Photo-Realistic Single Image Super-Resolution Using a Generative AdversarialNetwork 阅读笔记
Photo-Realistic Single Image Super-Resolution Using a Generative AdversarialNetwork
论文链接:https://arxiv.org/abs/1609.04802
超分辨率领域——SRGAN
摘要
目前采用更快更深的卷积神经网络的单幅图像超分辨率的准确性和速度有了突破,但是一个核心问题仍然尚未解决: 当放大因子较大下的超分辨时,如何恢复细小的纹理细节,恢复更多的高频信息?基于优化的超分辨率方法主要取决于目标函数的选择。最近的工作主要集中在最小化均方(MSE)重构误差,结果评价有较高的峰值信噪比,但是往往缺乏高频细节和感官满意度,无法达到超分辨率的预期逼真度.
为什么使用MSE会出现这种情况?
(MSE以像素空间的比较为参考,一个低分辨率的图像块可能对应高分辨率中的多个图像块,而GAN只有唯一的对应,这样,通过MSE为目标函数的处理方式会将多个高分辨率的图像块进行平均,所以最终得到的结果有一些模糊。)
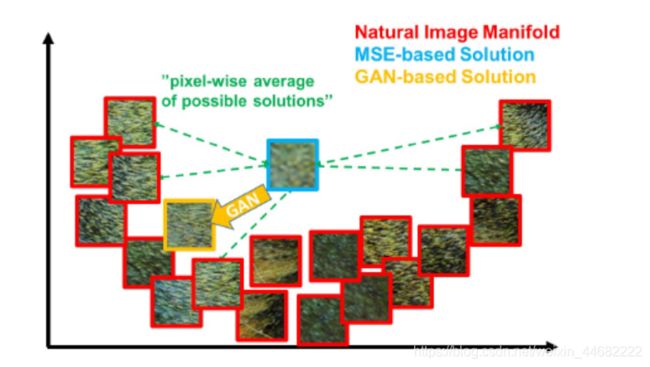
作者在论文中提到峰值信噪比不能作为评价超分辨率的标准,该指标和图像带给人的视觉感受是不一致的。论文提出SRGAN和感知损失函数,包含了一个adversarial loss(对抗损失)和一个content loss()。对抗损失用一个判别网络将我们的方案推向自然图像manifold,判别网络被训练来区分生成的超分辨率图像和原始图像。由于perceptual similarity感知相似,而不是像素空间 similarity类似,我们使用一个content loss.我们的深度残差网络可以从严重下采样图像中恢复实感图像纹理。在SRGAN中,考虑到PSNR不能作为评价超分辨的标准,所以作者采用了MOS进行评价;扩展平均意见得分(MOS)测试,显示使用SRGAN在视觉质量上有显著的提升.用SRGAN获得的MOS得分比那些用其他的先进方法相比,更接近原始高分辨率图像的得分。
关于PSNR指标
传统的指标来衡量超分辨率的是PSNR和SSIM,这两个指标和人类的视觉感受没有太大的关系。PSNR和SSIM仅仅依赖于像素间低层次的差别,PSNR是相当于逐像素差的,所以用PSNR衡量的模型训练过程是让逐像素损失最小化。
链接:https://www.jianshu.com/p/b728752a70e9
网络结构如下: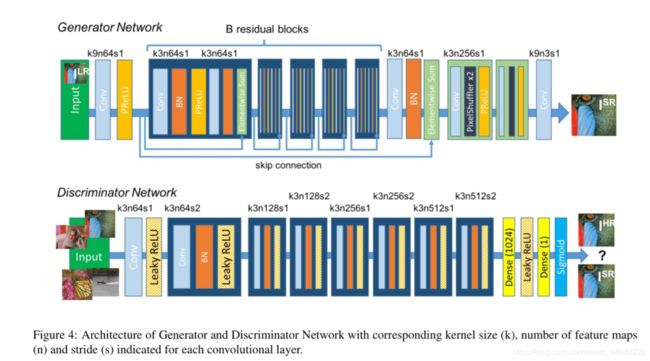 1.生成网络
1.生成网络
论文中的生成网络和SRResNet结构是相似
 对网络的各部分进行简单的介绍:
对网络的各部分进行简单的介绍:
输入和输出的卷积层:实现数据的调整和增强
PReLU:是LeakyReLU激活函数的一个变体,其负值部分的斜率是根据数据的学习而定的,而不是预先设定好的。
模块B:深度残差模块,实现了高效提取特征,并在一定程度上削弱了图像的噪点,由以下多个残差块组成

深度残差模块中,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数
两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。
亚像素卷积层
作用:对特征图的尺寸进行放大,又称为像素清洗(pixel shuffle)。
输入大小为HW的低分辨率图像,经过亚像素卷积层生成大小为rHrW的高分辨率图像。r为上采样因子,也是图像的扩大倍率。本论文中有两个2x的亚像素卷积层,大小扩大4倍。
2.判别网络
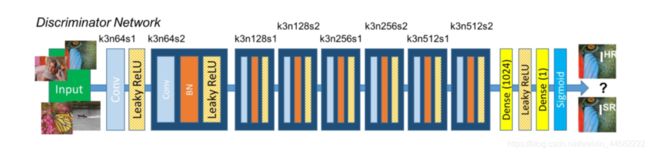 整个网络共有8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小
整个网络共有8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小
选取激活函数为LeakyReLU(0.2)(确保输入的特征信息完整?),最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。
LeakyReLU激活函数

感知损失函数(基于感知相关特征,而不是传统的MSE)
 内容损失函数
内容损失函数
传统的损失函数是以像素为单位的MSE方法,大部分的超分辨率问题采用MSE作为优化目标。考虑到MSE丢失高频信息。
如下:
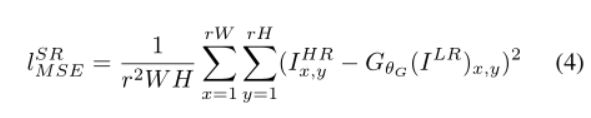 本论文中基于预训练的19层VGG网络的ReLU激活层,定义损失函数
本论文中基于预训练的19层VGG网络的ReLU激活层,定义损失函数
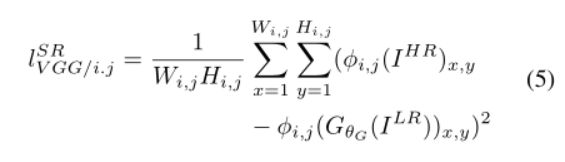 ∅i,j表示在VGG19网络中,第i个最大池化层后面的第j个卷积层(在激活层之后)所提取的特征图,VGG loss是重构图像和参考图像的特征图的欧式距离,上式中的Wi,jWi,j和Hi,jHi,j表示特征图的维度。
∅i,j表示在VGG19网络中,第i个最大池化层后面的第j个卷积层(在激活层之后)所提取的特征图,VGG loss是重构图像和参考图像的特征图的欧式距离,上式中的Wi,jWi,j和Hi,jHi,j表示特征图的维度。
内容损失计算方式:
- 通过SRResNet重建出高清图像SR;
- 通过truncated_vgg19模型对原始高清图像HR和重建出的高清图像SR分别进行计算,得到两幅图像对应的特征图H_fea和SR_fea;
- 计算H_fea和SR_fea的MSE值;
从上述计算方式上看出,原来的计算方式是直接计算H和SR的MSE值,而改用新的内容损失后只需要利用truncated_vgg19模型对图像多作一次推理得到特征图,再在特征图上进行计算。
对抗损失函数
 生成的图像越接近于原始真实的图像,下面这项越大,损失函数越小;
生成的图像越接近于原始真实的图像,下面这项越大,损失函数越小;
![]()
方法
输入到生成网络的低分辨率图像:高分辨率图像先加高斯噪声,然后经过一个步长为r的下采样得到的
原始真实的高分辨率图像的大小为:rWxrHxC
经过下采样的低分辨率图像大小为:WxHxC
通过SRResNet生成网络的亚像素卷积层的作用,使得生成的高分辨率图像的大小再次变为:rWxrHxC
生成网络采用的前馈CNN记作G
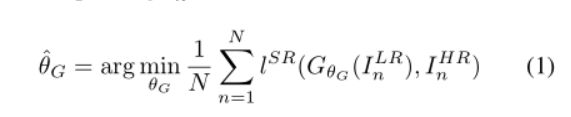 这里的lSR就是前面提到的感知损失函数
这里的lSR就是前面提到的感知损失函数
和标准的GAN一样,模型需要训练下面的式子:
 上面的公式是最大最小优化问题,分别对应两个优化问题。先优化网络判别网络D,再优化生成网络G(交替优化过程)
上面的公式是最大最小优化问题,分别对应两个优化问题。先优化网络判别网络D,再优化生成网络G(交替优化过程)
实验
实验:
数据集是SET5、SET14和BSD100三个图像超分辨领域的基准数据集,低分辨率和高分辨率之间是4倍的差距,采用PSNR和SSIM作为性能衡量标准。训练的时候是用的ImageNet数据集下采样,用adam优化。
作者在衡量超分辨性能时提出了一个新的标准MOS,就是采用人作为标准,作者要求26个用户对超分辨的图像进行打分,1-5分,越高性能越好。在三个基准数据集的图像进行打分,结果如下:
各个超分辨方法所得到的PSNR、SSIM和MOS的最终结果如下表,本文的生成网络部分SRResNet得到了最高的指标,虽然SRGAN的PANR和SSIM并不是最高,但是他得到了最高的MOS值,这意味着PSNR和SSIM不能单独作为超分辨的衡量标准。
作者针对内容损失函数也做了几组对比实验,分别在MSE、VGG22和VGG54的loss函数进行实验,结果如下,虽然MSE的PSNR值更高,但是他在图像的视觉感知上效果并不好,文理细节处理不够精细,这又一次证明了作者对PSNR的观点。
通过以上实验看出,用均方误差优化SRResNet,能够得到具有很高的峰值信噪比的结果。在训练好的VGG模型的高层特征上计算感知损失来优化SRGAN,并结合SRGAN的判别网络,能够得到峰值信噪比虽然不是最高,但是具有逼真视觉效果的结果,基于VGG模型高层特征比基于VGG模型低层特征的内容损失能生成更好的纹理细节
参考:
https://www.jianshu.com/p/cc3acb3e3c3a
https://blog.csdn.net/qq_28168421/article/details/80993864
https://blog.csdn.net/qianbin3200896/article/details/104181552
https://www.cnblogs.com/wangxiaocvpr/p/5989802.html?utm_source=itdadao&utm_medium=referral