python写爬虫3-MongoDB数据缓存(采集58出租房信息)
python写爬虫3-MongoDB数据缓存(采集58出租房信息)
有时,我们下载某个页面并抓取部分数据后,之后可能还会需要重新下载该页面,抓取其他数据。对于小网站而言,这不算什么大问题;但对于那些拥有百万网页的网站来说,重新爬取可能需要耗费大量时间。因此,我们可以对已爬取的网页进行缓存,让每个页面只下载一次。
本文代码只是实现了数据的存储与获取,与上述案例实情不符
开发环境:
1.硬件mac
2.python2.7
3.MongoDB3.4.2
NoSQL即Not Only SQL,通常是无模式的,NoSQL包含列数据存储(HBase),键值对存储(Redis),面向文档的数据库(MongoDB),图形数据库(Neo4j);本文采用MongoDB,MongoDB有个功能:为数据设定时间,当到达设定时间后,MongoDB可自动为我们删除记录。
需注意,MongoDB缓存无法按设定时间精确清理过期记录,会存在1分钟内的延迟,这是MongoDB的运行机制造成的
1.安装MongoDB及对应的Python封装库
mac下安装MongoDB命令:
brew update
brew install mongodb
pip install pymongo2.配置MongoDB
创建默认MongoDB数据库文件存放目录
mkdir -p /data/db记得给此目录加用户的读写权限,不然会报权限错误;其他配置,请参见官方文档。
3.启动MongoDB
mongod4.MongoDB缓存实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pickle
import zlib
from bson.binary import Binary
from datetime import datetime, timedelta
from pymongo import MongoClient
class MongoCache:
def __init__(self, client=None, expires=timedelta(days=1)):
self.client = MongoClient('localhost', 27017)
self.db = self.client.cache
self.db.webpage.create_index('timestamp', expireAfterSeconds=expires.total_seconds())
def __getitem__(self, item):
record = self.db.webpage.find_one({'id': item})
if record:
return pickle.loads(zlib.decompress(record['result'])) # 压缩数据
else:
return None
# raise KeyError(item + 'dose not exist')
def __setitem__(self, key, value):
record = {'result': Binary(zlib.compress(pickle.dumps(value))), 'timestamp': datetime.utcnow()}
self.db.webpage.update({'id': key}, {'$set': record}, upsert=True)5.爬虫编写
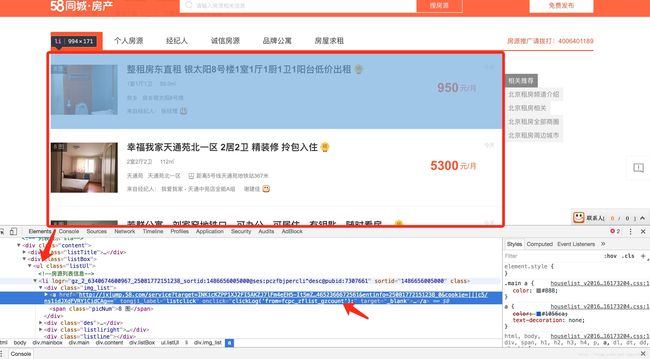
先看一下http://bj.58.com/zufang/页面结构:
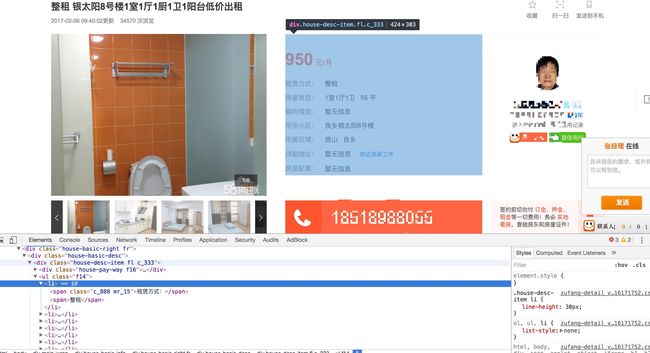
再看一下出租房详细页面结构:
下面开始敲代码:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
import lxml.html
import time
from lxml.cssselect import CSSSelector
from MongoCache import MongoCache
def download(url, user_agent='Google', num_retries=2):
"""下载整个页面"""
print 'Downloading:', url
# 设置用户代理
headers = {'User-agent': user_agent}
request = urllib2.Request(url, headers=headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'Downloading error:', e.reason
html = None
# 只有在服务器报500-600错误时,才会重试下载,仅重试2次
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
return download(url, num_retries-1)
return html
def get_data(url):
"""从详细页面 获取各字段数据"""
# 如果缓存中有该页面数据,则直接获取使用;否则,先下载页面,再使用
cache = MongoCache()
if not cache.__getitem__(url):
html_text_detail = download(url)
if not html_text_detail:
pass
else:
cache.__setitem__(url, html_text_detail)
else:
print 'Exists:', url
html_text_detail = cache.__getitem__(url)
try:
# 获取个字段数据
tree = lxml.html.fromstring(html_text_detail)
house_title = CSSSelector('div.main-wrap > div.house-title > h1')
house_pay_way1 = CSSSelector('div.house-pay-way > span:nth-child(1)')
house_pay_way2 = CSSSelector('div.house-pay-way > span:nth-child(2)')
print house_title(tree)[0].text_content()
print '%s|%s' % (house_pay_way1(tree)[0].text_content(), house_pay_way2(tree)[0].text_content())
for i in range(7):
for j in range(2):
css = 'div.house-desc-item > ul.f14 > li:nth-child(%s) > span:nth-child(%s)' % (i+1, j+1)
house_info = CSSSelector(css)
print house_info(tree)[0].text_content().replace(' ', '')
except TypeError as e:
print 'HTML文本发生错误:%s' % e
except IndexError as e:
print '获取详细数据发生错误:%s' % e
def get_url(html):
"""获取需爬取数据的链接集"""
tree = lxml.html.fromstring(html)
sel = CSSSelector('div.mainbox > div.main > div.content > div.listBox > ul.listUl > li > div.des > h2 > a')
url_list = []
for i in sel(tree):
if i.get('href') not in url_list:
url_list.append(i.get('href'))
return url_list
if __name__ == '__main__':
url_index = 'http://bj.58.com/chuzu/'
html_text_list = download(url_index)
url_list = get_url(html_text_list)
for url_detail in url_list:
time.sleep(2) # 延时2s
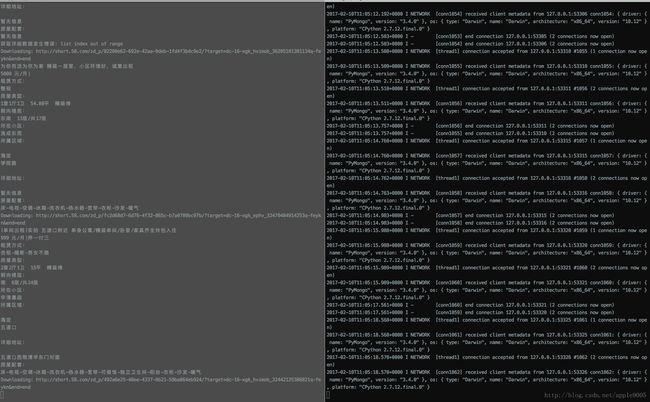
get_data(url_detail)执行效果图:(左屏为数据抓取输出;右屏为MongoDB数据库)