web爬虫讲解—Scrapy框架爬虫—Scrapy使用
xpath表达式
//x 表示向下查找n层指定标签,如://div 表示查找所有div标签
/x 表示向下查找一层指定的标签
/@x 表示查找指定属性的值,可以连缀如:@id @src
[@属性名称=“属性值”]表示查找指定属性等于指定值的标签,可以连缀 ,如查找class名称等于指定名称的标签
/text() 获取标签文本类容
[x] 通过索引获取集合里的指定一个元素
1、将xpath表达式过滤出来的结果进行正则匹配,用正则取最终内容
最后.re(‘正则’)
xpath('//div[@class="showlist"]/li//img')[0].re('alt="(\w+)')
2、在选择器规则里应用正则进行过滤
[re:正则规则]
xpath('//div[re:test(@class, "showlist")]').extract()
实战使用Scrapy获取一个电商网站的、商品标题、商品链接、和评论数
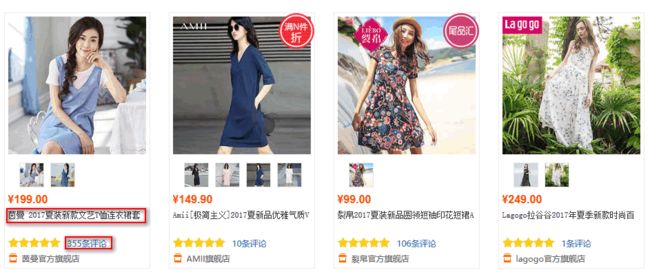
分析源码
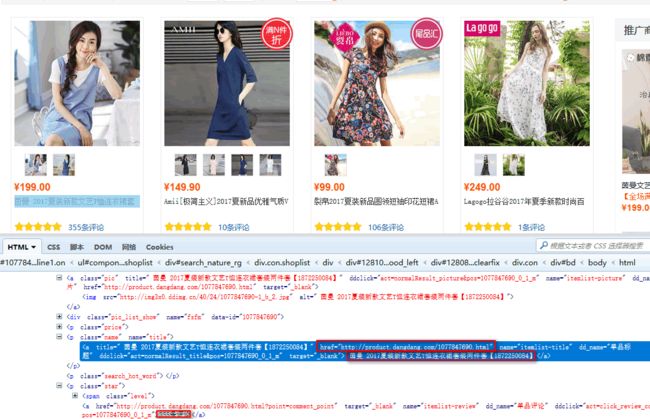
第一步、编写items.py容器文件
我们已经知道了我们要获取的是、商品标题、商品链接、和评论数
在items.py创建容器接收爬虫获取到的数据
设置爬虫获取到的信息容器类,必须继承scrapy.Item类
scrapy.Field()方法,定义变量用scrapy.Field()方法接收爬虫指定字段的信息
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
#items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件
class AdcItem(scrapy.Item): #设置爬虫获取到的信息容器类
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #接收爬虫获取到的title信息
link = scrapy.Field() #接收爬虫获取到的连接信息
comment = scrapy.Field() #接收爬虫获取到的商品评论数
第二步、编写pach.py爬虫文件
定义爬虫类,必须继承scrapy.Spider
name设置爬虫名称
allowed_domains设置爬取域名
start_urls设置爬取网址
parse(response)爬虫回调函数,接收response,response里是获取到的html数据对象
xpath()过滤器,参数是xpath表达式
extract()获取html数据对象里的数据
yield item 接收了数据的容器对象,返回给pipelies.py
# -*- coding: utf-8 -*-
import scrapy
from adc.items import AdcItem #导入items.py里的AdcItem类,容器类
class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['search.dangdang.com'] #爬取域名
start_urls = ['http://category.dangdang.com/pg1-cid4008149.html'] #爬取网址
def parse(self, response): #parse回调函数
item = AdcItem() #实例化容器对象
item['title'] = response.xpath('//p[@class="name"]/a/text()').extract() #表达式过滤获取到数据赋值给,容器类里的title变量
# print(rqi['title'])
item['link'] = response.xpath('//p[@class="name"]/a/@href').extract() #表达式过滤获取到数据赋值给,容器类里的link变量
# print(rqi['link'])
item['comment'] = response.xpath('//p[@class="star"]//a/text()').extract() #表达式过滤获取到数据赋值给,容器类里的comment变量
# print(rqi['comment'])
yield item #接收了数据的容器对象,返回给pipelies.py
robots协议
注意:如果获取的网站在robots.txt文件里设置了,禁止爬虫爬取协议,那么将无法爬取,因为scrapy默认是遵守这个robots这个国际协议的,如果想不遵守这个协议,需要在settings.py设置
到settings.py文件里找到ROBOTSTXT_OBEY变量,这个变量等于False不遵守robots协议,等于True遵守robots协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #不遵循robots协议
第三步、编写pipelines.py数据处理文件
如果需要pipelines.py里的数据处理类能工作,需在settings.py设置文件里的ITEM_PIPELINES变量里注册数据处理类
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'adc.pipelines.AdcPipeline': 300, #注册adc.pipelines.AdcPipeline类,后面一个数字参数表示执行等级,数值越大越先执行
}
注册后pipelines.py里的数据处理类就能工作
定义数据处理类,必须继承object
process_item(item)为数据处理函数,接收一个item,item里就是爬虫最后yield item 来的数据对象
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class AdcPipeline(object): #定义数据处理类,必须继承object
def process_item(self, item, spider): #process_item(item)为数据处理函数,接收一个item,item里就是爬虫最后yield item 来的数据对象
for i in range(0,len(item['title'])): #可以通过item['容器名称']来获取对应的数据列表
title = item['title'][i]
print(title)
link = item['link'][i]
print(link)
comment = item['comment'][i]
print(comment)
return item
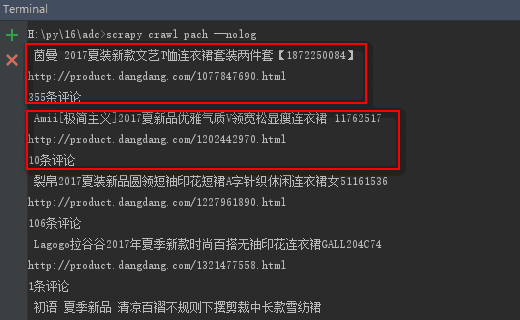
最后执行
执行爬虫文件,scrapy crawl pach --nolog
如果你依然在编程的世界里迷茫,可以加入我们的Python学习扣qun:784758214,看看前辈们是如何学习的!交流经验!自己是一名高级python开发工程师,从基础的python脚本到web开发、爬虫、django、数据挖掘等,零基础到项目实战的资料都有整理。送给每一位python的小伙伴!分享一些学习的方法和需要注意的小细节,点击加入我们的 python学习者聚集地
可以看到我们需要的数据已经拿到了