,$5}'|tr '[:upper:]' '[:lower:]'|sort -k 2
解析:
这里用到好几个命令,包括paste,awk,tr以及sort。paste命令用于合并多个文件的同行数据,如上面两个文件employee和bonus调用paste后合并成。 sort -k 2 按文件第2个域排序。
100 Jason Smith 100 $5,000
200 John Doe 200 $500
300 Sanjay Gupta 300 $3,000
400 Ashok Sharma 400 $1,250
paste employee.txt bonus.txt

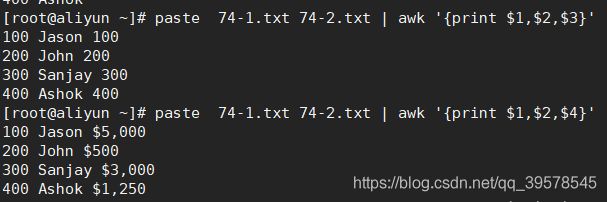

paste -s employee.txt bonus.txt
![]()
paste -d: 使用-d指定合并时加入的符号
12. 打印出本机交换分区大小
top -n 1|grep Swap | awk '{print $2 ,$9/1000"M"}' 才是正解好像。都是要看具体情况
13.问题:清除本机除了当前登陆用户以外的所有用户。
kill $(who -u|grep -v `whoami`|awk '{print $6}'|sort -u)
解析:
who -u显示所有当前用户。grep -v选取当前登录用户以外的所有用户。awk打印用户进程ID。sort -u会删除相同的行。最后用kill命令终止。
在bash中,$( )与(反引号)都是用来作命令替换的
14.在目录/tmp下找到100个以abc开头的文件,然后把这些文件的第一行保存到文件new中。
答案1:
#!/bin/sh
for filename in `find /tmp -type f -name "abc*"|head -n 100`
do
sed -n '1p' $filename>>new
done
答案2:
find /tmp -type f -name “abc*” | head -n 100 | xargs head -q -n 1 >> new
补充:head -q 不显示文件名

15.把文件b中有的,但是文件a中没有的所有行,保存为文件c,并统计c的行数
grep -vxFf a b | tee c | wc -l
解析:grep选取-v表示不选择匹配的行,-F表示匹配的模式按行分割,-f a表示匹配模式来自文件a,最后表示目标文件b。即grep命令从b中选取a中不存在的行。tee c命令创建文件c,wc -l命令统计行数。
tee命令主要被用来向standout(标准输出流,通常是命令执行窗口)输出的同时也将内容输出到文件 (控制台显示的 输出到文件)
16.取出文件aaa.txt的第4到7行
[root@localhost ~]# cat aaa.txt
1.aaa
2.bbbbbbb
3.ccccccccccccc
4.dddddddddddddddddddddd
5.eeeeeeeeeeeeeeeeee
6.ffffffffffffffffffffffffffffffffff
7.gggggggggggggggggggggg
8.hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
9.iiiiiiiiiiiiiiiiiiii
10.jjjjjjjjjjjjjjjjjjjjjjjjjj
11.kkk
12.llllllllll
[root@localhost ~]# sed -n '4,7p' aaa.txt
4.dddddddddddddddddddddd
5.eeeeeeeeeeeeeeeeee
6.ffffffffffffffffffffffffffffffffff
7.gggggggggggggggggggggg
17.找出当前目录下txt结尾的文件
[root@localhost ~]# ls
1.txt 2.txt 3.pdf aaa.txt anaconda-ks.cfg
[root@localhost ~]# find ./ -name "*.txt"
./aaa.txt
./1.txt
./2.txt
18.查找/usr目录下超过1M的文件
[root@localhost ~]# find /usr -type f -size +10240k
/usr/lib/locale/locale-archive
/usr/lib64/libicudata.so.50.1.2
19.写一个定时任务5点到8点执行
分时日月周
* 5-8 * * * /usr/bin/backup
20.mysql主从复制原理
主库db的更新事件(update、insert、delete)被写到binlog。
主库创建一个binlog dump thread,把binlog的内容发送到从库。
从库启动并发起连接,连接到主库。
从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log。
从库启动之后,创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db。
21.DNS查询的两种模式
递归查询
递归查询是一种DNS 服务器的查询模式,在该模式下DNS 服务器接收到客户机请求,必须使用一个准确的查询结果回复客户机。如果DNS 服务器本地没有存储查询DNS 信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。
迭代查询
DNS 服务器另外一种查询方式为迭代查询,DNS 服务器会向客户机提供其他能够解析查询请求的DNS 服务器地址,当客户机发送查询请求时,DNS 服务器并不直接回复查询结果,而是告诉客户机另一台DNS 服务器地址,客户机再向这台DNS 服务器提交请求,依次循环直到返回查询的结果为止。
22.正向代理和反向代理
正向代理是代理客户端,反向代理是代理服务器。
正向代理
比如我们国内访问国外网站,直接访问访问不到,我们可以通过一个正向代理服务器,请求发到代理服,代理服务器能够访问国外网站,这样由代理去国外网站取到返回数据,再返回给我们,这样我们就能访问了。
反向代理
反向代理实际运行方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时客户只是访问代理服务器却不知道后面有多少服务器。
23.文件file1
1)查询file1里面空行的所在行号
grep -n ^$ file1
2)查询file1以abc结尾的行
grep abc$ file1
3)打印出file1文件第1到第三行
head -n3 file1
sed "3q" file1
sed -n "1,3p" file1
24.补充
grep -c 统计文件中含某单词的行数
grep -n 含义某单词的行号以及内容
连接两个字符串:
V1="Hello"
V2="World"
V3=${V1}${V2}
echo $V3
输出:HelloWorld
两个整数相加
V1=1
V2=2
let V3=$V1+$V2
echo $V3
A=5
B=6
echo $(($A+$B)) # 方法 2
echo $[$A+$B] # 方法 3
expr $A + $B # 方法 4
echo $A+$B | bc # 方法 5
awk 'BEGIN{print '"$A"'+'"$B"'}' # 方法 6
$() 和 ` ` 都是用来作命令替换的
$(()) $[] 可以 整数运算、进制转换、重定义变量值
[] 即为test命令的另一种形式。
shell 脚本里的 特殊字符 $(( ))、$( )、``与${ }的区别 —— 详情见4.
[[ $string == abc* ]] – 检查字符串是否以字母 abc 开头
[[ $string == "abc" ]] – 检查字符串是否完全等于 abc
1) 如何获取文本文件的第 10 行 ?
head -10 file|tail -1
2) 如何在后台运行脚本 ?
在脚本后面添加 “&”。
.1.sh &
3) 如何使用 awk 列出 UID 小于 100 的用户 ?
awk -F: '$3<100' /etc/passwd
4) 哪个命令将命令替换为大写 ?
tr '[:lower:]' '[:upper:]'
5) 如何计算本地用户数目 ?
wc -l /etc/passwd|cut -d" " -f1 或者 cat /etc/passwd|wc -l
6) 不用 wc 命令如何计算字符串中的单词数目 ?
grep -c keyword 文件名
7) 如何去除字符串中的所有空格 ?
echo $string|tr -d " "
8) 写出输出数字 0 到 100 中 3 的倍数(0 3 6 9 …)的命令 ?
for i in {0..100..3}; do echo $i; done
或
for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
9) 如何在 bash 中定义数组 ?
array=("Hi" "my" "name" "is")
10) 如何打印数组的第一个元素 ?
echo ${array[0]}
11) 如何打印数组的所有元素 ?
echo ${array[@]}
12) 如何输出所有数组索引 ?
echo ${!array[@]}
13) 如何移除数组中索引为 2 的元素 ?
unset array[2]
14) 如何在数组中添加 id 为 333 的元素 ?
array[333]="New_element"
15) 在脚本中如何使用 “expect” ?
/usr/bin/expect << EOD
spawn rsync -ar ${line} ${desthost}:${destpath}
expect "*?assword:*"
send "${password}/r"
expect eof
EOD
Linux expect详解
spawn 启动新的进程
send 用于向进程发送字符串
expect 从进程接收字符串
interact 允许用户交互 (以便手动的执行后续命令,此时使用interact命令就可以很好的完成这个任务)
#!/usr/tcl/bin/expect 使用expect来解释该脚本;
set timeout 30 设置超时时间,单位为秒,默认情况下是10秒;
set host "101.200.241.109" 设置变量;
set username "root"
set password "123456"
spawn ssh $username@$host
expect "*password*" {send "$password\r"}
interact
https://www.jianshu.com/p/2fcdf764f464
【转】Linux expect详解
- 模式动作
- 传参
1.用sed修改test.txt的第2行test为exam

2.查看/web.log第25行第三列的内容
cut -f 表示显示指定字段的内容
cut -d 表示指定字段的分隔符,默认的字段分隔符为”TAB”;
sed -n ‘25p’ /web.log | cut -d “ ” -f 3
head -n 25 /web.log | tail -n 1 | cut -d “ ” -f 3
cat /web.log | awk ‘{print $3;}’
3.删除每个临时文件的最初三行
sed–i ‘1,3d’ /tmp/*.tmp
4.编写个shell脚本将当前目录下大于10K的文件转移到/tmp目录下。

5.在11月份内,每天的早上6点到12点中,每隔2小时执行一次/usr/bin/httpd.sh 怎么实现
echo "* 6-12/2 * * * root /usr/bin/httpd.sh >> /etc/crontab"

6.将file.txt的制表符,即tab,全部替换成"|"
sed-i “s#\t#|#g” file.txt
7.把当前目录(包含子目录)下所有后缀为“.sh”的文件后缀变更为“.shell”
#!/bin/bash
str=`find ./ -name \*.sh`
for i in $str
do
mv $i ${i%sh}shell
done

8.编写shell实现自动删除50个账号功能,账号名为stud1至stud50
#!/bin/bash
for((i=1;i<=50;i++));do
userdel stud$i
done
9.假设有一个脚本scan.sh,里面有1000行代码,并在vim模式下面,请按照如下要求写入对应的指令
1)将shutdown字符串全部替换成reboot
:%s/shutdown/reboot/g
2)清空所有字符
:%d 全部删除
10.1到10数字相加,写出shell脚本
#!/bin/bash
j=0
for((i=1;i<=10;i++));do
j=$[j+i ]
done
echo $j
11、如:目录dir1、dir2、dir3下分别有file1、file2、file2,请使用脚本将文件改为dir1_file1、dir2_file2、dir3_file3
#!/bin/bash
file=`ls dir[123]/file[123]`
for i in $file;do
mv $i ${i%/*}/${i%%/*}_${i##*/}
done
12、将A 、B、C目录下的文件A1、A2、A3文件,改名为AA1、AA2、AA3.使用shell脚本实现。
#!/bin/bash
file=`ls [ABC]/A[123]`
for i in $file;do
mv $i ${i%/*}/A${i#*/}
done