MapReduce提取一条日志文件中的IP,并计算出访问的次数
这个和我 上篇博客中的代码差不多的,都是用的一个框架,因为原理都是差不多,所以稍微改一下算法就好了。
部分源数据如下:
117.135.212.67 - - [08/Mar/2018:22:35:42 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" -
221.13.7.73 - - [08/Mar/2018:22:35:48 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
117.135.212.67 - - [08/Mar/2018:22:35:52 +0800] "GET /favicon.ico HTTP/1.1" 404 564 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" -
221.13.7.73 - - [08/Mar/2018:22:35:54 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:35:58 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:35:59 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:00 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:01 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:10 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:15 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
117.135.212.67 - - [08/Mar/2018:22:36:19 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" -
221.13.7.73 - - [08/Mar/2018:22:36:21 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
216.126.58.188 - - [08/Mar/2018:22:36:22 +0800] "GET /09/top.php HTTP/1.1" 302 0 "http://google.com" "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 GTB7.1 (.NET CLR 3.5.30729)" -
221.13.7.73 - - [08/Mar/2018:22:36:24 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:28 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:32 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:33 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:33 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:34 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -
221.13.7.73 - - [08/Mar/2018:22:36:35 +0800] "GET / HTTP/1.1" 200 4364 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" -我去研究了一下日志文件,其实是有特定格式的:
| 字段 | 说明 |
|---|---|
| date | 发出请求时候的日期 |
| time | 发出请求时候的时间,注意:默认情况下这个时间是格林威治时间,比我们的北京时间晚8个小时,下面有说明 |
| c-ip | 客户端IP地址 |
| cs-username | 用户名,访问服务器的已经过验证用户的名称,匿名用户用连接符-表示 |
| s-sitename | 服务名,记录当记录事件运行于客户端上的Internet服务的名称和实例的编号 |
| s-computername | 服务器的名称 |
| s-ip | 服务器的IP地址 |
| s-port | 为服务配置的服务器端口号 |
| cs-method | 请求中使用的HTTP方法,GET/POST |
| cs-uri-stem | URI资源,记录做为操作目标的统一资源标识符(URI),即访问的页面文件 |
| cs-uri-query | URI查询,记录客户尝试执行的查询,只有动态页面需要URI查询,如果有则记录,没有则以连接符-表示,即访问网址的附带参数 |
| sc-status | 协议状态,记录HTTP状态代码,200表示成功,403表示没有权限,404表示找不到该页面,具体说明在下面 |
| sc-substatus | 协议子状态,记录HTTP子状态代码 |
| sc-win32-status | Win32状态,记录Windows状态代码 |
| sc-bytes | 服务器发送的字节数 |
| cs-bytes | 服务器接受的字节数 |
| time-taken | 记录操作所花费的时间,单位是毫秒 |
| cs-version | 记录客户端使用的协议版本,HTTP或者FTP |
| cs-host | 记录主机头名称,没有的话以连接符-表示。提醒大家注意:为网站配置的主机名可能会以不同的方式出现在日志文件中,原因是HTTP.sys使用Punycode编码格式来记录主机名 |
| cs(User-Agent) | 用户代理,客户端浏览器、操作系统等情况。 |
| cs(Cookie) | 记录发送或者接受的Cookies内容,没有的话则以连接符-表示。 |
| cs(Referer) | 引用站点,即访问来源 |
所以我就是想把他们切分为一个字段一个字段的,然后想要哪个字段就提取哪个就行了。
直接用框架就好了,然后修改一下,我的想法是,修改mapper的传递的值就好了。
首先是建立三个class
先来job
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class jsipjob {
/**
* @author mshing
* @time 2018-4-26
* @param args
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job jsip = Job.getInstance(conf);
jsip.setJarByClass(jsipjob.class); /*job class*/
jsip.setMapperClass(jsipmapper.class); /*mapper class*/
jsip.setReducerClass(jsipreducer.class); /*reducer class*/
/*map out*/
jsip.setMapOutputKeyClass(Text.class); /*Key*/
jsip.setMapOutputValueClass(IntWritable.class); /*Value*/
/*out*/
jsip.setOutputKeyClass(Text.class);
jsip.setOutputValueClass(IntWritable.class);
/*data file path*/
FileInputFormat.setInputPaths(jsip, args[0]); /*input data path*/
FileOutputFormat.setOutputPath(jsip, new Path(args[1])); /*output data path*/
jsip.waitForCompletion(true);
}
}然后是mapper的class
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class jsipmapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* @author mshing
* @param args
* @throws InterruptedException
* @throws IOException
* @time 2018-4-46
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line = value.toString();
Pattern p = Pattern.compile(
"^([\\d.]+) (\\S+) (\\S+) \\[(.+)\\] \"(GET|POST|DELETE|PUT|HEAD) (\\S+) (\\S+)\" (\\d+) (\\d+) \"(\\S+)\" \"(.+)\" (\\S+)");
List lines = new ArrayList();
lines.add(line);
for (String word : lines) {
Matcher matcher = p.matcher(word);
if (matcher.find()){
word = matcher.group(1);
context.write(new Text(word), new IntWritable(1));
}
}
}
}
我的mapper类是用正则提取出来,IP的位置是1,所以我就输出1,同理可以提取其他信息。
接下来reducer类,这个就是直接用,没有修改地方的
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class jsipreducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* @author mshing
* @param args
* @throws InterruptedException
* @throws IOException
* @time 2018-4-26
*
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException{
int count = 0;
for (IntWritable value : values){
count += value.get();
}
context.write(key, new IntWritable(count)); /*out key*/
}
}
然后打包成jar包
![]()
把需要计算的文件上传至hdfs文件系统

然后就可以开始计算了
然后出现如下信息则是成功了
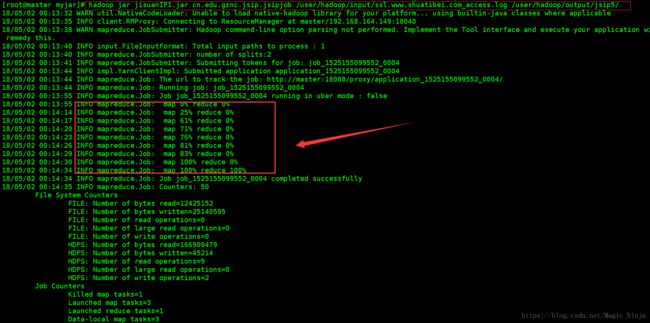
注意:输出路径不能重复,还有job所在jar包在的位置都不能出错
成功后输出的文件的位置,输出文件就放在part-r-00000里面
![]()

因为我的总数据有点大
嗯就是这样计算出来了
建议把文件下载下来然后做一个数据可视化,那就非常好看的了