DID 边际分析:让政策评价结果更加丰满
作者:卢梅 | Stata连享会 (知乎 | 简书 | 码云)
Stata连享会现场班课程

文章目录
- [Stata连享会现场班课程](https://gitee.com/arlionn/stata_training/blob/master/README.md)
- @[toc]
- 1、前言
- 2、margins 命令介绍
- 3、DID 的边际分析
- 4、对margin结果的修正
- 相关链接
- 主要代码
- 关于我们
- 联系我们
- 往期精彩推文
文章目录
- [Stata连享会现场班课程](https://gitee.com/arlionn/stata_training/blob/master/README.md)
- @[toc]
- 1、前言
- 2、margins 命令介绍
- 3、DID 的边际分析
- 4、对margin结果的修正
- 相关链接
- 主要代码
- 关于我们
- 联系我们
- 往期精彩推文
1、前言
倍差法( DID )是政策评价中被广泛应用的方法,DID 的结果表明某项政策的实施将会对因变量平均产生多少影响,但是很多时候我们都想知道,在某一个自变量处于某一特定水平,或者是某几个自变量处于特定水平时,政策效应到底有多大。
比如说,某项政策对于居民健康有正的影响,但是我们想知道这项政策对于 20 岁、 30 岁、 60 岁的居民影响有多大。将边际分析(margin)应用到 DID 中,可以观察到在任何一个想要的位置上政策冲击的所带来的边际效应是多少。margins 命令可以实现这一功能。
接下来让我们近距离观察一下 margin。
2、margins 命令介绍
在 Stata 命令窗口中输入 help margins 可以查看完整的帮助文件。事实上,它与 Stata 中的 predict,lincom 等命令有密切的关系。
predict的功能是用现有的估计结果(主要是估计所得的系数)来估计观测对象的统计指标。lincom、nlcom的功能在于估计已有系数的线性或非线性表达式。margin命令综合了predict与lincom、nlcom的功能,来估计边际效果。
margin是指在基于数据集计算的拟合模型基础上,看在不同的协变量值的情况下,边际效应是多少。
简单来说,margin 其实就是,先利用已有的数据估计出模型系数,然后再用这些系数算出线性或非线性表达式的值,接着预测协变量处于一定水平上时的边际效果。
margin 本身就是一个可以实现众多功能的命令,关于它此处不做过多介绍,大家有兴趣的话可以 help 一下。
3、DID 的边际分析
Andrew P Wheeler 教授生成一份数据来具体讲述 margin 运用到 DID 中的示例,我们也使用 Andrew P Wheeler 生成的数据来给大家说明。
数据结构:Y 代表被解释变量,Post 和 Exper 可以理解为政策冲击的虚拟变量和是否为政策实施地区的虚拟变量,它们二者的交乘项系数表示政策效果,还有一个 Ord 序列变量就相当于我们经常用的 id。
很简单的数据,但是要注意,虽然 DID 及后续分析中用到了 i.month,但是这份数据并不是多期 DID,不同的月份只是代表不同的分类, i.month 表示在全年 12 个月中每个月都有一个特有的 DID 回归系数,可以将 month 类比为对于 20 多岁组, 30 多岁组, 40 多岁组这种,一月份组,二月份组,十二月份组。
DID 回归代码如下,之所以用 xtgee、poisson 广义估计泊松模型是由这份数据的性质决定的,这个我们可以先不用管它,就把它当作一般的回归就好。
tsset Exper Ord
asdoc xtgee Y Exper#Post i.Month, family(poisson) corr(ar1) replace
回归结果为:
GEE population-averaged model Number of obs = 264
Group and time vars: Exper Ord Number of groups = 2
Link: log Obs per group:
Family: Poisson min = 132
Correlation: AR(1) avg = 132.0
max = 132
Wald chi2(14) = 334.52
Scale parameter: 1 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
Y | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
Exper#Post |
0 1 | .339348 .0898574 3.78 0.000 .1632307 .5154653
1 0 | 1.157615 .0803121 14.41 0.000 1.000206 1.315023
1 1 | .7602288 .0836317 9.09 0.000 .5963138 .9241439
|
Month |
2 | .214908 .1243037 1.73 0.084 -.0287228 .4585388
3 | .2149183 .1264076 1.70 0.089 -.0328361 .4626726
4 | .3119988 .1243131 2.51 0.012 .0683497 .5556479
5 | .4416236 .1210554 3.65 0.000 .2043594 .6788877
6 | .556197 .1184427 4.70 0.000 .3240536 .7883404
7 | .4978252 .1197435 4.16 0.000 .2631322 .7325182
8 | .2581524 .1257715 2.05 0.040 .0116447 .50466
9 | .222813 .1267606 1.76 0.079 -.0256333 .4712592
10 | .430002 .121332 3.54 0.000 .1921956 .6678084
11 | .0923395 .1305857 0.71 0.479 -.1636037 .3482828
12 | -.1479884 .1367331 -1.08 0.279 -.4159803 .1200035
|
_cons | .9699886 .1140566 8.50 0.000 .7464418 1.193536
------------------------------------------------------------------------------
接下来对一月份组进行的边际分析,就是说此项政策实施对于一月份组来说效果有多大(base 默认为一月),代码如下:
margins Post#Exper, at( (base) Month )
结果如下:
Adjusted predictions Number of obs = 264
Model VCE : Conventional
Expression : Exponentiated linear prediction, predict()
at : Month = 1
------------------------------------------------------------------------------
| Delta-method
| Margin Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
Post#Exper |
0 0 | 2.637914 .3008716 8.77 0.000 2.048217 3.227612
0 1 | 8.394722 .8243735 10.18 0.000 6.77898 10.01046
1 0 | 3.703716 .3988067 9.29 0.000 2.922069 4.485363
1 1 | 5.641881 .5783881 9.75 0.000 4.508261 6.775501
------------------------------------------------------------------------------
以图形展示 margin 结果,代码如下:
marginsplot, recast(scatter)
图形如下:
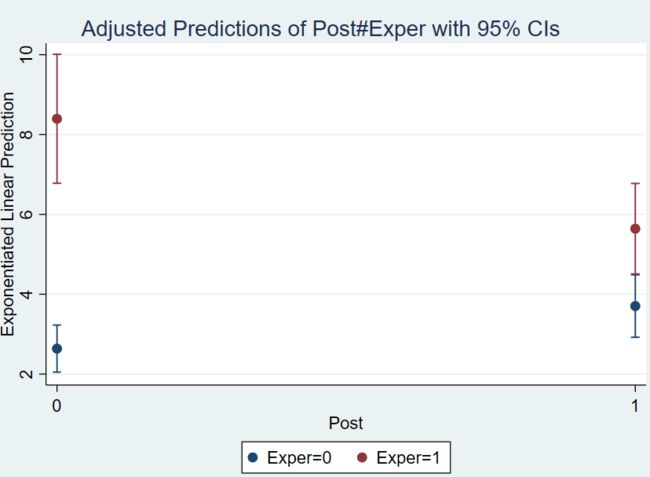
如果不想要两边边的 end cross hairs(还是不要让我翻译了,哈哈哈,我的第一反应是边边起横长的毛发)可以输入如下代码,然后看一下效果,就知道差别在哪里了。
marginsplot, recast(scatter) ciopts(recast(rspike))
去掉 end cross hairs 的图形:
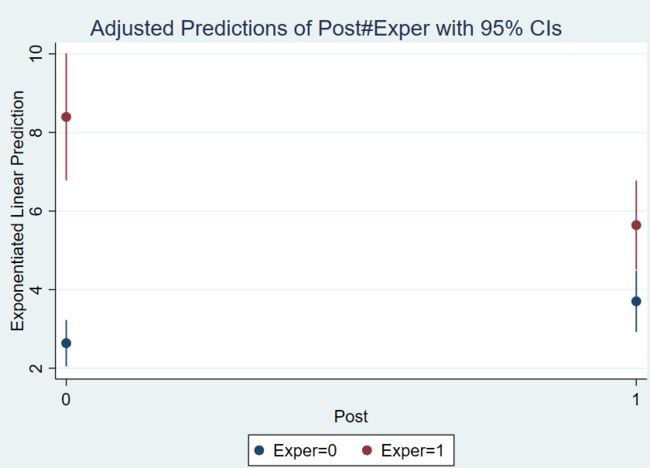
直观来看,对照组因变量上升了 1 个单位,实验组因变量下降了 2 个单位。
但是Andrew教授的同事提出,设置对照组的意义在于看到如果没有实行政策时会是怎样的情形,对照组因变量是下降的,那么实验组因变量也应该 是下降的,我们更应该看的是实验组因变量的相对变动。
我们需要借助lincom、nlcom等指令计算已估系数的表达式,然后还原出真正实验组对于对照组的相对变化。
4、对margin结果的修正
lincom、nlcom之前,我们可以先用test检验一下相对下降是否存在,代码如下:
test 1.Exper#1.Post = (1.Exper#0.Post + 0.Exper#1.Post)
结果为:
chi2( 1) = 46.50
Prob > chi2 = 0.0000
结果显示,相对下降显著。
当然也可以对各分组系数做联合检验,代码如下:
testparm i.Month
结果如下:
(1) 2.Month = 0
(2) 3.Month = 0
(3) 4.Month = 0
(4) 5.Month = 0
(5) 6.Month = 0
(6) 7.Month = 0
(7) 8.Month = 0
(8) 9.Month = 0
(9) 10.Month = 0
(10) 11.Month = 0
(11) 12.Month = 0
chi2( 11) = 61.58
Prob > chi2 = 0.0000
结果依然显著。接下来我们使用lincom、nlcom来看真实的相对下降是多少。
lincom 1.Exper#1.Post - 0.Exper#1.Post - 1.Exper#0.Post
结果如下:
------------------------------------------------------------------------------
Y | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
(1) | -.7367337 .1080418 -6.82 0.000 -.9484917 -.5249757
------------------------------------------------------------------------------
这一结果与在回归模型中,直接加入i.Exper i.Post的效果是一样的。输入如下代码:
xtgee Y i.Exper i.Post Exper#Post i.Month, family(poisson) corr(ar1)
结果如下:
GEE population-averaged model Number of obs = 264
Group and time vars: Exper Ord Number of groups = 2
Link: log Obs per group:
Family: Poisson min = 132
Correlation: AR(1) avg = 132.0
max = 132
Wald chi2(14) = 334.52
Scale parameter: 1 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
Y | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.Exper | 1.157615 .0803121 14.41 0.000 1.000206 1.315023
1.Post | .339348 .0898574 3.78 0.000 .1632307 .5154653
|
Exper#Post |
1 1 | -.7367337 .1080418 -6.82 0.000 -.9484917 -.5249757
|
Month |
2 | .214908 .1243037 1.73 0.084 -.0287228 .4585388
3 | .2149183 .1264076 1.70 0.089 -.0328361 .4626726
4 | .3119988 .1243131 2.51 0.012 .0683497 .5556479
5 | .4416236 .1210554 3.65 0.000 .2043594 .6788877
6 | .556197 .1184427 4.70 0.000 .3240536 .7883404
7 | .4978252 .1197435 4.16 0.000 .2631322 .7325182
8 | .2581524 .1257715 2.05 0.040 .0116447 .50466
9 | .222813 .1267606 1.76 0.079 -.0256333 .4712592
10 | .430002 .121332 3.54 0.000 .1921956 .6678084
11 | .0923395 .1305857 0.71 0.479 -.1636037 .3482828
12 | -.1479884 .1367331 -1.08 0.279 -.4159803 .1200035
|
_cons | .9699886 .1140566 8.50 0.000 .7464418 1.193536
--------------------------------
结果与通过lincom命令得到的交乘项系数是一样的,因为模型是泊松模型,所以我们再使用nlcom还原到更直观的数值变动。代码如下:
nlcom exp(_b[1.Exper] + _b[1.Post] + _b[_cons])
结果如下:
------------------------------------------------------------------------------
Y | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_nl_1 | 11.78646 1.583091 7.45 0.000 8.683656 14.88926
------------------------------------------------------------------------------
因为看的是第一个月组的情况,month 前的系数为0,所以nlcom命令常数项后面不用加 month 的系数,如果想看2月份组、3月份组的政策效应的话,就应该把 month 的系数加上。
政策实施后因变量是 11.79 接近 12 的值,再想想之前那个长着 end cross hairs 的图,实验组从 8 变到 6 ,其实是不准确的,应该是从 12 变到 6,政策效应是使因变量减少了 8 个单位每月!
所以DID时,其实应该使用xtgee Y i.Exper i.Post Exper#Post i.Month, family(poisson) corr(ar1)这种形式的回归,得到回归结果后,再用nlcom计算出实际变动值。
相关链接
https://andrewpwheeler.wordpress.com/2016/05/12/some-stata-notes-difference-in-difference-models-and-postestimation-commands/
主要代码
tsset Exper Ord
xtgee Y Exper#Post i.Month, family(poisson) corr(ar1)
margins Post#Exper, at( (base) Month )
marginsplot, recast(scatter)
test 1.Exper#1.Post = (1.Exper#0.Post + 0.Exper#1.Post)
testparm i.Month
lincom 1.Exper#1.Post - 0.Exper#1.Post - 1.Exper#0.Post
xtgee Y i.Exper i.Post Exper#Post i.Month, family(poisson) corr(ar1)
nlcom exp(_b[1.Exper] + _b[1.Post] + _b[_cons])
关于我们
- 【Stata 连享会(公众号:StataChina)】由中山大学连玉君老师团队创办,旨在定期与大家分享 Stata 应用的各种经验和技巧。
- 公众号推文同步发布于 CSDN-Stata连享会 、简书-Stata连享会 和 知乎-连玉君Stata专栏。可以在上述网站中搜索关键词
Stata或Stata连享会后关注我们。 - 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- Stata连享会 精彩推文1 || 精彩推文2
联系我们
- 欢迎赐稿: 欢迎将您的文章或笔记投稿至
Stata连享会(公众号: StataChina),我们会保留您的署名;录用稿件达五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。 - 意见和资料: 欢迎您的宝贵意见,您也可以来信索取推文中提及的程序和数据。
- 招募英才: 欢迎加入我们的团队,一起学习 Stata。合作编辑或撰写稿件五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。
- 联系邮件: [email protected]
往期精彩推文
- Stata连享会推文列表1
- Stata连享会推文列表2
- Stata连享会 精彩推文1 || 精彩推文2
