Redis Cluster 踩坑案例之内存占用飙升
一、现象
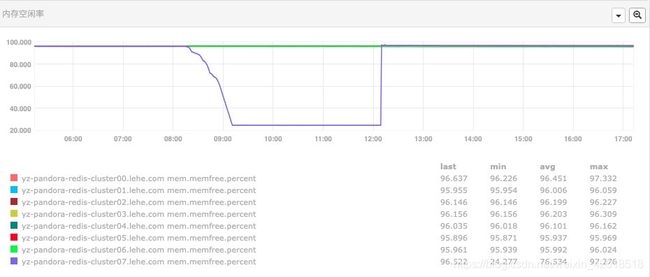
Redis Cluster 某个分片(10.20.2.53:7101)内存飙升,明显比其它高跟多,而且持续增长并达到了峰值。并且主从的内存使用量不一致。
| IP | 监听端口 | 主/从 | 实例状态 | 内存使用 | 对象数 | 连接数 | 命中率 |
|---|---|---|---|---|---|---|---|
| 10.20.0.40 | 7101 | master | 运行中 | 393.08M(Used) / 18.63G(Total) | 515897 | 10 | 82.8% |
| 10.20.0.41 | 7102 | slave | 运行中 | 393.82M(Used) / 18.63G(Total) | |||
| 10.20.0.41 | 7101 | master | 运行中 | 401.82M(Used) / 18.63G(Total) | 521823 | 40 | 0.9% |
| 10.20.0.42 | 7102 | slave | 运行中 | 401.28M(Used) / 18.63G(Total) | |||
| 10.20.0.42 | 7101 | master | 运行中 | 393.21M(Used) / 18.63G(Total) | 521020 | 16 | 2.6% |
| 10.20.0.43 | 7102 | slave | 运行中 | 394.48M(Used) / 18.63G(Total) | |||
| 10.20.0.43 | 7101 | master | 运行中 | 391.51M(Used) / 18.63G(Total) | 516917 | 25 | 1.7% |
| 10.20.2.49 | 7102 | slave | 运行中 | 391.61M(Used) / 18.63G(Total) | |||
| 10.20.2.49 | 7101 | master | 运行中 | 402.33M(Used) / 18.63G(Total) | 520599 | 23 | 2.7% |
| 10.20.2.50 | 7102 | slave | 运行中 | 402.38M(Used) / 18.63G(Total) | |||
| 10.20.2.50 | 7101 | master | 运行中 | 396.43M(Used) / 18.63G(Total) | 520566 | 25 | 1.4% |
| 10.20.2.52 | 7102 | slave | 运行中 | 395.89M(Used) / 18.63G(Total) | |||
| 10.20.2.52 | 7101 | master | 运行中 | 395.77M(Used) / 18.63G(Total) | 520354 | 33 | 8.5% |
| 10.20.2.53 | 7102 | slave | 运行中 | 394.46M(Used) / 18.63G(Total) | |||
| 10.20.2.53 | 7101 | master | 运行中 | 38.56G(Used) / 18.63G(Total) | 488550 | 14 | 83.1% |
| 10.20.0.40 | 7102 | slave | 运行中 | 385.92M(Used) / 18.63G(Total) | |||
|
|
|||||||
|
|
|||||||

二、分析原因
1. redis-cluster的bug (这个应该不存在)
2. 客户端的hash(key)有问题,造成分配不均。(redis使用的是crc16, 不会出现这么不均的情况)
3. 存在个别大的key-value: 例如一个包含了几百万数据set数据结构(这个有可能)
4. 主从复制出现了问题
5. 其他原因
三、调查原因
1、经与开发共同查询,上述1-4都不存在
2、观察info信息,有一点引起了怀疑: client_longes_output_list有些异常
# Clients
connected_clients:8
client_longest_output_list:621058
client_biggest_input_buf:0
blocked_clients:0
# Memory
used_memory:38407954848
used_memory_human:35.77G
used_memory_rss:49159024640
used_memory_rss_human:45.78G
used_memory_peak:38574845352
used_memory_peak_human:35.93G
used_memory_peak_perc:99.57%
used_memory_overhead:30219804880
used_memory_startup:1166560
used_memory_dataset:8188149968
used_memory_dataset_perc:21.32%
total_system_memory:67502866432
total_system_memory_human:62.87G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:20000000000
maxmemory_human:18.63G
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.28
mem_allocator:jemalloc-4.0.3
active_defrag_running:0
lazyfree_pending_objects:03. 于是理解想到服务端和客户端交互时,分别为每个客户端设置了输入缓冲区和输出缓冲区,这部分如果很大的话也会占用Redis服务器的内存
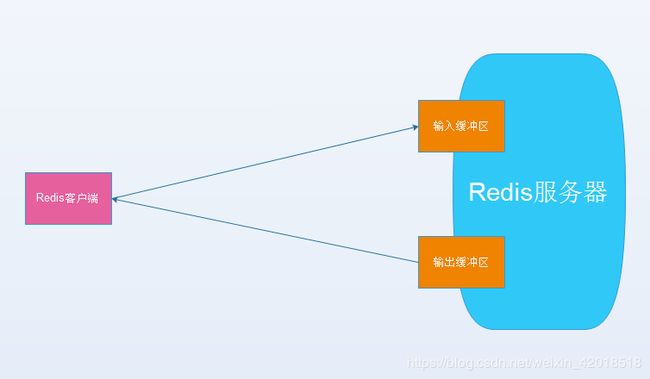
从上面的client_longest_output_list看,应该是输出缓冲区占用内存较大,也就是有大量的数据从Redis服务器向某些客户端输出。
3.1 可使用client list命令(类似于mysql processlist)来查询输出缓冲区不为0的客户端连接:
$ redis-cli -h 10.20.2.53 -c -p 7101 client list | grep -v "omem=0"
id=140028229 addr=10.20.0.82:59788 fd=11 name= age=3192 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=380887 omem=6218527258 events=rw cmd=lrange3.2 也可使用client list命令(类似于mysql processlist)来查询输入缓冲区不为0的客户端连接:
$ redis-cli -h 10.20.0.43 -c -p 7101 client list | grep -v "qbuf=0"
id=39410256 addr=10.20.0.82:54313 fd=55 name= age=698452 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=263016240 qbuf-free=298196 obl=0 oll=0 omem=0 events=r cmd=blpop
id=16093037 addr=10.20.0.82:60184 fd=380 name= age=784852 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=295578820 qbuf-free=644376 obl=0 oll=0 omem=0 events=r cmd=blpop
id=120604861 addr=10.20.0.82:55993 fd=82 name= age=93652 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=35291664 qbuf-free=834832 obl=0 oll=0 omem=0 events=r cmd=blpop
id=129242954 addr=10.20.0.82:38402 fd=63 name= age=7252 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=2734556 qbuf-free=903270 obl=0 oll=0 omem=0 events=r cmd=blpop
id=84864307 addr=10.20.0.82:42115 fd=46 name= age=439252 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=165557792 qbuf-free=604856 obl=0 oll=0 omem=0 events=r cmd=blpop
id=74603752 addr=10.20.0.82:50111 fd=45 name= age=525652 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=197932728 qbuf-free=745380 obl=0 oll=0 omem=0 events=r cmd=blpop
id=112033517 addr=10.20.0.82:52713 fd=48 name= age=180052 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=67851204 qbuf-free=759098 obl=0 oll=0 omem=0 events=r cmd=blpop
id=93981846 addr=10.20.0.82:55417 fd=78 name= age=352852 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=132902416 qbuf-free=756970 obl=0 oll=0 omem=0 events=r cmd=blpop
id=102983262 addr=10.20.0.82:53490 fd=53 name= age=266452 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=100410364 qbuf-free=756704 obl=0 oll=0 omem=0 events=r cmd=blpop
id=63819443 addr=10.20.0.82:58769 fd=95 name= age=612052 idle=0 flags=b db=0 sub=0 psub=0 multi=-1 qbuf=230471254 qbuf-free=503358 obl=0 oll=0 omem=0 events=r cmd=blpop3.3 Redis client list 详解
id: 唯一的64位的客户端ID(Redis 2.8.12加入)。
addr : 客户端的地址和端口
fd : 套接字所使用的文件描述符
age : 以秒计算的已连接时长
idle : 以秒计算的空闲时长
flags : 客户端 flag
db : 该客户端正在使用的数据库 ID
sub : 已订阅频道的数量
psub : 已订阅模式的数量
multi : 在事务中被执行的命令数量
qbuf : 查询缓冲区的长度(字节为单位, 0 表示没有分配查询缓冲区)
qbuf-free : 查询缓冲区剩余空间的长度(字节为单位, 0 表示没有剩余空间)
obl : 输出缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区)
oll : 输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里)
omem : 输出缓冲区和输出列表占用的内存总量
events : 文件描述符事件
cmd : 最近一次执行的命令
客户端 flag 可以由以下部分组成:
O : 客户端是 MONITOR 模式下的附属节点(slave)
S : 客户端是一般模式下(normal)的附属节点
M : 客户端是主节点(master)
x : 客户端正在执行事务
b : 客户端正在等待阻塞事件
i : 客户端正在等待 VM I/O 操作(已废弃)
d : 一个受监视(watched)的键已被修改, EXEC 命令将失败
c : 在将回复完整地写出之后,关闭链接
u : 客户端未被阻塞(unblocked)
A : 尽可能快地关闭连接
N : 未设置任何 flag
文件描述符事件可以是:
r : 客户端套接字(在事件 loop 中)是可读的(readable)
w : 客户端套接字(在事件 loop 中)是可写的(writeable)四、紧急处理和解决方案
1、正常解决方案:关闭掉问题客户端连接
$ redis-cli -c -p 7101 -h 10.20.2.53
10.20.2.53:7101> client kill 10.20.0.82:59788
OK
(1.65s)查看是否恢复正常(http://main.falcon2.lehe.com/screen/58?legend=on),若无变化可尝试紧急处理方案:
## info memory:
# Memory
used_memory:448897216
used_memory_human:428.10M
used_memory_rss:660447232
used_memory_rss_human:629.85M
used_memory_peak:8442572856
used_memory_peak_human:7.86G
used_memory_peak_perc:5.32%
used_memory_overhead:48079390
used_memory_startup:1206920
used_memory_dataset:400817826
used_memory_dataset_perc:89.53%
total_system_memory:67502866432
total_system_memory_human:62.87G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:20000000000
maxmemory_human:18.63G
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.47
mem_allocator:jemalloc-4.0.3
active_defrag_running:0
lazyfree_pending_objects:0
2、紧急处理方案:进行主从切换(主从内存使用量不一致),也就是redis-cluster的fail-over操作,继续观察新的Master是否有异常,通过观察未出现异常。
五、预防办法
1、 对工程师培训,讲一讲redis使用过程中的坑和禁忌
2、针对client做限制,但是官方也不建议这么做,官方的默认配置中对于输出缓冲区没有限制
3、密码:redis的密码功能较弱,同时多了一次IO
4、修改客户端源代码,禁止掉一些危险的命令(shutdown, flushall, monitor, keys *),当然还是可以通过redis-cli来完成
5、添加command-rename配置,将一些危险的命令(flushall, monitor, keys * , flushdb)做rename,如果有需要的话,找到redis的运维人员处理