Python 助力词频统计自动化
上周除了爬虫的问题,还尝试写了份词频统计的代码。最初听到关于词频的需求描述,有点懵。在了解其具体操作流程后发现:类似的需求可能涉及各行各业,但本质只是 Word 文档和 Excel 表格的自动化处理。今天借着这个实例,我们继续探究下 Python 在自动化处理上的魅力:
如上图所说,任务涉及了两份文件,一份 Word 文档,内含许多词汇表格:
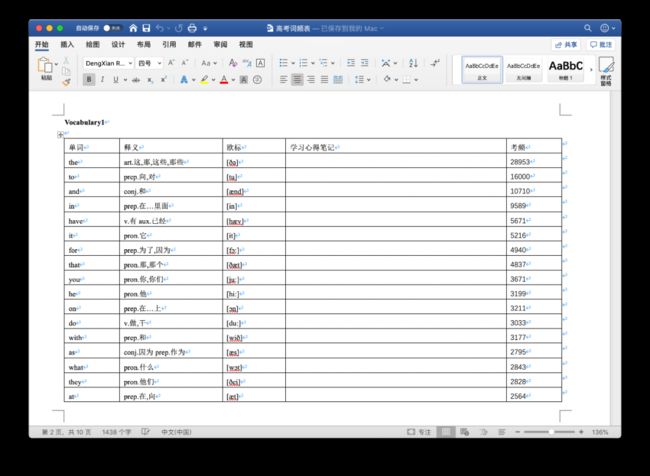
文档的表格中列出了不同单词的考频(高考频次),比如单词 the 考频 28953,这相当于我们的初始文件和数据。还有一份 Excel 表格,里面列着诸多单词要更新的频次数值:
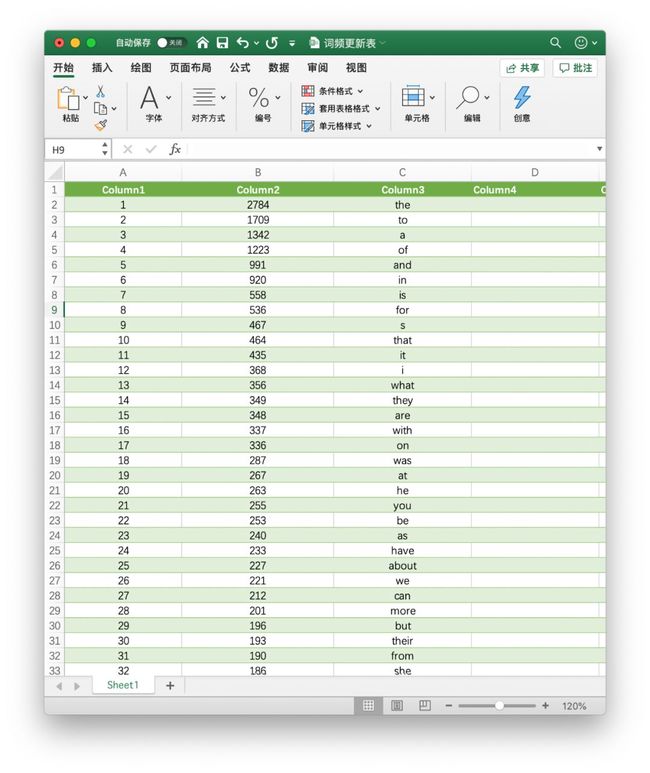
Excel 表格中 the 的频次在 B 列,数目为 2784。我们要实现的就是把 the 单词在 Excel 表格中对应的词频数更新到 Word 文档中 the 的考频中。即 2784 加上 28953 得出 31737,将其更新到 Word 文档中。人工操作的难点在于单词数量巨大,Excel 表格中有六千多条单词数据,Word 文档中所有的单词分布在一百多个不同的表格中,不仅耗时还极容易出错。
#1 设计思路
任务捋清楚了,那编码怎么设计呢?我们先大致定下思路:
1. 首先是读取 Word 文档中不同的表格,并将其中所有的单词和对应的考频提取出来;
2. 读取 Excel 表格中的数据,将单词和要更新的词频一一对应;
3. 遍历 Word 文档中每个单词,以单词为引在 Excel 表格的词库中检索相应次数,有数据就更新到 Word 文档相应位置。
那么要实现以上思路,除了读取 Excel 表格数据,比较关键的就是可以精准地读写 Word 文档中表格数据。
#2 编码实现
有了思路,我们直接尝试编码实现,这里我只保留了一小部分原文档和表格的单词数据用于代码演示。
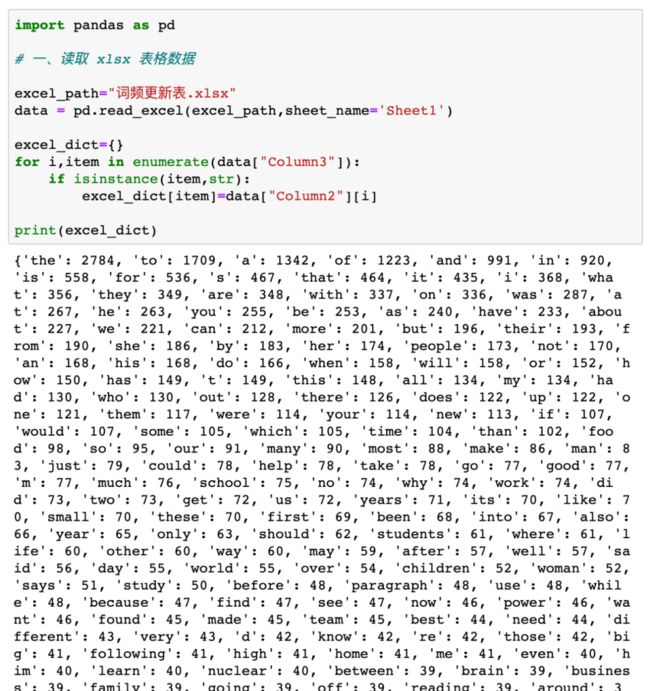
首先我们先从熟悉的 Excel 表格开始,依然是使用熟悉的 pandas 库:
import pandas as pd
# 读取 xlsx 表格数据
excel_path="词频更新表.xlsx"
data = pd.read_excel(excel_path,sheet_name='Sheet1')
# 为 Excel 表格中的单词建立个字典存数据
excel_dict={}
# data 是通过 pandas 库获取到的表格数据,data[列名] 即整列数据
# data["Column3"] 为 Column3 对应的单词
for i,item in enumerate(data["Column3"]):
if isinstance(item,str):
# Column2 对应的是词频,将其存入字典中
excel_dict[item]=data["Column2"][i]
# 打印看下字典情况
print(excel_dict)
运行代码,可以看到 Excel 中的单词词频被存到了字典中:
读取完 Excel 表格,接下来就是 Word 文档了,经过一番搜索,我选用 python-docx 库:
# python-docx 库
https://python-docx.readthedocs.io/en/latest/#
要注意的是,安装时命令是 pip install python-docx,代码中导入时是 docx,我们代码中主要是提取文档中的表格,所以使用了该库中的 Document 函数:
from docx import Document
# 读取 word 文档
path="高考词频表.docx"
document = Document(path)
# 读取文档中的所有表格
tables = document.tables
# 获取所有表格数
table_num = len(tables)
# 为所有单词建立对应的词频字典
f_dict = {}
# 将获取到的表格逐个打印
for table_index in range(table_num):
table = tables[table_index]
print(table)
在文档中,我只选用了 5 个表格,让我们运行代码来看看是否输出五个表格:
没问题,接下来我们就是针对这每个表格来做文章了,我们要通过其相关的函数来定位到表格中具体的行列位置来提取单词和考频数据:
# 接着上面的代码继续写
for table_index in range(table_num):
table = tables[table_index]
# print(table) 我们将打印表格改为下面的表格数据处理
# table.rows 是该表格中所有行对象
for i in range(1,len(table.rows)):
# 上文 Word 文档截图可以看到,第 0 列是单词文本
word_text = table.cell(i, 0).text
# 第 4 列是考频
frequency = table.cell(i, 4).text
# 将单词和考频存到字典中
f_dict[word_text] = frequency
# 有的单词考频为空,这里过滤一下
if frequency!="":
#print(f"word中{word_text}的频率为{frequency}")
# 由 Excel 表格中提取对应的单词词频数据,转化为整数
update_num = int(excel_dict.get(word_text,0))
#print(f"excel中{word_text}的频率为{update_num}")
# 将数目更新即添加到 Word 文档中单词字典中
count = int(frequency)+update_num
# 除了更新字典,再把更新后的数字写入 Word 文档表格中的相应位置
table.cell(i, 4).text = str(count)
#print(f"更新完,词频为{count}")
# 打印进度
print(f"已完成 {table_index+1}/{table_num+1}")
print("更新词频完成!")
# 最终将修改后的 document 文件存成新的 docx 文档
document.save("result.docx")
我们通过 print 语句添加了一个进度的打印,方便我们掌握进程,运行代码,可以看到如下提示:

最后的提示语标志着代码运行完毕,我们再来看下最终生成的 result.docx 结果文档:
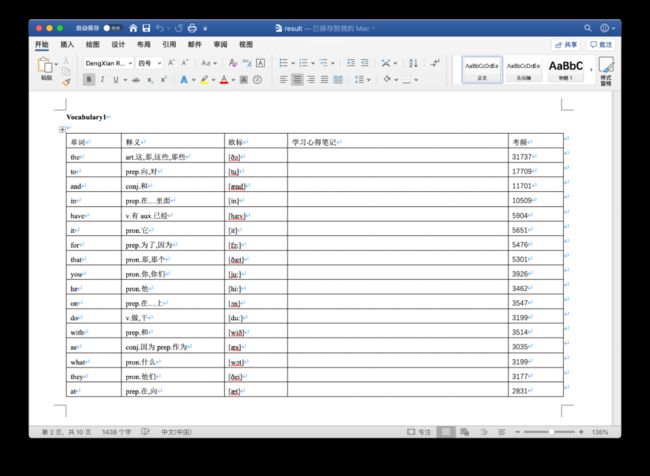
我们看 the 的考频,正是之前我们计算叠加后的 31737。在随机抽查下 to 单词,最初的 Word 文档中是 16000,Excel 表格中是 1709,现在是 17709。很好,任务完成,收工!
#3 过程回顾
整个过程还算中规中矩、也比较顺利。可能会出问题的地方是对于 python-docx 库的使用,因为通过其 Document 拿到的表格都是对象,刚接触并不知道使用其中的什么函数方法、以及怎么取数据和写数据。对此我的看法是,根据我代码中写的,就直接拿来用,看不明白的就 print 出来看看具体是什么内容。当这些掌握了之后,再去搜 python-docx 相关的文章、文档来研究。
因为我写代码初衷是帮朋友来解决实际需求,所以写代码过程中对库和方法的使用要么是之前熟悉直接用,要么就是针对具体需求搜索看别人如何实现的,然后应用到代码中来。更好的方式是,这么应用完之后去探究下相关的库文档来拓展延伸。在这方面我还没有养成好习惯,在这里也立个 flag 自我监督下:明天周五整理一篇关于 python-docx 库的文章。
公众号后台回复 单词统计 可以获取 GitHub 代码和素材下载链接。
以上,感谢你的阅读~