Spark 大数据中文分词统计(二) Java语言实现分词统计
上一篇文章中完成了Windows环境下Spark开发环境的搭建,这一篇来谈一下使用Java语言,基于纯Java
语言、使用MapReduce模式以及Spark框架进行中文分词统计的编程实践。
进行中文处理,中文分词是首先要考虑的。这里选用了IKAnalyzer,因为原来做论文时用过,接口简单,
使用方便,而且开源,也很好设定。
下载地址为:http://git.oschina.net/wltea/IK-Analyzer-2012FF
当然也可以采用其他的中文分词组件。
在Scala IDE上创建好的工程结构如下:
程序运行的结果如下:
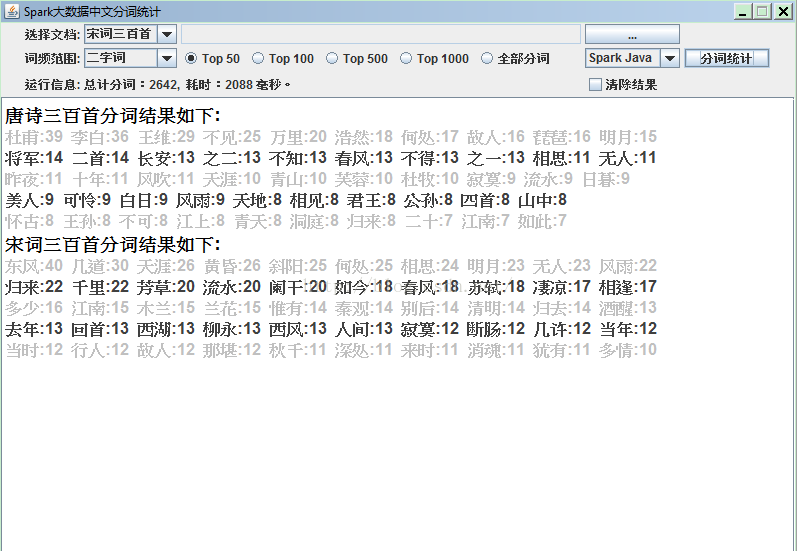
我们可以看到,唐诗宋词中,出现最多的两字词有 何处,相思,明月,春风,无人,天涯,流水,江南等等。可见,千百年后,
穿越时空而触动我们心灵的,没有一个是当时的人们孜孜以求的。所以,我们今天念念不忘的身外之物,耿耿于怀的内心遗憾,其实
都不过是暂时的虚幻,随风而逝,不留痕迹,又何必太在意呢?
工程源码已经上传到CSDN:http://download.csdn.net/detail/yangdanbo1975/9602164
当然,要运行工程文件的话,不要忘记了添加必须的类库:(如果你按上一篇的步骤完成安装的话,所有的库本地都有了)

程序中,总共采用Pure Java,MapReduce和Spark 框架(Java语言)三种方式实现了对唐诗三百首,宋词三百首,论语,孟子,老子,庄子
的中文分词统计,可以选词长,也可选TopN,当然也可以通过文件浏览选择其他的文件来源:

程序的主运行文件是WordCounter,右键单击可以Java Application运行。
第一种方法是使用Pure Java语言实现中文分词的统计。主要的方法是WordCounter中的 pureJavaWordCount() :
private void pureJavaWordCount() {
// 未选择文档,使用下拉框预设文档
Map
if (docField.getText().isEmpty()) {
wordCount = getWordCount(docBox.getSelectedItem().toString(),
false, lengthsBox.getSelectedIndex());
} else {
wordCount = getWordCount(docField.getText(), true,
lengthsBox.getSelectedIndex());
}
// 显示分词结果
if (wordCount == null) {
JOptionPane.showMessageDialog(null, "分词统计结果为空!\n请检查程序或重新选择文档!");
} else {
if (rdoTop50.isSelected()) {
showWordCount(wordCount, 50);
} else if (rdoTop100.isSelected()) {
showWordCount(wordCount, 100);
} else if (rdoTop500.isSelected()) {
showWordCount(wordCount, 500);
} else if (rdoTop1000.isSelected()) {
showWordCount(wordCount, 1000);
} else if (rdoAll.isSelected()) {
showWordCount(wordCount, 0);
}
}
}
代码很简单,唯一值得一提的是,参照网络上的例子,写了一泛型的SortableMap
按key和value升序或降序排序的功能,使最终输出的分词统计结果可以按词频排序:
SortableMap
Map
第二种方法是使用MapReduce模式,进行中文分词统计及按词频排序输出。
主要的Class是HadoopWordCount,和网上的大多数例子是一样的,不同之处在于在TokenizerMapper类的
Map方法中加入了中文分词的逻辑:
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString().toLowerCase(); // 全部转为小写字母
/*
* line = line.replaceAll(pattern, " "); // 将非0-9, a-z, A-Z的字符替换为空格
* StringTokenizer itr = new StringTokenizer(line); while
* (itr.hasMoreTokens()) { word.set(itr.nextToken());
* context.write(word, one); }
*/
try {
InputStream is = new ByteArrayInputStream(
line.getBytes("UTF-8"));
IKSegmenter seg = new IKSegmenter(new InputStreamReader(is), false);
Lexeme lex = seg.next();
while (lex != null) {
String text = lex.getLexemeText();
word.set(text);
context.write(word, one);
// output.collect(word, one);
lex = seg.next();
}
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
在IntSumReducer类的reduce方法的最后,把分词统计的结果保存到全局变量中:
//保存结果
totalWords.put(key.toString(), Integer.valueOf(sum));
因为当从WordCounter的Java GUI界面调用HadoopWordCount功能时,需要使用全局变量返回结果。
第一个MapReduce job完成后,输出结果在C:\\hadoop目录中。
最后就是新增了一个IntWritableDecreasingComparator,在Map Reduce的第一个Job完成之后,再进行一个
sortJob,以前面的C:\\hadoop作为input,先用hadoop库提供的InverseMapper交换Map中的key和value,然后在
sortJob中设定:
sortJob.setSortComparatorClass(IntWritableDecreasingComparator.class);
实现了按词频排序的结果输出。这是输出的结果是放在C:\\hadoopsort目录下。
本来我想再增加一个RestoreJob,把key和value在交换回来,写入文件。但是由于对Hadoop不熟悉,而
InverseMapper只能实现key和value交换,并不能实现value和key交换,自己有没有能力重写一个,所以只能放弃了。
HadoopWordCount有两种运行方式,单独main方法命令行方式运行时,会生成输出文件夹;当从WordCounter
中的入口方法:hadoopWordCount() 中调用的,会输出分词结果到GUI,这时对应的输出文件夹没有输出。
第三种方法 是使用Spark 框架,完成中文分词统计功能,实现类为SparkWordCount。
基本方法和网上的大多数例子没有差别,只是增加了一个getSplitWords 的方法,替换掉原来的简单split:
/**
* 4、将行文本内容拆分为多个单词
* lines调用flatMap这个transformation算子(参数类型是FlatMapFunction接口实现类)
* 返回每一行的每个单词
* 加入了中文分词的功能,调用分词后的list结果
*/
JavaRDD
private static final long serialVersionUID = -3243665984299496473L;
@Override
public Iterable
//return Arrays.asList(line.split("\t"));
return getSplitWords(line);
}
});
再就是增加了一个排序,先交换key和value,再按value排序,最后再交换回来:
public JavaPairRDD
//added by Dumbbell Yang at 2016-08-03
//加入按词频排序功能
//先把key和value交换,然后按sortByKey,最后再交换回去
JavaPairRDD
private static final long serialVersionUID = -7879847028195817508L;
@Override
public Tuple2
return new Tuple2
}
});
//降序
pairs2 = pairs2.sortByKey(isAsc);
//再次交换key和value
wordCount = pairs2.mapToPair(new PairFunction
private static final long serialVersionUID = -7879847028195817509L;
@Override
public Tuple2
return new Tuple2
}
});
return wordCount;
}
要注意的是,开始的conf中要设置为conf.setMaster("local");设定为local standalone模式启动spark job。
SparkWordCount同样有两种方式调用,一种是用main方法,在命令行运行,结果会输出到控制台;另外一种
是从WordCounter中的private void sparkJavaWordCount() 方法进入,分词统计结果会显示在GUI界面上。
上面就是采用Java语言实现的Spark中文分词统计功能。
下一篇,将会采用Scala语言实现Spark中文分词统计。