Stata-交乘项专题: 主效应项可以忽略吗?
作者:胡雨霄 (伦敦政治经济学院)
Stata 连享会: 知乎 | 简书 | 码云 | CSDN
Source: WHAT HAPPENS IF YOU OMIT THE MAIN EFFECT IN A REGRESSION MODEL WITH AN INTERACTION?

Stata连享会 计量专题 || 精品课程 || 简书推文 || 公众号合集
2020寒假Stata现场班
北京, 1月8-17日,连玉君-江艇主讲

2020连享会-文本分析与爬虫-现场班
西安, 3月26-29日,司继春-游万海 主讲; (附助教招聘)

连享会计量方法专题……
对于一个带交乘项 (interaction term) 的线性回归,我们一般会通过命令
regress y x1 x2 x1#x2
来进行回归分析。该回归不仅包括交乘项 (x1#x2) 而且保留了主效应 (x1 x2)。本篇推文讨论的问题是,
当引入交乘项后,保留全部的主效应项是否必要?忽略一个或者全部的主效应项是否可行?
对于该问题,首先要明确引入主效应项和交乘项的目的何在。引入主效应项是为了区分截距,而引入交乘项是为了区分斜率。在接下来的分析中,我们会进一步阐述这句话背后的具体含义。
基于此,对于该问题的回答应为“分情况讨论”。
-
类别变量相互交乘:可以去掉主效应项,但系数含义不同。
-
类别变量与连续型变量相互交乘:(1)可以去掉连续型变量主效应项,但系数含义发生改变;(2)一般情况下,不可以去掉类别变量主效应项
-
连续型变量与连续型变量相互交乘:一般情况下,不可以去掉主效应项
下面,我们通过几个实证的例子来进一步解释说明。
1. 实例 1:类别变量相互交乘 (categorical by categorical interaction)
首先,导入数据
. use https://stats.idre.ucla.edu/stat/data/hsbanova, clear
(highschool and beyond (200 cases))
. d
variable name type format label variable label
-----------------------------------------------------------------------------------------------------------------------
id float %9.0g
female float %9.0g fl
read float %9.0g reading score
write float %9.0g writing score
math float %9.0g math score
science float %9.0g science score
socst float %9.0g social studies score
honors float %19.0g honlab honors english
grp float %9.0g grp
-----------------------------------------------------------------------------------------------------------------------
Sorted by:
该数据记录了不同个体的性别信息 (female),组别信息 (grp),以及不同科目的成绩信息(read, write, math, science, socst, honors) 。
数据结构如下所示。
. list in 1/10
+----------------------------------------------------------------------------+
| id female read write math science socst honors grp |
|----------------------------------------------------------------------------|
1. | 45 female 34 35 41 29 26 not enrolled grp1 |
2. | 108 male 34 33 41 36 36 not enrolled grp2 |
3. | 15 male 39 39 44 26 42 not enrolled grp1 |
4. | 67 male 37 37 42 33 32 not enrolled grp1 |
5. | 153 male 39 31 40 39 51 not enrolled grp1 |
|----------------------------------------------------------------------------|
6. | 51 female 42 36 42 31 39 not enrolled grp2 |
7. | 164 male 31 36 46 39 46 not enrolled grp1 |
8. | 133 male 50 31 40 34 31 not enrolled grp1 |
9. | 2 female 39 41 33 42 41 not enrolled grp1 |
10. | 53 male 34 37 46 39 31 not enrolled grp1 |
+----------------------------------------------------------------------------+
.
我们将既包含交乘项也包含主效应项的模型成为 “完整模型” (full model)。在这个例子中,我们对类别变量 female 以及类别变量 grp 进行交乘。
- 完整模型
. regress write i.female##i.grp
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(7, 192) = 11.05
Model | 5135.17494 7 733.59642 Prob > F = 0.0000
Residual | 12743.7001 192 66.3734378 R-squared = 0.2872
-------------+---------------------------------- Adj R-squared = 0.2612
Total | 17878.875 199 89.843593 Root MSE = 8.147
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
female |
female | 9.136876 2.311726 3.95 0.000 4.577236 13.69652
|
grp |
grp2 | 7.31677 2.458951 2.98 0.003 2.466743 12.1668
grp3 | 10.10248 2.292658 4.41 0.000 5.580454 14.62452
grp4 | 16.75286 2.525696 6.63 0.000 11.77119 21.73453
|
female#grp |
female#grp2 | -5.029733 3.357123 -1.50 0.136 -11.65131 1.591845
female#grp3 | -3.721697 3.128694 -1.19 0.236 -9.892723 2.449328
female#grp4 | -9.831208 3.374943 -2.91 0.004 -16.48793 -3.174482
|
_cons | 41.82609 1.698765 24.62 0.000 38.47545 45.17672
------------------------------------------------------------------------------
在进行分析之前,我们首先明确各系数的含义。从常数项 (_cons) 开始,41.82609 表示组别 1 男性 (female == 0, grp1 == 1) 的写作分数 (write)。
以此为基准,我们列表分析不同组别不同性别的人群的写作分数。下表按照回归结果,计算了不同组别的男性和女性的写作分数。
以 female == 1, group == 2 为例,group 2 的女性的写作水平为 41.83 + 9.14 + 7.31 - 5.03 = 53.25。
| female | group | _cons | | | | write |
|---------|-------|-------|---------|---------|---------|-------|
| 0 | 1 | 41.83 | | | | 41.83 |
| | | | | | | |
| 1 | 1 | | + 9.14 | | | 50.97 |
| | | | | | | |
| 0 | 2 | | + 7.31 | | | 49.14 |
| 0 | 3 | | + 10.10 | | | 51.93 |
| 0 | 4 | | + 16.75 | | | 58.58 |
| | | | | | | |
| 1 | 2 | | + 9.14 | + 7.31 | - 5.03 | 53.25 |
| 1 | 3 | | + 9.14 | + 10.10 | - 3.72 | 57.35 |
| 1 | 4 | | + 9.14 | + 16.75 | - 9.83 | 57.89 |
我们也可以通过 margins 命令直接得到上述计算结果。
. margins female##grp
------------------------------------------------------------------------------
| Margin Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
female#grp |
male#grp1 | 41.82609 1.698765 24.62 0.000 38.47545 45.17672
male#grp2 | 49.14286 1.777819 27.64 0.000 45.63629 52.64942
male#grp3 | 51.92857 1.539636 33.73 0.000 48.8918 54.96534
male#grp4 | 58.57895 1.869048 31.34 0.000 54.89244 62.26545
female#grp1 | 50.96296 1.567889 32.50 0.000 47.87046 54.05546
female#grp2 | 53.25 1.662997 32.02 0.000 49.96991 56.53009
female#grp3 | 57.34375 1.440198 39.82 0.000 54.50311 60.18439
female#grp4 | 57.88462 1.597756 36.23 0.000 54.73321 61.03602
-----------------------------------------------------------------------
- 模型 2:去掉主效应项 female
当去掉主效应项 female 后,回归结果如下所示。
. regress write i.grp i.female#i.grp
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(7, 192) = 11.05
Model | 5135.17494 7 733.59642 Prob > F = 0.0000
Residual | 12743.7001 192 66.3734378 R-squared = 0.2872
-------------+---------------------------------- Adj R-squared = 0.2612
Total | 17878.875 199 89.843593 Root MSE = 8.147
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
grp |
grp2 | 7.31677 2.458951 2.98 0.003 2.466743 12.1668
grp3 | 10.10248 2.292658 4.41 0.000 5.580454 14.62452
grp4 | 16.75286 2.525696 6.63 0.000 11.77119 21.73453
|
female#grp |
female#grp1 | 9.136876 2.311726 3.95 0.000 4.577236 13.69652
female#grp2 | 4.107143 2.434379 1.69 0.093 -.6944172 8.908703
female#grp3 | 5.415179 2.108234 2.57 0.011 1.256906 9.573452
female#grp4 | -.694332 2.458895 -0.28 0.778 -5.544247 4.155583
|
_cons | 41.82609 1.698765 24.62 0.000 38.47545 45.17672
------------------------------------------------------------------------------
我们可以看到 grp1 grp2 以及 grp3 的回归结果与完整模型是完全一致的。可以直观看到,完整模型的 female 的系数其实和模型 2 的 female#grp1 的系数完全一致。而 female#grp2 的系数其实等于完整模型 female 的系数加上完整模型的 female#grp2 的系数,即 4.10 = 9.13 - 5.03 。
在这种情况下,模型中未引入主效应项的主要影响是重整 Stata 汇报的回归系数。其结果其实和完整模型的回归结果是一致的。Stata 自行发现了被忽略的主效应项,并汇报了 4 个交乘项的结果,而非像完整模型那样汇报 3 个。这样,完整模型的自由度与模型 2 的自由度均为 7。
接下来,我们探讨一个关于 显著性 的问题。完整模型的回归结果中,female#grp3 的 p-value 为 0.236,是不显著的。而当去掉 female 的主效应后,female#grp3 的 p-value 为 0.011, 在 5% 的水平上显著。该如何理解这一系数显著性的变化呢?
在完整模型中,female#grp3 的系数报告的是 group 3 的性别差异与 group 1 的性别差异之差 (across group difference of gender difference)。系数不显著说明,group 3 不同性别成员间的写作水平差异并没有显著高于或者低于 group 1 不同性别成员间的写作水平差异。female#grp4 的系数为 -9.831,并且在 1% 的水平上显著。这说明,相较于 group 1,group 4 的不同性别成员间的写作水平差异显著低了 9.83。由此推测两种可能结果。第一,group 4 不同性别成员间并无显著写作水平差距。第二,group 4 不同性别成员间虽有显著写作水平差距,但是该差距小于 group 1。
模型 2 也汇报了 female#grp3 的系数,但是却是完全不同的含义。该系数报告的是 group 3 的性别差异 (within group gender difference)。该系数为 5.415,且在 5% 的水平上显著。这说明 group 3 的女性的写作水平比该组男性显著高出 5.415 分。值得注意的是,female#grp4 的系数此时不显著。这说明 group 4 的女性的写作水平与该组男性的写作水平并无显著差异。该结论支持推测的第一种结果。
将两个模型放到一起看,我们关于各组性别差异得到的信息如下。
(1) 组内性别差异 (within-group gender difference) group 1, group 2 以及 group 3 的女性的写作水平显著高于同组男性的写作水平。group 4 各成员的写作水平并不存在性别层面上的显著差异。该信息由模型 2 给出。
(2)组间性别差异之差 (across-group difference of gender difference) 以 group 1 组内成员写作水平的性别差异为基准,group 2 和 group 3 组内成员写作水平的性别差异并无显著差异。然而,group 4 组内成员写作水平的性别差异显著低于基准组。
- 模型 3:去掉主效应项
grp
. regress write i.female i.female#i.grp
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(7, 192) = 11.05
Model | 5135.17494 7 733.59642 Prob > F = 0.0000
Residual | 12743.7001 192 66.3734378 R-squared = 0.2872
-------------+---------------------------------- Adj R-squared = 0.2612
Total | 17878.875 199 89.843593 Root MSE = 8.147
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
female |
female | 9.136876 2.311726 3.95 0.000 4.577236 13.69652
|
female#grp |
male#grp2 | 7.31677 2.458951 2.98 0.003 2.466743 12.1668
male#grp3 | 10.10248 2.292658 4.41 0.000 5.580454 14.62452
male#grp4 | 16.75286 2.525696 6.63 0.000 11.77119 21.73453
female#grp2 | 2.287037 2.285571 1.00 0.318 -2.221015 6.79509
female#grp3 | 6.380787 2.128954 3.00 0.003 2.181646 10.57993
female#grp4 | 6.921652 2.238549 3.09 0.002 2.506347 11.33696
|
_cons | 41.82609 1.698765 24.62 0.000 38.47545 45.17672
------------------------------------------------------------------------------
分析模型 3 的基本思想与模型 2 一致。当去掉 i.group 后,交乘项的含义发生改变,male##grp 和 female##grp* 分别汇报的是 group* 的男性和女性与 group 1 的男性和女性的写作分数差距。换言之,其汇报的是 同性别组间差异 (within-gender across-group difference)。其经济学含义不难解释。
- 模型 4:只保留交乘项
. regress write i.female#i.grp
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(7, 192) = 11.05
Model | 5135.17494 7 733.59642 Prob > F = 0.0000
Residual | 12743.7001 192 66.3734378 R-squared = 0.2872
-------------+---------------------------------- Adj R-squared = 0.2612
Total | 17878.875 199 89.843593 Root MSE = 8.147
------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
female#grp |
male#grp2 | 7.31677 2.458951 2.98 0.003 2.466743 12.1668
male#grp3 | 10.10248 2.292658 4.41 0.000 5.580454 14.62452
male#grp4 | 16.75286 2.525696 6.63 0.000 11.77119 21.73453
female#grp1 | 9.136876 2.311726 3.95 0.000 4.577236 13.69652
female#grp2 | 11.42391 2.377259 4.81 0.000 6.735015 16.11281
female#grp3 | 15.51766 2.227099 6.97 0.000 11.12494 19.91039
female#grp4 | 16.05853 2.332086 6.89 0.000 11.45873 20.65833
|
_cons | 41.82609 1.698765 24.62 0.000 38.47545 45.17672
------------------------------------------------------------------------------
当只保留交乘项后,常数项的意义保持不变,其余各项系数分别表示不同组别成员与 group 1 男性成员的写作分数差距。
2. 实例 2:类别变量与连续变量交乘 (categorical by continuous interaction)
- 完整模型
. regress write i.female##c.socst
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(3, 196) = 49.26
Model | 7685.43528 3 2561.81176 Prob > F = 0.0000
Residual | 10193.4397 196 52.0073455 R-squared = 0.4299
-------------+---------------------------------- Adj R-squared = 0.4211
Total | 17878.875 199 89.843593 Root MSE = 7.2116
--------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------------+----------------------------------------------------------------
female |
female | 15.00001 5.09795 2.94 0.004 4.946132 25.05389
socst | .6247968 .0670709 9.32 0.000 .4925236 .7570701
|
female#c.socst |
female | -.2047288 .0953726 -2.15 0.033 -.3928171 -.0166405
|
_cons | 17.7619 3.554993 5.00 0.000 10.75095 24.77284
--------------------------------------------------------------------------------
常数项的含义为socst=0 的男性的写作分数。socst的系数,0.625 ,为男性组别writing对socst做回归的系数。
我们用图形来解释交乘项的含义。如图所示的三条线分别报告了全样本和不同性别的 writing 与 socst 的线性关系。其中,主效应项i.female 的作用在于区分不同组别的截距,交乘项的作用则在于允许斜率的改变。此处,交乘项系数的含义为
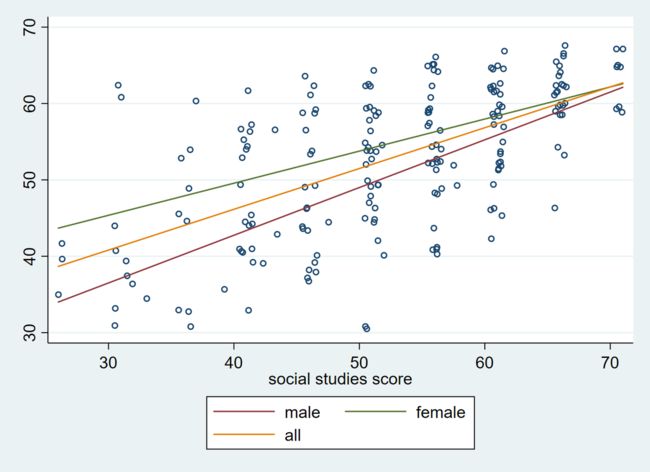
**交乘项的系数报告了不同组别斜率之差。**其系数为 -0.205,说明女性组别 writing 对 socst 做回归的系数为 0.625 - 0.205 = 0.420。
- 模型 2:去掉主效应项
c.socst
. reg write i.female i.female#c.socst
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(3, 196) = 49.26
Model | 7685.43528 3 2561.81176 Prob > F = 0.0000
Residual | 10193.4397 196 52.0073455 R-squared = 0.4299
-------------+---------------------------------- Adj R-squared = 0.4211
Total | 17878.875 199 89.843593 Root MSE = 7.2116
--------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------------+----------------------------------------------------------------
female |
female | 15.00001 5.09795 2.94 0.004 4.946132 25.05389
|
female#c.socst |
male | .6247968 .0670709 9.32 0.000 .4925236 .7570701
female | .420068 .0678044 6.20 0.000 .2863482 .5537878
|
_cons | 17.7619 3.554993 5.00 0.000 10.75095 24.77284
--------------------------------------------------------------------------------
该模型交互项汇报的是男性和女性组别,writing 对 socst 做回归 socst 的系数。我们可以看到,交乘项中,female 的系数与 male 的系数之差正好为完整模型的交互项的系数。
- 模型 3:去掉主效应项
i.female
. reg write socst i.female#c.socst
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(2, 197) = 66.96
Model | 7235.18229 2 3617.59115 Prob > F = 0.0000
Residual | 10643.6927 197 54.028897 R-squared = 0.4047
-------------+---------------------------------- Adj R-squared = 0.3986
Total | 17878.875 199 89.843593 Root MSE = 7.3504
--------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------------+----------------------------------------------------------------
socst | .4903271 .0500357 9.80 0.000 .3916528 .5890014
|
female#c.socst |
female | .0701563 .0195532 3.59 0.000 .0315957 .1087168
|
_cons | 25.0561 2.597064 9.65 0.000 19.93449 30.17772
--------------------------------------------------------------------------------
注意:这个模型很有可能是错误识别模型(mispecification)。如果要使用该模型,一定要确保研究目标和模型设定的一致性。
上文,我们说过,加入组别变量主效应项的目的在于区分不同组别的截距,而加入交乘项在于区分不同组别的斜率。现在这个模型只保留了连续型变量主效应项,其实并没有允许区分不同组别的截距。因此,这个常数项的含义为全样本 socst = 0 的平均写作分数。
交乘项的系数含义为假设男性组别和女性组别的截距是相同的,女性组别的斜率和男性组别斜率之差。
可以用其他命令 margins 和 lincome 进一步解释为什么使用该模型一定要谨慎小心。
截距项无区分:
. reg write socst i.female#c.socst
. margins, at(female=(0 1) socst = 0) noatlegend
Adjusted predictions Number of obs = 200
Model VCE : OLS
Expression : Linear prediction, predict()
------------------------------------------------------------------------------
| Delta-method
| Margin Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_at |
1 | 25.0561 2.597064 9.65 0.000 19.93449 30.17772
2 | 25.0561 2.597064 9.65 0.000 19.93449 30.17772
------------------------------------------------------------------------------
如下汇报的是不同组别的斜率。
. margins, dydx(socst) at(female=(0 1)) noatlegend post
Average marginal effects Number of obs = 200
Model VCE : OLS
Expression : Linear prediction, predict()
dy/dx w.r.t. : socst
------------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
socst |
_at |
1 | .4903271 .0500357 9.80 0.000 .3916528 .5890014
2 | .5604834 .049094 11.42 0.000 .463666 .6573007
------------------------------------------------------------------------------
用图形表示如下。这与我们在研究中通常想要分析的情况是不一致的。
reg write socst i.female#c.socst
qui margins female, at(socst=(5(5)70))
marginsplot, recast(line) noci addplot(scatter y x,jitter(3) msym(oh))
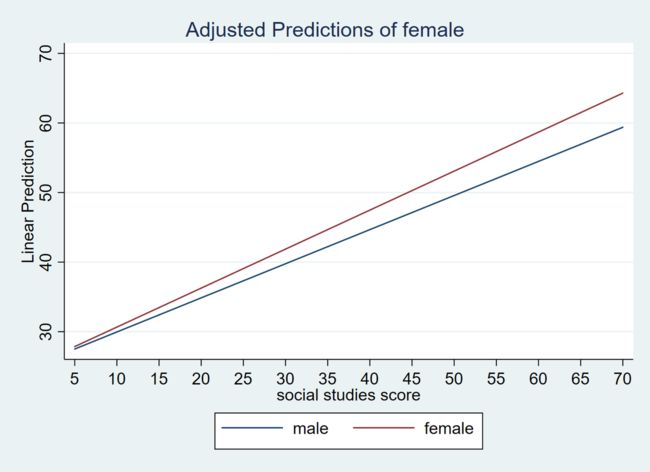
- 模型 4:只保留交互项
. reg write i.female#c.socst
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(2, 197) = 66.96
Model | 7235.18229 2 3617.59115 Prob > F = 0.0000
Residual | 10643.6927 197 54.028897 R-squared = 0.4047
-------------+---------------------------------- Adj R-squared = 0.3986
Total | 17878.875 199 89.843593 Root MSE = 7.3504
--------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------------+----------------------------------------------------------------
female#c.socst |
male | .4903271 .0500357 9.80 0.000 .3916528 .5890014
female | .5604834 .049094 11.42 0.000 .463666 .6573007
|
_cons | 25.0561 2.597064 9.65 0.000 19.93449 30.17772
--------------------------------------------------------------------------------
该模型类似于模型 3,也是我们不建议使用的模型。可以发现,该回归结果与模型 3 的结果是一致的,汇报的是假设不同组别截距项相同的情形下,不同组别的斜率。系数与 margins, dydx(socst) at(female=(0 1)) noatlegend post 汇报的也是一致的。
3. 实例 3:连续型变量相互交乘 (Continuous by Continuous Interaction)
- 完整模型
. reg write c.math##c.socst
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(3, 196) = 61.55
Model | 8672.71872 3 2890.90624 Prob > F = 0.0000
Residual | 9206.15628 196 46.9701851 R-squared = 0.4851
-------------+---------------------------------- Adj R-squared = 0.4772
Total | 17878.875 199 89.843593 Root MSE = 6.8535
--------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------------+----------------------------------------------------------------
math | .6107585 .2871688 2.13 0.035 .044421 1.177096
socst | .5206108 .2675933 1.95 0.053 -.007121 1.048343
|
c.math#c.socst | -.0036057 .0051493 -0.70 0.485 -.0137609 .0065494
|
_cons | 3.483233 14.32252 0.24 0.808 -24.7628 31.72927
--------------------------------------------------------------------------------
常数项为 math = 0, socst = 0 时,全样本的写作平均分数。 交乘项的含义为当 math 或者 socst 变化一单位时,writing 对 socst 和 math 做回归的斜率的变动。
我们可以用图形表示。
reg write c.math##c.socst
margins, at(math=(30 75) socst=(30(5)70)) vsquish
marginsplot, noci x(math) recast(line)
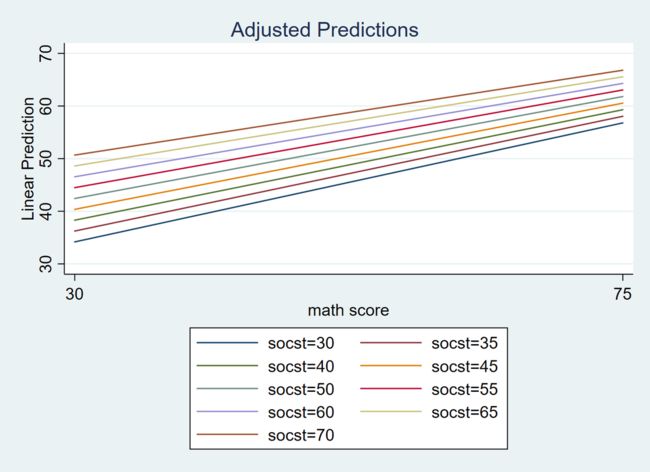
- 模型 2:去掉主效应项
c.math
回归结果如下所示。
. reg write c.socst##c.math
Source | SS df MS Number of obs = 200
-------------+---------------------------------- F(3, 196) = 61.55
Model | 8672.71872 3 2890.90624 Prob > F = 0.0000
Residual | 9206.15628 196 46.9701851 R-squared = 0.4851
-------------+---------------------------------- Adj R-squared = 0.4772
Total | 17878.875 199 89.843593 Root MSE = 6.8535
--------------------------------------------------------------------------------
write | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------------+----------------------------------------------------------------
socst | .5206108 .2675933 1.95 0.053 -.007121 1.048343
math | .6107585 .2871688 2.13 0.035 .044421 1.177096
|
c.socst#c.math | -.0036057 .0051493 -0.70 0.485 -.0137609 .0065494
|
_cons | 3.483233 14.32252 0.24 0.808 -24.7628 31.72927
--------------------------------------------------------------------------------
此处,再次强调,引入主效应项的目的在于改变截距。我们可以用图形来感受这句话的含义。除非可以确认截距是一致的,不然在连续变量相互交乘的模型中,应该谨慎去掉主效应项。

总结
本篇推文讨论了三种情况下,在包含交乘项的回归中,主效应项是否可以去掉的问题。根据不同的情况,本文给出了不同的分析以及实证建议。
主要回归命令及实证建议归纳如下。
use https://stats.idre.ucla.edu/stat/data/hsbanova, clear \\数据引入
*- 类别变量相互交乘
regress write i.female##i.grp \\完整模型
margins female##grp
regress write i.grp i.female#i.grp \\模型 2:去掉主效应项 female
*无模型设定问题,但系数含义改变*
regress write i.female i.female#i.grp \\模型 3:去掉主效应项 grp
*无模型设定问题,但系数含义改变*
regress write i.female#i.grp \\模型 4:只保留交乘项
*无模型设定问题,但系数含义改变*
*- 类别变量与连续型变量相互交乘
regress write i.female##c.socst \\完整模型
regress write i.female i.female#c.socst \\模型 2:去掉主效应项 c.socst
*无模型设定问题,但系数含义改变*
reg write socst i.female#c.socst \\模型 3:去掉主效应项 i.female
*可能存在模型设定问题*
margins, at(female=(0 1) socst = 0) noatlegend
margins, dydx(socst) at(female=(0 1)) noatlegend post
reg write socst i.female#c.socst
qui margins female, at(socst=(5(5)70))
marginsplot, recast(line) noci addplot(scatter y x,jitter(3) msym(oh))
reg write i.female#c.socst \\模型 4:只保留交乘项
*可能存在模型设定问题*
*- 连续型变量与连续型变量相互交乘
reg write c.math##c.socst \\完整模型
margins, at(math=(30 75) socst=(30(5)70)) vsquish
marginsplot, noci x(math) recast(line)
reg write c.socst##c.math \\模型 2:去掉主效应项
*可能存在模型设定问题*
连享会计量方法专题……
关于我们
- 「Stata 连享会」 由中山大学连玉君老师团队创办,定期分享实证分析经验, 公众号:StataChina。
- 公众号推文同步发布于 CSDN 、简书 和 知乎Stata专栏。可在百度中搜索关键词 「Stata连享会」查看往期推文。
- 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- 欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- E-mail: [email protected]
- 往期推文:计量专题 || 精品课程 || 简书推文 || 公众号合集

