本文纯属个人笔记记录。(下面内容来自“网络钓鱼欺诈检测技术研究”)
网络钓鱼(phishing) 产生于1996年,由钓鱼(fishing)一词演变而来。网络钓鱼,一般情况下,会通过电子邮件、手机短信、社交通讯或主动搜索等情况,出现在用户面前。以与合法网站及其相似的链接或者页面,混淆视野。一旦有用户误以为为合法网站,在网站上注册或者登录自己的账号,便会完成信息被窃取的过程;又或者在该网站(电商或者网银等)完成交易、转账等操作,实现直接的财产欺诈。自2005年,钓鱼攻击的趋势愈演愈烈,可见APWG(国际反钓鱼工作组) 获得钓鱼攻击趋势,在开源情报可获得已有的钓鱼网站和白名单资源。在RSA(易安信公司信息安全事业部)可获取因钓鱼攻击造成的财产损失。
网络钓鱼欺诈检测技术研究 (张茜,延志伟等)
钓鱼攻击者目的:
1)获取经济利益:攻击者通过将窃取到的身 份信息卖出或者直接使用窃取到的银行账户信息 获得经济利益。
2)展示个人能力:网络钓鱼攻击者为了获得 同行的认同而实施网络钓鱼活动。
钓鱼攻击方式:
1)鱼叉式网络钓鱼攻击(spear phishing):攻击者通常锁定特定个人或某机构的特定员工及其社交账号,向其发送个性化的电子邮件,诱使他们泄露敏感信息或在电脑上安装恶意软件。
2)发送链接,混淆视觉,满足用户登录或转账等行为。
钓鱼攻击流程:

钓鱼检测方法可分几种情况,从攻击的不同实施阶段,可以分为如下3个阶段:
1)基于传播途经分析的方法;2)基于网站入口分析的方法;3)基于网站内容分析的方法。
根据检测手段可以分为:
1)基于黑名单的钓鱼检测;2)启发式钓鱼检测;3)基于视觉相似性的钓鱼检测;4)基于机器学习的钓鱼检测;4)基于nlp技术的钓鱼检测。
下图,描述这两种分类交叉情况,颜色深浅表示使用频率的高低。

基于传播途经分析的方法
网络钓鱼的传播途径包括电子邮件、短信、 电话、即时信息、各种社交平台(微博、Twitter 等)及其他新的通信方式。网络钓鱼信息的传播 和扩散是攻击者发动钓鱼攻击的第一个阶段,在 这一阶段进行网络钓鱼的检测可以将钓鱼信息直 接过滤,使其无法到达终端用户,从而构成钓鱼 攻击的第一道防线。
目前有关研究:短信钓鱼检测、电话钓鱼等。
基于网站入口分析的方法
URL
是因特网上标准的资源地址,即网站的入口。URL
仿冒在网络钓鱼中很常见,引诱用户 单击 URL 访问其搭建的钓鱼网站是网络钓鱼的重要环节之一。
一个标准的URL的格式如下:protocol://hostname[:port]/path/[;parameters][?query] #fragment
常见的URL仿冒的方法是在目标URL的基础上对主机名(host name)部分和路径(path)部分·进行部分修改替换来构造钓鱼URL,以达到混淆视听的目的。例如,攻击者使用"www.lcbc.com.cn"仿冒工商银行(真实URL为"www.icbc.com.cn")等。
钓鱼URL其他特征如图:

基于网站内容分析的方法
钓鱼网页往往采用社会工程学手段的网络钓 鱼攻击的最后一步,绝大多数的网络钓鱼最终都 引诱用户访问其事先搭建好的仿冒网站。在这种 情况下,基于网站内容分析的网络钓鱼检测实际 上是反钓鱼的最后一道防线。
钓鱼网页与真实网页十分相似,这种相似性包括Logo的相似性、Favicon的相似性、CSS架构的相似性、布局的相似性及网页整体视觉的相似性,利用这种相似性及钓鱼网页与真实网页的不同之处进行目标品牌的识别和网络钓鱼的检测十分有效。
网站内容分词还包括对网页底层HTML的分析。在网页的HTML中存在许多辨识性的特征,如标题、链出的URL与本网页URL的域名是否一致、URL与其标签是否一致,是否有隐藏字段,是都有Form表单等。 图·7总结了基于网页内容分析方法中常永涛的特征。在有些研究中只是用了HTML的文本内容,通过TF-IDF算法得到整个网页的关键词。但多数研究在对网站内容进行分析的时候,会同时使用多种HTML特征。如:是否包含有效的网络内容服务商、空链接的数目、出链的电子商务证书信息。
常用语料库
PhishTank : PhishTank[49]是一个可以让用户提 交、验证和共享网络钓鱼链接的社区网站。用户 提交可疑的钓鱼 URL 后,会有至少 2 名网站成员 进行人工检查。一旦确认为网络钓鱼,就会将该 URL 加到一个可供他人下载的数据库中。
Millersmiles
:
Millersmiles
[50]
是关于欺诈类电 子邮件和网络钓鱼行为信息的重要信息来源,它 包含了大量来自实际事例与电子邮件、伪造的 网页内容相关的文字类和图片类资料。
SpamAssassin public corpus
:SpamAssassin 是一个旨在检测垃圾邮件和钓鱼邮件的免费开源软件项目,它的公共语料库中包含大量垃圾邮件和非垃圾邮件语料信息,可为网络钓鱼邮件的检测提供数据集。
MalwarePatrol
:
MalwarePatrol
[52]
是一个由用 户贡献的免费系统。与 PhishTank
类似,任何人 都可以提交可能携带恶意软件、病毒或木马的可 疑网址。提交的 URL
被
MalwarePatrol
确认为恶 意的之后,该 URL
就会被放入一个黑名单中,供 用户下载。
Open Directory
:开放目录专案
[53]
(即
DMOZ) 是一个大型公共网页目录,它是由来自世界各地的 志愿者共同维护和建设的全球最大目录社区[54]。这 个目录下的网页依照其性质和内容分门别类,在 进行钓鱼检测的研究时可以从中获取合法 URL 的数据集。
评价指标

1)
灵敏度(
sensitivity
):将钓鱼实例预测为 钓鱼实例的能力,见式(1)
。
2)
特异度(
specificity
):将合法实例预测为 合法实例的能力,见式(2)
。
3)
误检率(
FPR, false positive rate
):将合法实例错误地预测为钓鱼实例的比例,见式(3)
。
4)
漏检率(
FNR, false negative rate
):将钓鱼 实例错误地预测为合法实例的比例,见式(4)
。
5)
准确率(
P, prediction
):在所有预测为钓 鱼的实例中,确实是钓鱼的实例所占的比例,见 式(5)
。
6)
召回率(
R, recall
):等价于
sensitivity
, 见式(6)
。
7) F-measure
:准确率
P
和召回率
R
的加权调 和平均数,计算如式(7)
。其中
β
是参数,当
β
=1 时,就是常见的 F
1
值,见式
(8)
。
9)
精确度(
ACC, accuracy
):钓鱼实例和合 法实例正确预测的比例,见式(9)
。
10)
加权错误率(
W
Err
):钓鱼实例和合法实例预测错误的加权错误率[55]
,见式
(10)
。其中,
λ 是权重系数,表示合法实例的重要程度。例如, 若 λ
=1
,则钓鱼实例和合法实例的重要程度相同;若 λ
=5
,则对于将合法实例误检为钓鱼实例的惩 罚是钓鱼实例漏检测惩罚的 5
倍。
基于黑名单的钓鱼检测方法
基于启发式的钓鱼检测方法
基于视觉相似性的钓鱼检测
基于视觉相似性的钓鱼检测不关注底层的代码或网络层面的特征,而是通过比较页面之间的视觉特征(局部特征和全局特征)来实现网络钓鱼检测。通常包括2个部分:
视觉特征和相似性度量。从古代检测网页提取一组特征,然后基于该特征集,计算该网页与数据库中所有网页之间的相似度得分。若相似度得分超过某一阈值且该网页与合法网页信息数据库中的信息不一致,则认为是钓鱼网页。
基于视觉相似性的钓鱼检测分为基于HTML文本的匹配和基于图像的匹配。现有的几种方法如下:
1)HTML DOM树,根据“视觉提示”将网页页面分块,然后使用3个度量评估待检测网站和合法网站之间的视觉相似性:块级相似性、布局相似性和风格相似性。(缺点:耗时)该方法很大程度上取决于网页分割的结果,尤其是块级相似性和布局相似性的计算,因此该方法的检测效果
依赖于DOM表示的可用性,
无法检测具有相似的外观、但DOM表示不同的网页。
2)EMD(earth movers' distance陆地移动距离)衡量网页我页面视觉相似度的方法。该方法首次将网页页面映射为低分辨率的图像,然后使用颜色特征和坐标特征表示图像的特征。利用EMD计算网页页面图像之间的特征距离,并训练一个EMD阈值项链对页面进行分类。该方法完全
基于Web页面的图像特征,不依赖于HTML内容的可用性。但是由于可疑网页和合法网页的数量巨大,
不相关的网页图像对也可能具有极高的相似度,导致误检率的增加。
3)基于EMD未考虑网页中不同部分之间的位置关系,可能导致相似检测的失效。提出基于嵌套EMD的钓鱼网页检测算法,对图像进行分割,抽取子图特征并构建网页的特征关系图(attributed relational graph),计算不同的ARG属性距离并在此基础上采用嵌套EMD方法急死俺网页的相似度。
缺陷:
1)基于视觉相似性的钓鱼检测很大程度依赖于网站快照的白名单或黑名单的使用。(个人理解:依赖已有的网站,计算其他网站与已有网站的相似度来判断,未知网站是否为钓鱼网站。) 从理论上讲,该方法是一种泛化的黑名单或白名单,需要频繁更新以保持完整性。
2)另一方面,该方法往往假设钓鱼网站与合法网站相似,但在实际应用中,该假设并不总成立。对于部分复制合法网站(小于50%)的钓鱼网站,基于视觉相似性的方法将无法成功检测。
基于机器学习的钓鱼检测
有监督、半监督和无监督三种方式进行检测。
有监督学习:
CANTINA+检测方法,分为3个阶段:1)利用HTML DOM、搜索引擎及第三方服务提取了揭示网络钓鱼攻击特征的8个新颖的特征;2)在分类过程之前,使用启发式规则过滤没有登录框的网页;3)使用机器学习算法对
URL词汇特征、Form表单、WHOIS信息、pagerank值搜索引擎检索信息等15个具有高度表达性的钓鱼特征进行学习,实现钓鱼网页的分类。
Marchal
等指出
[27]
:
1)
尽管钓鱼者试图使钓 鱼页面与目标页面尽可能地相似,但是他们在搭 建钓鱼页面时存在一定的约束;2)
网页可以由来 自网页不同部分的一组关键词(如正文文本、标 题、域名以及 URL
的一些内容等)表征,但合法 网页和钓鱼网页使用这些关键词的方式是不同 的。基于这 2 个观点,他们提出了一种用于检测钓鱼网站和目标的新方法,选取了 212 个特(如表 3 所示),然后使用 Gradient Boosting 进行钓鱼网站的检测。该方法不需要大量训练数据就可以很好地扩展到更大的测试数据,具有不依赖于语言、品牌,速度快,可以自适应钓鱼攻击及可完全在客户端实现的优点。但是该方法对基于 IP 的钓鱼 URL 进行检测时精度太低,并且可能将空的或不可用的网页以及保留域名误分为钓鱼。
Moghimi
等
[72]
则是在有监督学习的基础上, 提出了一种基于规则的网上银行钓鱼攻击检测的 方法,该方法首先使用支持向量机算法(SVM
, support vector madisone)训练网络钓鱼的检测模 型,随后使用 SVM_DT
算法提取隐藏的决策规 则,构建决树。该方法仅用 10
条规则就达到 了很高的精度和敏感性(准确率:98.86%
,
F
1
: 0.989 98,灵敏度:
1
)。同样,该方法也存在缺点,它完全依赖页面内容,并且假设钓鱼网站 的页面只使用合法页面的内容,因此难以检测 识别钓鱼攻击者重新设计的钓鱼网站。
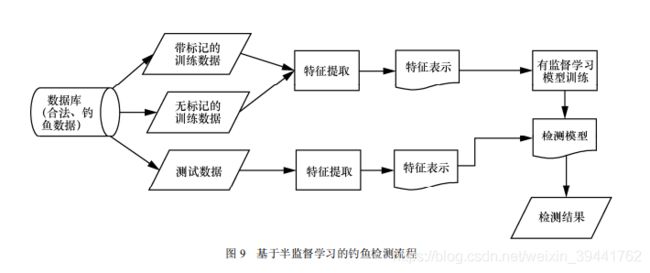
半监督学习方法
无监督学习方法
k
-means
算法通过随机设置
k
个聚类中心来构建
k 个簇,然后将实例迭代地划分到距离(如欧氏距 离)最近的聚类中心所在的簇并更新聚类中心。 重复该迭代过程直至收敛。
DBSCAN
基于实例的密度划分实例,与
k
-means
不同的是,它不需要事先确定簇的数 量。2010
年,
Liu
等
[73]
以网页页面之间的链接 关系、检索结果的排序关系、文本相似性及页 面布局相似性等关系作为特征,采用 DBSCAN 聚类算法对钓鱼网页进行识别。基于无监督学 习的网络钓鱼检测减少了人工标记的代价,但 检测的准确率不高且检测结果受数据集的结 构影响较大。
基于自然语言处理技术的钓鱼检测
挑战:
1)
网页规模迅速由
GB
级、
TB
级向
PB
、
ZB 级扩大,对网络钓鱼检测技术的存储、计算能力 的要求增大。
2)
攻击者搭建钓鱼网页成本降低,给攻击者持续缩短网络钓鱼活动的生命周期带来了便利。
3)
网络钓鱼不再局限在计算机层面,手机平 台成为网络钓鱼的新目标。2012
年趋势科技 (trend micro
)的研究发现了
4 000
条为手机网页 设计的钓鱼 URL
[75]
。尽管这个数字不到所有钓鱼 URL 的
1%
,但它表明手机平台开始成为网络钓 鱼攻击的新目标,并且由于手机屏幕的大小限制, 手机网络钓鱼更具有欺骗性。
4)
传播途径不再局限于电子邮件、手机短信 的方式,各种社交网站(如 Twitter
[76]
、微博)、 网络游戏[77]
、二维码
[78]
等的兴起使传播途径更多 元化,也让网络钓鱼检测更困难。
5)
网络钓鱼攻击的形式繁多,鱼叉式网络钓 鱼攻击、执行长欺诈、域欺骗(pharming
)、标签 钓鱼[79]
(
tabnabbing
)等各种攻击形式层出不穷, 难以应对。
6) DNSsec
协议推动较为缓慢,钓鱼攻击者 常常利用名址解析存在的漏洞,劫持合法网站展开钓鱼活动。这种网站劫持的钓鱼攻击,在用户 访问合法网站时跳转到钓鱼网站,用户往往难以 察觉,为钓鱼检测增加了难度。