数据处理数据格式转化[map/filter/reduce/re.sub/x.strftime/pd.to_datetime/sort_values/drop_duplicates/apply(str)
导包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline创建数据集
datas={'name':['张a亦','张亦','李尔','李尔','赵兆','龚珍c','熊时','王武','王一','王二','李四','赵武','孙泉'],
'phone':['133********']*13,
'date':pd.date_range('20150109',periods=13,freq='D'),
'city':['广州']*4+['东莞']+['深圳']*2+['惠州']*2+['东莞']+['广州']*3}
df=DataFrame(datas)
df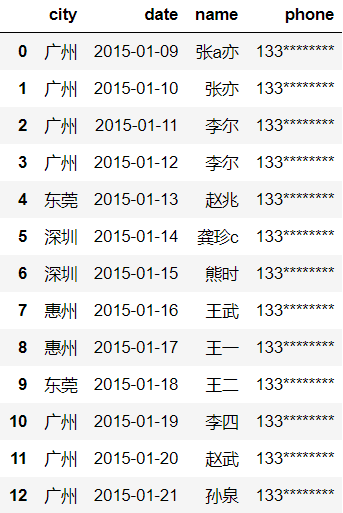
'''测试'''
pd.date_range('20150109',periods=13,freq='D')
Out:
DatetimeIndex(['2015-01-09', '2015-01-10', '2015-01-11', '2015-01-12',
'2015-01-13', '2015-01-14', '2015-01-15', '2015-01-16',
'2015-01-17', '2015-01-18', '2015-01-19', '2015-01-20',
'2015-01-21'],
dtype='datetime64[ns]', freq='D')更换列顺序
# 更换列顺序
df1=df[['name','phone','date','city']]
df1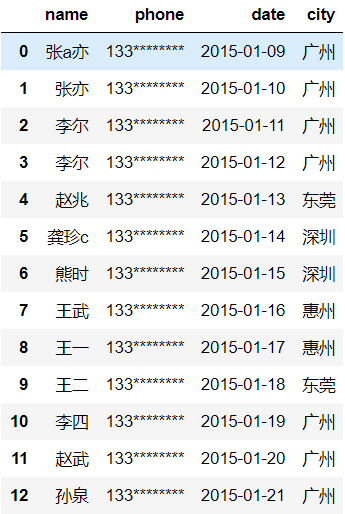
查看数据详细信息(在这里不是纯数值没作用)
df1.describe()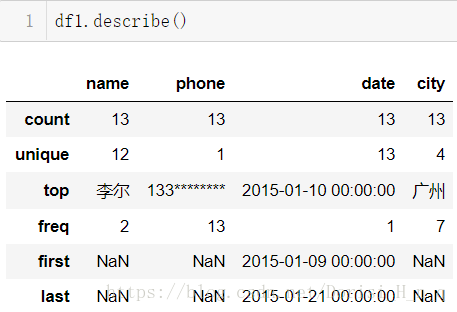
查看数据格式
# 查看数据格式,看到data是时间格式可以使用strftime("%Y-%m-%d")
df1.dtypes
Out:
df1.dtypes
name object
phone object
date datetime64[ns]
city object
dtype: object时间格式转换str格式:x.strftime("%Y-%m-%d")
# 时间的转换格式:x.strftime("%Y-%m-%d")
time1=df1.date.map(lambda x: x.strftime('%Y%m%d'))
time1
Out:
0 20150109
1 20150110
2 20150111
3 20150112
4 20150113
5 20150114
6 20150115
7 20150116
8 20150117
9 20150118
10 20150119
11 20150120
12 20150121
df1.date=time1
df1.dtypes
Out:
name object
phone object
date object
city object
dtype: object1)请将日期(yymmdd)转换成月份(yymm),并取最大的月份值。
# 查看date是字符串类型
df1.dtypes
Out:
name object
phone object
date object
city object
dtype: object
# string类转化格式只需要改变字符串拼接即可
time_zhuan=df1.date.map(lambda x: x[0:4]+x[4:6])
time_zhuan
Out:
0 201501
1 201501
2 201501
3 201501
4 201501
5 201501
6 201501
7 201501
8 201501
9 201501
10 201501
11 201501
12 201501
Name: date, dtype: objectstr转换成时间格式:pd.to_datetime()
# string类转化格式,使用pd.to_datetime(df1.date)转化成时间格式即可为xxxx-xx-xx
data_time=pd.to_datetime(df1.date)
data_time
Out:
0 2015-01-09
1 2015-01-10
2 2015-01-11
3 2015-01-12
4 2015-01-13
5 2015-01-14
6 2015-01-15
7 2015-01-16
8 2015-01-17
9 2015-01-18
10 2015-01-19
11 2015-01-20
12 2015-01-21
Name: date, dtype: datetime64[ns]
# 将转化好的时间类型赋值至表格中
df1.date=time_zhuan
df1.dtypes
Out:
name object
phone object
date object
city object
dtype: object取出最大的月份值:使用map遍历所有值取月份的值,并进行.max()
df1['date'][2]='201510'
df1['date'][5]='201509'
df1['date'][10]='201510'
df1['date'][3]='201502'
df1['date'][6]='201511'
df1['date'][0]='201506'
df1['date'][1]='201508'# 遍历date数据,截取月份部分,使用聚合max()求出最大值
month=(df1.date.map(lambda x : x[4:])).max()
# month.max()
month
2)统计客户城市的分布情况,城市是广州的客户占总客户的百分比
(df1.city=='广州').sum()/df1.city.size
Out:
0.53846153846153843)姓名的正确格式为中文,去掉姓名字段的英文字符存入数据集A中
导包
import re查看
df1.name
Out:
0 张a亦
1 张亦
2 李尔
3 李尔
4 赵兆
5 龚珍c
6 熊时
7 王武
8 王一
9 王二
10 李四
11 赵武
12 孙泉
Name: name, dtype: object测试filter
# 筛选出含有A-z的字符的名字(测试filter用)
list(filter(lambda x:re.findall('[A-Za-z]',x),df1.name))
Out:
['张a亦', '龚珍c']使用 正则: re.sub('过滤规则','要替换成的规则',str)
# 使用 正则的 re.sub('过滤规则','要替换成的规则',str)
new_name=df1.name.map(lambda x: re.sub('[A-Za-z]','',x))
new_name
Out:
0 张亦
1 张亦
2 李尔
3 李尔
4 赵兆
5 龚珍
6 熊时
7 王武
8 王一
9 王二
10 李四
11 赵武
12 孙泉
Name: name, dtype: object
# 将变换的数据替换至表格中
df1.name=new_name
df1存入数据集A中
A=df1.copy()
A3)取出姓氏为“李”的客户记录,存入数据集B中
查看
df1.name
Out:
0 张亦
1 张亦
2 李尔
3 李尔
4 赵兆
5 龚珍
6 熊时
7 王武
8 王一
9 王二
10 李四
11 赵武
12 孙泉
Name: name, dtype: object筛选
# 筛选出 “李” 姓氏的客户
li_list=list(filter(lambda x:re.findall('李.*',x),df1.name ))
li_list
['李尔', '李尔', '李四']
'''将名字列设置为列索引'''
df1.set_index(df1.name,inplace=True)
df1.index
Out:
Index(['张亦', '张亦', '李尔', '李尔', '赵兆', '龚珍', '熊时', '王武', '王一', '王二', '李四', '赵武',
'孙泉'],
dtype='object', name='name')
# 将名字列删除
df1.drop('name',axis=1,inplace=True)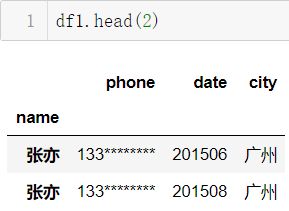
# 过滤掉重复的名字
li_Seri=pd.Series(li_list).unique()
li_Seri
Out:
array(['李尔', '李四'], dtype=object)筛选后的数据存入表B
# 使用筛选出的过滤后的名字来筛选整个字段的信息
B=df1.loc[li_Seri]
B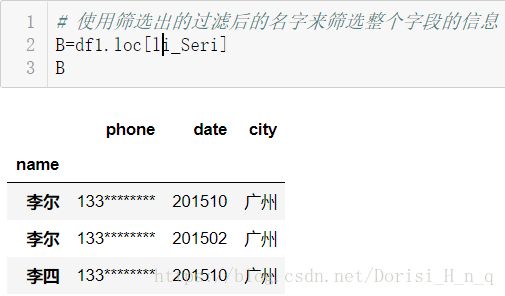
数据集 Table2 有变量:姓名、年龄,如下:Tb2
data2={'name':['张亦','李尔','赵兆','龚珍','熊时','王武','王一','王二','李四','赵武','孙泉'],
'age':[30,26,'.',70,20,19,45,'.',47,32,50],}
Tb2=DataFrame(data2)
Tb2
Tb2=Tb2[['name','age']]
Tb2
合并数据集A
C=pd.merge(A,Tb2)
C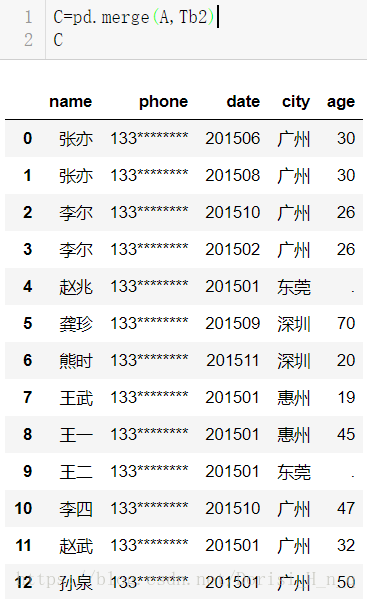
C_1=C.copy()
C_1给数据集排序sort_values(ascending=False:按降序排序,即日期小的排在后面)
C_1=C_1.sort_values(by='date',ascending=False)
C_1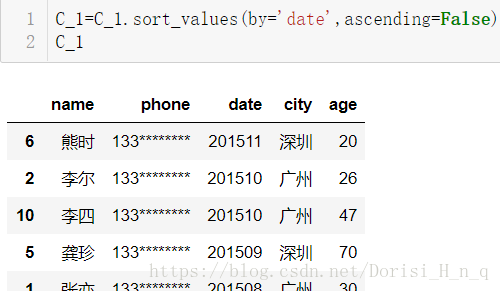
# 保留后一项,删除前一项重复数据
C_1.duplicated('name', keep='last')
Out:
6 False
2 True
10 False
5 False
1 True
0 False
3 False
4 False
7 False
8 False
9 False
11 False
12 False
dtype: bool
# 保留第一项,删除后一项重复数据
C_1.duplicated('name', keep='first')
Out:
6 False
2 False
10 False
5 False
1 False
0 True
3 True
4 False
7 False
8 False
9 False
11 False
12 False
dtype: boolC_1.drop_duplicates('name', keep='first',inplace=True)
C_1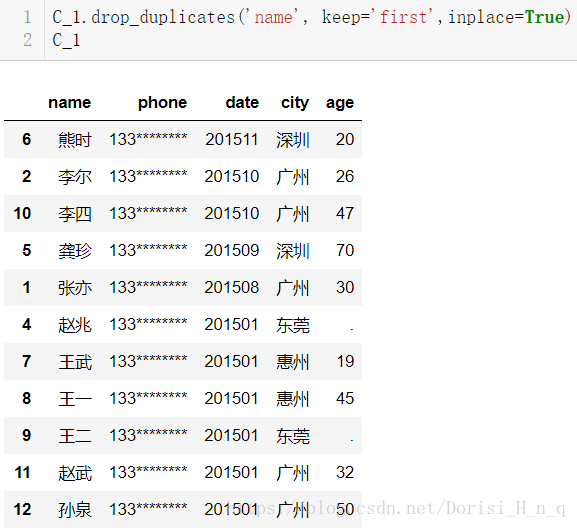
统一转化为string类型:apply(str)
# 统一转化为string类型
C_1.age=C_1.age.apply(str)
C_1.age
OUt:
6 20
2 26
10 47
1 30
5 70
4 .
7 19
8 45
9 .
11 32
12 50
Name: age, dtype: object求最大年龄
max(C_1.age)
Out: '70'拓展:reduce(lambda a,b:int(a)+int(b),C_1.age)
from functools import reduce
# 如果列中没有缺失值,可以使用该方法累加
reduce(lambda a,b:int(a)+int(b),C_1.age)
reduce(lambda a,b:int(a)+int(b),np.array([1,2,4]))
Out:7求平均年龄
sum=0
for i in C_1.age:
if i !='.':
# print(i)
sum+=int(i)
print(sum/C_1.age.size)
Out:
30.818181818181817
# 显示2位小数
a=30.818181818181817
print('%.2f'%a)
Out : 30.82替换'.'为np.nan
① 使用 replace
C_1.age.replace(to_replace='.',value=np.nan,inplace=True)
C_1② 使用 map
C_1.age=C_1.age.map(lambda x: np.nan if x =='.' else x)
C_1.age
Out:
6 20
2 26
10 47
1 30
5 70
4 NaN
7 19
8 45
9 NaN
11 32
12 50
Name: age, dtype: object统计缺失值
'''查看是否有缺失值,有则为True'''
C_1.age.isnull().any()
Out: True
# 统计数量
C_1.age.isnull().sum()
Out:2
空值处理:fillna/bfill/ffill/dropna
填充缺失值 or 删除缺失值
'''参数:value=None, method=None, axis=None, inplace=False, limit=None'''
C_1.age.fillna(value=0)
Out:
6 20
2 26
10 47
5 70
1 30
4 0
7 19
8 45
9 0
11 32
12 50
Name: age, dtype: object'''向前填充,参数:axis=None, inplace=False, limit=None, downcast=None'''
C_1.age.bfill()
Out:
6 20
2 26
10 47
5 70
1 30
4 19
7 19
8 45
9 32
11 32
12 50
Name: age, dtype: object'''向后填充,参数:axis=None, inplace=False, limit=None, downcast=None'''
C_1.age.ffill()
Out:
6 20
2 26
10 47
5 70
1 30
4 30
7 19
8 45
9 45
11 32
12 50
Name: age, dtype: object'''默认删除行记录,参数:axis=0, inplace=False, **kwargs'''
C_1.age.dropna()
Out:
6 20
2 26
10 47
5 70
1 30
7 19
8 45
11 32
12 50
Name: age, dtype: object