[论文阅读]Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
文章目录
- RPN( Region Proposal Networks)
- anchor
- anchor 设计解决多尺度问题
- anchor box与 ground truth 匹配机制
- 架构
- softmax判定foreground与background
- 边界框回归
- 对proposals进行bounding box regression
- Proposal Layer
- ROI pooling
- 损失函数
- 参考资料
RPN( Region Proposal Networks)
RPN的总体功能可以用论文的一句话来说明,
The RPN is thus a kind of fully conolutional network(FCN) and can be trained end-to-end specifically for the task for generating detection proposals
RPN是一个全卷积神经网络,可以针对检测提议生成任务进行端到端的培训。
![[论文阅读]Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks_第1张图片](http://img.e-com-net.com/image/info8/4c0526f2dc96433781396cba9a082cb6.jpg)
可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得foreground和background(检测目标是foreground),下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
anchor
anchor 设计解决多尺度问题
Our design of anchors presents a novel scheme for addressing multiple scales(and aspect ratios)
论文提到自己的anchor box可以解决多尺度问题,并且指出了当前两种解决多尺度问题方法的缺点(1)使用特征/图像金字塔,有效但比较耗时(2)在特征图上使用多尺度滑动窗口,通常两者一起使用
anchor box与 ground truth 匹配机制
负责检测物体的anchor匹配,两个原则
(1)和ground truth具有最高iou的anchor,两者匹配
(2)一个anchor只要和任意ground truth iou大于0.7就会匹配
两个原则可以看出来,一个ground truth可能会匹配多个anchor box
负责检测背景的anchor
(1)如果一个anchor和所有ground truth的iou都小于0.3,就会被打上检测北京标签
一个anchor即不检测物体,也不检测背景,则在训练过程中会被忽略
架构
![[论文阅读]Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks_第2张图片](http://img.e-com-net.com/image/info8/660ff127bdba4737b7d23d661c82bf55.jpg)
解释一下上图:
(1)论文中经过特征提取网络后其,Conv Layers中最后的conv5层num_output=256,所以每个点都有256d
(2)在con5后,做了33卷积,维度256不变,相当于每个点融合周围33的空间信息
(3)每个点都有k(默认是9)个anchor,每个anchor有输出foreground和background类别信息,所以每个点输出2k scores,每个anchor都有(x,y,w,h)四个偏移量,所以输出 4k coordinate
(4)补充一点,全部anchors拿去训练,因为负样本太多,导致会模型会偏向负样本,所以训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练,若果正样本不足128,补负样本直到满足mini-batch
It is possible to optimize for the loss functions of all anchors, but this will bias towards negative samples as they are dominate. Instead, we randomly sample 256 anchors in an image to compute the loss function of a mini-batch, where the sampled positive and negative anchors have a ratio of up to 1:1. If there are fewer than 128 positive samples in an image, we pad the mini-batch with negative ones
softmax判定foreground与background
![[论文阅读]Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks_第3张图片](http://img.e-com-net.com/image/info8/b2c84e4376e04ede89c046de44539f1d.jpg)
经过11 卷积,num_output是18,即现在尺度是wh18,18=29,正好体现我们上边讨论的每个点输出2k score
边界框回归
![[论文阅读]Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks_第4张图片](http://img.e-com-net.com/image/info8/f0a3c083b5d444ba871b013426040076.jpg)
上半部分是pred box与anchor box的偏移值,下半部分是anchor box与ground truth的偏移值
监督信号是Anchor与GT的差距 (t_x, t_y, t_w, t_h),即训练目标是:输入 Φ的情况下使网络输出与监督信号尽可能接近。
where x, y, w, and h denote the box’s center coordinates and its width and height. Variables x, xa, and x∗ are for the predicted box, anchor box, and groundtruth box respectively (likewise for y, w, h). This can be thought of as bounding-box regression from an anchor box to a nearby ground-truth box
对proposals进行bounding box regression
![[论文阅读]Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks_第5张图片](http://img.e-com-net.com/image/info8/9cd4ca907139410d8119721ff3da91cf.jpg)
经过11 卷积,num_outputs是36(49),即每个anchor预测4个偏移值
Proposal Layer
Proposal Layer负责综合所有
[ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] [d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)] [dx(A),dy(A),dw(A),dh(A)]
变换量和foreground anchors,计算出精准的proposal,送入后续RoI Pooling Layer。
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
1.生成anchors,利用 [ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] [d_{x}(A),d_{y}(A),d_{w}(A),d_{h}(A)] [dx(A),dy(A),dw(A),dh(A)]对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
2.按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
3.限定超出图像边界的foreground anchors为图像边界(防止后续roi pooling时proposal超出图像边界)
4.剔除非常小(width
6.再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
之后输出proposal=[x1, y1, x2, y2],注意,由于在第三步中将anchors映射回原图判断是否超出边界,所以这里输出的proposal是对应MxN输入图像尺度的,这点在后续网络中有用。
RPN总体流程:生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals
RPN的输入与输出也可以用论文的一句话来说明
A Region Proposal Network(RPN) takes an image(of any size) as input and outpus a set of rectangular object proposals,ecah with an objectness score.
ROI pooling
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "conv5_3"
bottom: "rois"
top: "pool5"
roi_pooling_param {
pooled_w: 7
pooled_h: 7
spatial_scale: 0.0625 # 1/16
}
}
由于proposal是对应 M × N M\times N M×N 尺度的,所以首先使用spatial_scale参数将其映射回$ (M/16) \times (N/16)$ 大小的feature map尺度;
再将每个proposal对应的feature map区域水平分为 p o o l e d _ w × p o o l e d _ h pooled\_w\times pooled\_h pooled_w×pooled_h 的网格;
对网格的每一份都进行max pooling处理。
这样处理后,即使大小不同的proposal输出结果都是 p o o l e d _ w × p o o l e d _ h pooled\_w \times pooled\_h pooled_w×pooled_h 固定大小,实现了固定长度输出
(这里就是上面文字描述的意思,对feature map分成固定的块,然后每一块儿进行最大池化,可保证经过roi pooling之后尺度就是我们最开始设定的块数,即配置文件中的7*7)
损失函数
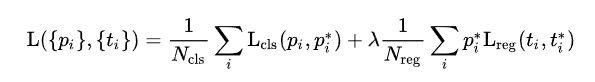
i表示anchor index, p i p_i pi表示predicted probability of anchor i being an object,即属于物体的概率,前景概率。 p i ∗ p_i^* pi∗是1,如果这个anchor负责检测物体,是0如果这个anchor负责检测背景。 t i t_i ti是一组向量,代表预测框的四个参数, t i ∗ t_i^* ti∗表示与这个anchor匹配的ground truth的四个参数量
分类损失cls就是softmax损失
回归损失这里用的更鲁棒的smooth L1损失
![[论文阅读]Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks_第6张图片](http://img.e-com-net.com/image/info8/3df275d970334fc9a3c4e4810be8bb17.jpg)
参考资料
- 一文读懂faster rcnn:https://zhuanlan.zhihu.com/p/31426458