计算机视觉——图像检索与识别
目录
Bag-of-words models模型
Bag-of-words模型在计算机视觉的应用
1、特征提取和描述
2、构建视觉词典
3、单词表的中词汇表示图像
Bag-of-words模型应用三步
Bag of features: 图像检索
Bag of features: 大规模图像检索/匹配
Bag of features: 图像检索流程
代码实现
结果分析
Bag-of-words models模型
Bag-of-words词袋模型最初被用在信息检索领域,对于一篇文档来说,假定不考虑文档内的词的顺序关系和语法,只考虑该文档是否出现过这个单词。假设有5类主题,我们的任务是来了一篇文档,判断它属于哪个主题。在训练集中,我们有若干篇文档,它们的主题类型是已知的。我们从中选出一些文档,每篇文档内有一些词,我们利用这些词来构建词袋。我们的词袋可以是这种形式:{‘watch’,'sports','phone','like','roman',……},然后每篇文档都可以转化为以各个单词作为横坐标,以单词出现的次数为纵坐标的直方图,如下图所示,之后再进行归一化,将每个词出现的频数作为文档的特征。
近几年,在图像领域,使用Bag-of-words方法也是取得了较好的结果。如果说文档对应一幅图像的话,那么文档内的词就是一个图像块的特征向量。一篇文档有若干个词构成,同样的,一幅图像由若干个图像块构成,而特征向量是图像块的一种表达方式。我们求得N幅图像中的若干个图像块的特征向量,然后用k-means算法把它们聚成k类,这样我们的词袋里就有k个词,然后来了一幅图像,看它包含哪些词,包含单词A,就把单词A的频数加1。最后归一化,得到这幅图像的BoW表示,假如k=4,每幅图像有8个小块(patch),那么结果可能是这样的:[2,0,4,2],归一化之后为[0.25,0,0.5,0.25]。
Bag-of-words模型在计算机视觉的应用
计算机视觉领域的研究者们尝试将同样的思想应用到图像处理和识别领域,建立了由文本处理技术向图像领域的过渡。将文本分类问题与图像分类问题相比较,会发现这样的问题,对于文本来讲,文本是由单词组成的,因此提取关键词的过程也是顺理成章,没有任何歧义或者限制。但对于图像来讲,如何定义图像的“单词”,则是需要首先解决的问题之一。研究者们通过对 BoW 模型进行研究和探索,提出了采用 K-means 聚类方法对所提取的大量特征进行无监督聚类,将具有相似性较强的特征归入到一个聚类类别里,定义每个聚类的中心即为图像的“单词”,聚类类别的数量即为整个视觉词典的大小。这样,每个图像就可以由一系列具有代表性的视觉单词来表示,如图1所示。
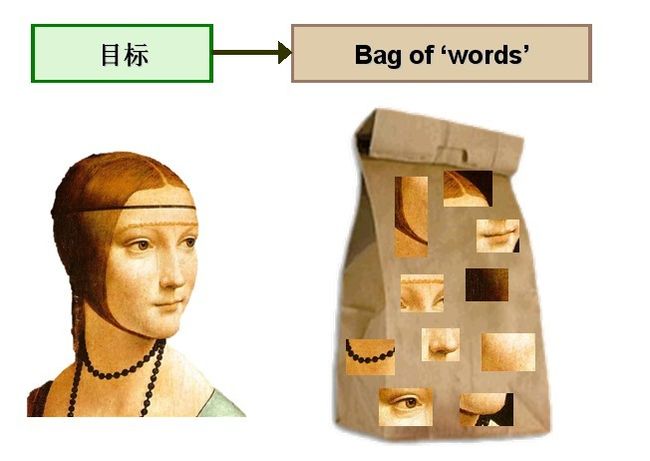
图1
在得到每类图像的视觉单词袋表示之后,便可以应用这些视觉单词来构造视觉词典,然后对待分类图像进行同样方法的特征提取和描述,最后将这些特征对应到视觉词典库中进行匹配,去寻找每个特征所对应的最相似的视觉单词,得到直方图统计表示,然后应用分类器进行分类。这样就将应用于文档处理的BoW模型思想成功地移植到了图像处理领域。斯坦福大学的 Li Feifei 等人在此方面做出了突出的贡献。
在应用BoW模型来表述图像时,图像被看作是文档,而图像中的关键特征被看作为“单词”,其应用于图像分类时主要包括三个步骤:
- 特征提取和描述;
- 视觉词典构造;
- 单词表的中词汇表示图像。
1、特征提取和描述
特征提取和描述的主要任务是从图像中抽取具有代表性的局部特征。要求这些特征具有较强的可区分性,能最大限度地与其他物体进行区分。此外,还要求被提取的特征具有较好的稳定性,此类特征经常存在于图像的高对比度区域,例如物体边缘与角点。
BoW模型中的一些典型图像特征的提取和描述方法:
(1)规则网格(Regular Grid)方法是特征提取的最简单且有效的方法之一,该方法将图像应用均匀网格进行划分,从而得到一些图像的局部区域特征,此方法在应用于自然场景分类时收到了良好的效果。图2给出了利用规则网格方法得到的特征提取结果。

图2
采用规则网格法的优点在于:
<1> 可以人为地设定网格的划分级别,得到想要的特征数目;
<2> 在划分过程中可以对一些特征进行精确的定位;
<3> 可以充分利用图像的数据信息,最大限度的做到信息的完整性。然而该方法也存在一定的缺点,例如引入了大量的冗余(背景)信息,而降低了对象本身所提供的有用信息的价值。
(2) 兴趣点检测方法;兴趣点检测子和兴趣区域检测子的实现方法都是通过数学计算,去抽取满足一定数学条件的特征点或者区域,常用的检测子有edge-laplace、harris-laplace、hessian-laplace、harris-affine、hessian-affine、MSER、salient regions实际上,针对具体任务不同以及应用的数据库不同,最佳检测子的选择也很不相同。
2、构建视觉词典
利用聚类算法(如:K-Means算法)对步骤1提取的特征描述子构造单词表(词典),特征描述子分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低,将词义相近的词汇合并,作为单词表中的基础词汇,聚类类别的数量K即为整个视觉词典的大小基础词汇的个数。
3、单词表的中词汇表示图像
从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K维数值向量。

图3 从图像中提取出相互独立的视觉词汇
通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
而SIFT算法是提取图像中局部不变特征的应用最广泛的算法,因此我们可以用SIFT算法从图像中提取不变特征点,作为视觉词汇,并构造单词表,用单词表中的单词表示一幅图像。
Bag-of-words模型应用三步
我们通过上述图像展示如何通过Bag-of-words模型,将图像表示成数值向量。现在有三个目标类,分别是人脸、自行车和吉他。
第一步是利用SIFT算法,从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起,如下图4所示:

图4 从每类图像中提取视觉词汇
第二步是利用K-Means算法构造单词表。
K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为4,那么单词表的构造过程如下图5所示:
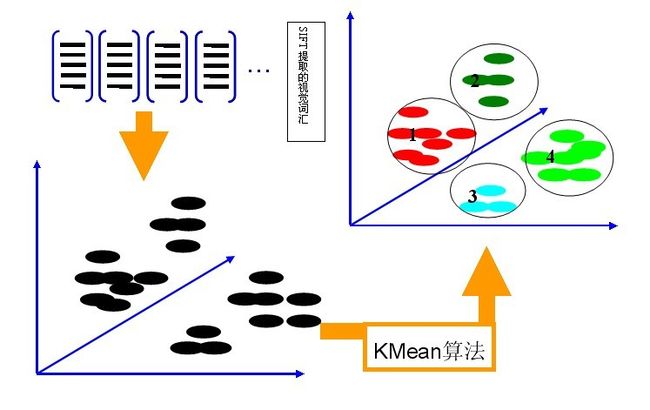
图5 利用K-Means算法构造单词表
K-means 聚类算法:
首先最小化每个特征  与其相对应的聚类中心
与其相对应的聚类中心 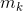 之间的欧氏距离
之间的欧氏距离
![]()
算法流程:
随机初始化 K 个聚类中心
重复下述步骤直至算法收敛:
对应每个特征,根据距离关系赋值给某个中心/类别
对每个类别,根据其对应的特征集重新计算聚类中心
第三步是利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。请看下图6:

图6 每幅图像的直方图表示
上图6中,我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇表中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉单词,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示(我们假定存在误差,实际情况亦不外如此):
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个词典,词典中包含4个视觉单词,即Dictionary = {1:”自行车”, 2. “人脸”, 3. “吉他”, 4. “人脸类”},最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数画成了上面对应的直方图。
需要说明的是,以上过程只是针对三个目标类非常简单的一个示例,实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,并且目标类数目越多,对应的K值也越大,一般情况下,K的取值在几百到上千,在这里取K=4仅仅是为了方便说明。
下面,我们再来总结一下如何利用Bag-of-words模型将一幅图像表示成为数值向量:
-
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点;
-
第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表;
-
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量。
Bag of features: 图像检索
- 给定输入图像的 BOW 直方图,在数据库中查找 K 个最近邻的图像
- 对于图像分类问题,可以根据这 K 个近邻图像的分类标签,投票获得分类结果
- 当训练数据足以表述所有图像的时候,检索/分类效果良好
图 7
参数设置:
- 视觉单词数量(K-means算法获取的聚类中心)一般为 K=3000~10000. 即图像整体描述的直方图维度为 3000~10000。
- 求解近邻的方法一般采用L2-范数:即 Euclidean 距离.
- 目前普适的视觉单词采用 Lowe 的SIFT特征描述子. 特征 点检测采用 DOG (Difference of Gaussians).
Bag of features: 大规模图像检索/匹配
在将图像检索到对象实例的大型数据库中,大量的单词模型非常有用。
建立数据库:
- 从数据库图像中提取特征
- 用kmeans学习词汇(典型的k:100000)
- 计算每个单词的权重
- 创建一个反向文件映射词——图像
单词权重:
- 在文本检索中,不同单词对文本检索的贡 献有差异。
the, and, or vs. cow, AT&T, Cher
- 一个词出现在文档中的比例越大,它对匹配的用处就越小。
单词的TF-IDF权重:
- 我们不计算规则的柱状图距离,而是将每个单词的倒数文档频率加权。
- 字的反文档频率(IDF)
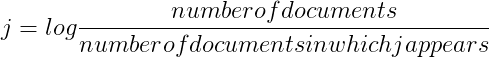
- 计算图像 I 中 j 的值:
I 中 j 的词频 * j 的反文档频率
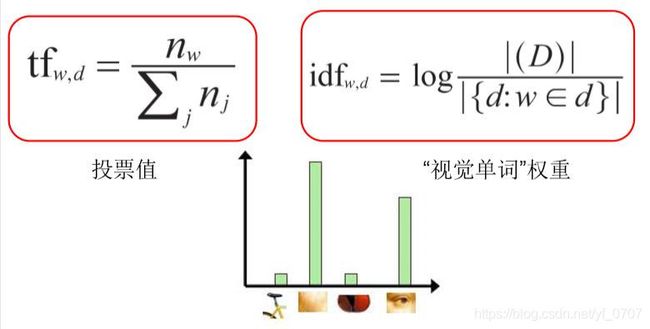
图 8
倒排表(Inverted file):
- 一般把每个图像都有大约1000个特征
- 如果我们有大约10000个视觉单词,则每个柱状图都非常稀疏(大部分是零)
- 倒排文件——从单词到文档的映射
- 只考虑其容器与查询图像重叠的数据库图像,可以快速使用反转文件计算新图像与数据库中所有图像之间的相似性
Bag of features: 图像检索流程
- 特征提取
- 学习“视觉词典(Visual vocabulary)”
- 针对输入特征集,根据视觉词典进行量化
- 把输入图像,根据TF-IdF转化成视觉单词(Visual words)的频率直方图
- 构造特征到图像的到排表,通过倒排表快速索引相关图像
- 根据索引结果进行直方图匹配
代码实现
生成代码所需要的模型-视觉词汇
在索引图像前我们需要建立一个数据库。这里,对图像进行索引就是从这些图像中提取描述子,利用词汇把描述子转换为视觉单词,并保存视觉单词及视觉图像的直方图。从而可以利用图像对数据库进行查询,并返回相似的图像作为搜索结果。
addImage.py:
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
cocabulary.py:
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
#保存词汇
# saving vocabulary
with open('first1000/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print ('vocabulary is:', voc.name, voc.nbr_words)
查看图像:
reranking.py:
# -*- coding: utf-8 -*-
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 0
nbr_results = 20
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print ('top matches (regular):', res_reg)
# load image features for query image
#载入查询图像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# load image features for result
#载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:8]) #常规查询
imagesearch.plot_results(src,res_geom[:8]) #重排后的结果运行结果:
![]()


test_candidates.py:
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
f = open('first1000/vocabulary.pkl', 'rb')
voc = pickle.load(f)
f.close()
src = imagesearch.Searcher('testImaAdd.db',voc)
locs,descr = sift.read_features_from_file(featlist[0])
iw = voc.project(descr)
print ('ask using a histogram...')
print (src.candidates_from_histogram(iw)[:10])
src = imagesearch.Searcher('testImaAdd.db',voc)
print ('try a query...')
nbr_results = 12
res = [w[1] for w in src.query(imlist[0])[:nbr_results]]
imagesearch.plot_results(src,res)
运行结果:
![]()

结果分析
从结果不难看到,与输入图片的拍摄位置(都在地毯上),纹理相近,形状相似(都是书,不同角度),颜色相近。
证明视觉词汇可能主要是从这三个方面进行匹配。当然,检索出的图像还存在一定的差异,提高检索准确率了这是我们进一步需要解决的问题。
此外,我们还了解了图像检索的一些问题:
- 使用k-means聚类,除了其K和初始聚类中心选择的问题外,对于海量数据,输入矩阵的巨大将使得内存溢出及效率低下。有方法是在海量图片中抽取部分训练集分类,使用朴素贝叶斯分类的方法对图库中其余图片进行自动分类。另外,由于图片爬虫在不断更新后台图像集,重新聚类的代价显而易见。
- 字典大小的选择也是问题,字典过大,单词缺乏一般性,对噪声敏感,计算量大,关键是图象投影后的维数高;字典太小,单词区分性能差,对相似的目标特征无法表示
- 相似性测度函数用来将图象特征分类到单词本的对应单词上,其涉及线型核,塌方距离测度核,直方图交叉核等的选择。
不足之处:
- Kmeans聚类时间长
- 词袋表征特征的过程其实牵涉到量化的过程,这其实损失了特征的精度。
- 检索模块设计的太粗糙,速度太慢