万台规模下的SDN控制器集群部署实践
本文根据华三通信研发副总裁王飓在2014年QCon上海的主题演讲《SDN控制器集群中的分布式技术实践》整理而成。
目前在网络世界里,云计算、虚拟化、SDN、NFV这些话题都非常热。今天借这个机会我跟大家一起来一场SDN的深度之旅,从概念一直到实践一直到一些具体的技术。
本次分享分为三个主要部分:
- SDN & NFV的背景介绍
- SDN部署的实际案例
- SDN控制器的集群部署方案
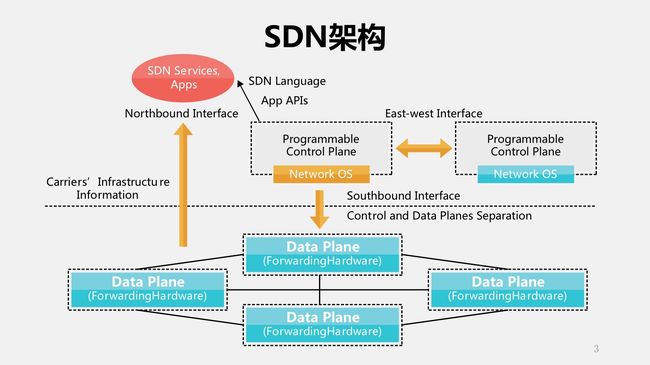
我们首先看一下SDN。其实SDN这个东西已经有好几年了,它强调的是什么?控制平面和数据平面分离,中间是由OpenFlow交换机组成的控制器,再往上就是运行在SDN之上的服务或者是应用。这里强调两个,控制器和交换机的接口——我们叫做南向接口;另一个是往上的北向接口。
SDN的核心理念有三个,第一个控制和转发分离,第二个集中控制,第三个开放的API——可编程、开放的API接口。单纯看这三个概念,我们很难理解为什么SDN在网络业界现在这么火。这三个概念就能够支撑起SDN的成功吗?所以我们要探寻一下SDN背后的故事。
SDN背后的故事
其实SDN在诞生之初,我们这些做网络的人对它不重视,最开始认为就是大学的教授搞出来的实验室里的玩具,并不认为会对产业界有大的影响,可是几年下来以后让我们每个人都大吃一惊,它发展太快了。这个背后有什么呢?
实际上在SDN的发展的几年当中有另外一个技术在迅速的发展,铺天盖地来到每个人的身边,就是云计算。说云计算我还想跟大家分享一个小故事,我前几天在公司准备QCon的胶片,我们公司的负责保洁的师傅说了,你做云计算啊?我说是啊,你也知道云计算?他说当然知道了,我经常用云计算,那我问他,你都怎么用的?他说上淘宝啊,经常买东西。然后我就问他了,那你知道淘宝应该算什么云吗?其实我问他这句话背后的含义是因为,在我们这个圈子里面把云分为公有云、私有云、混合云,我想问问他,结果他的答案非常让我震惊,淘宝你不知道吗?马云啊!所以我就深深的体会到了,起一个好的名字是非常重要的。
刚刚这个只是个笑话,体现了两个问题:第一个就是云计算现在地球人都知道,第二个就是每个人对云计算的理解又是不同的。我给云计算下了一个定义,就是使计算分布在海量的分布式节点上并且保持弹性,这么说可能比较抽象,再说的稍微形象一点就是说使资源池化,在你需要的时候可以按需索取、动态管理。
当人们围绕着按需索取动态管理做文章的时候,什么技术能达到这个要求呢?虚拟化技术。所以现在看云管理平台,OpenStack、CloudStack也好,都是围绕这三个方面——计算、存储还有网络的虚拟化做文章的。
在这股虚拟化的浪潮前面,计算虚拟化发展的最早也发展的最快,网络和存储的虚拟化就相对滞后一点。当人们把目光聚焦到网络虚拟化的时候,人们寻找解决网络虚拟化的方法和工具,这个时候SDN就出现在人们的视野里了。
刚刚讲的SDN三个理念:控制和转发分离可以使控制层面脱离对网络设备的依赖,可以快速发展;集中控制就很方便对资源进行池化和控制;开放的API——南向和北向接口——可以催生产业链,推动整个产业的快速发展。
开放的云计算数据中心解决方案都离不开SDN,从某种程度上讲,是云计算架构里面的基石,再讲另外一个话题,NFV也是比较热的话题,是网络功能虚拟化,和刚刚我讲的网络虚拟化就差一个字母,但是实际上阐述的是两个不同层面的概念。
我们讲了云计算需要网络虚拟化,实际上不是今天才有的,像我们做网络的人都知道在很久以前人们就有这种网络虚拟化的要求了,不过在那个时候我们管它叫VPN,虚拟专用网,以前使用的都是在一个公共的网络上虚拟出来一个专用的网络,让使用者以为这个网络就是给我专用的。
那么到了云计算时代,在我们讨论云数据中心的时候,就不再用原先的词了,现在说multi-tenant,多租户,其实道理是一样的,也是在一个公共的网络里隔离出来各个专用的网络。这个技术是什么?就是Overlay。数据层面看这俩技术没有本质的区别,都是实现了数据封装,方式就是在网上建立隧道把各个网络隔离开。
回头看NFV这个概念,就有点区别了:NFV是欧洲电信联盟提出来的。我们知道在运营商的机房里面看到成片的服务器、存储设备、还有大量的不同厂商不同的网络设备,云计算的时代这些运营商也不干了,这么搞太烦了,维护起来成本高,部署起来复杂,新业务上线很慢,他就强调能不能把这个世界搞得干净一点,机房当中只剩下三个设备:标准的交换机,标准的服务器还有标准的存储设备,除了这些设备,其他通通消失,把所有功能挪到标准的服务器上实现,强调网络功能的虚拟化。
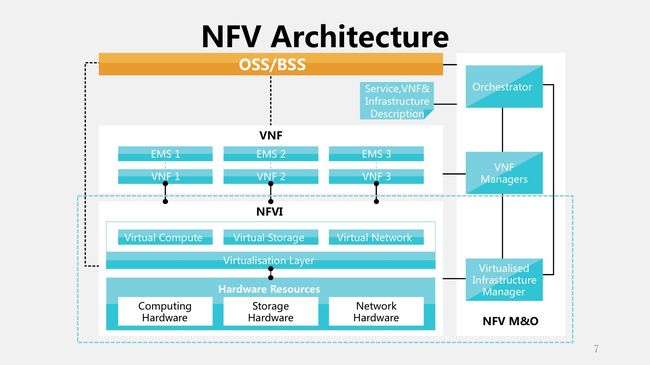
所谓功能的虚拟化就是说把这个功能从传统的网络设备里拿出来。这个是欧洲电信联盟给出的NFV的架构图,我们看这个架构图的时候发现,这个下面的部分称为NFVI,就是基础设施,进行管理和虚拟化,目标是为了在上面提供这些他称之为VNF的功能。强调一下,这是一个一个的功能单元,这些功能单元运行在虚拟化出来的虚拟机或容器里。最右边这一块就是整个系统的管理。

我们看这个图可能会感觉很熟悉,这个就是OpenStack的架构图。云管理平台玩的就是虚拟化,管理的是计算、存储和网络。对比前后这两张图我们发现,其实NFV的架构就是云计算的架构,只不过它所强调的仅仅是运行在云计算上的服务,而不像我们普通的比如Hadoop服务为了大数据,或者WEB和数据库等等。NFV的服务都是为网络功能服务的,包括DHCP地址分配、NAT地址转换、防火墙、无线接入、宽带接入、3G核心网等等,都可以用虚拟的容器实现。所以其实网络功能和我们大家平时所熟悉的这些标准的APP或者是这些服务都是一样的,都可以一样的进行虚拟化和云化。

所以从这个层面上讲,一个广泛意义上的网络虚拟化会看到几个热门技术:SDN、NFV、Overlay,都是从不同的层面支撑虚拟化——SDN定义了一种控制和管理的网络架构,Overlay提供了一种解决数据平面转发和多租户隔离的技术手段,NFV指出了我的网络功能如何借助这个架构实现虚拟化。这里就有一个循环:网络虚拟化包含了网络功能虚拟化,网络功能虚拟化又依赖于云计算的架构,一旦这个循环形成了,这些新技术在彼此之间不停的碰撞,相互结合也相互竞争,也构成了我们今天这样一个网络世界变革的大时代。
SDN的部署案例
下面给大家介绍一下我们在SDN领域的实际的案例。
在讲实际的案例之前,想先跟大家分享一下我们公司对未来网络发展的一个理解。我们知道现在SDN、NFV很热,但是传统的网络并不会消失,在很长的时间内这些技术会并存。我们强调一个什么概念呢?就是一个虚拟的融合架构。
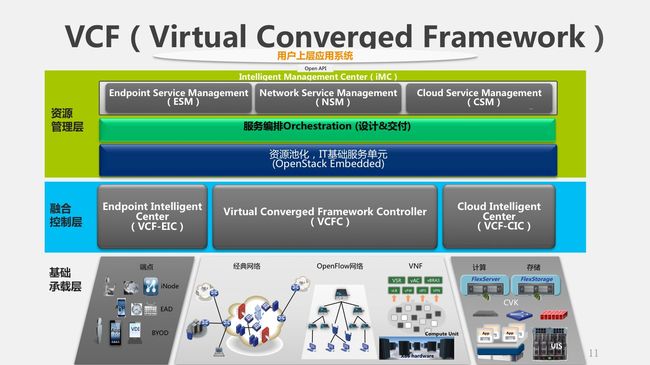
这个图是一个三横三纵的结构,我们从三纵开始。最右边就是云,解决的是计算存储的问题;最左边是端。有人最近提出来一个概念,说现在的网络是云计算和移动互联网的时代,云计算就是云,而移动互联网就是端。对端的管理,不管是什么样的网络,我们最终检验网络质量的标准是什么?最终用户的体验。如果你的网络解决不好这个问题,你这个网络就很难说是成功的网络——所以中间就是云和网的结合体,就是网络的主体。
我们再横向看三层。底下一层就是基础的设备,包括终端设备、网络设备还有计算存储,包括NFV虚拟出来的网络单元也可以当成逻辑的网络设备放这里。第二层就是所谓的融合控制层:我们认为在网络上应该有这样一个层次,既可以管网,也可以管云,也可以管端,这些都需要进行一定的集中控制。最上边的一层就是所谓的资源管理层,在这个里面第一要对所有的资源进行池化,比如OpenStack这样的管理平台;在这个之上要提供一个业务编排的系统,把这些逻辑的分散的资源单元串在一起,才能够为用户提供服务;再之上就是针对不同的网络服务提供一些管理组件。
这个VCF架构强调每个层次都要对上一层次提供开放的接口,最终对最上面用户的应用提供可编程、可控制的能力。这实际上强调的是什么?就是对端和云中的应用提供了一种自动化的编排和管理的能力。
这么说可能比较抽象,我举个具体的例子,比如说你的手机拿起来了要上网,当你的手机上网的时候,传统的网络就是AC,无线控制器做Wifi认证;但是在我们这样一个融合架构里面,对这个手机进行认证的设备就不再是AC控制器了,而是VCF的网络控制器。在这个网络控制器对这个手机进行认证、允许上网以后,就知道这个手机是谁的,应该有什么权限,可以获取什么资源,这个时候就要执行一个我们称之为user profile的服务模板,执行之后会控制整个网络里面所有的设备,根据这个用户上网这一个动作,它就可以对这个用户所需要的所有的资源进行调整。这在传统的网络里是很难实现的。
另一个例子,在云数据中心一款APP上线,一般就是VM或者是一个容器的创建。一般情况下在云管理平台里面,容器创建的时候就要分配和指定资源,包括什么资源呢?CPU、内存、硬盘、网络出口带宽、还有这个服务前面要不要加防火墙、是不是大的集群中的成员前面要放负载均衡、要不要给它备份管理等等等等,这些功能实际上存在一个叫做app profile的文件里。这样在整个云里面,不论是存储还是计算资源还是网络资源都被这个APP上线调动了,他会根据你预先编排好的需求,动态对所有的资源进行调整。我们以前做应用的人对网络施加一些控制是很难的,只能对网络管理员提出要求,让他实现;但是现在,我们就具备一种动态管理的能力,这就是这样一个概念带来的一个变革。
所以说,我们认为VCF这样的概念实际上就是我们对SDN这个概念的发展和补充,是我们认为未来网络发展的趋势。
像这样一个整网融合的方案会比较大,我们真正在商用的时候往往只会使用一部分。比如说我们在给一个数据中心做方案的时候,可能重点关注于你的云和网;如果给一个城域网做方案,可能就是关注网;如果是给园区做网,就是关注端和网的管理。
下面我就给大家讲两个实际的案例。
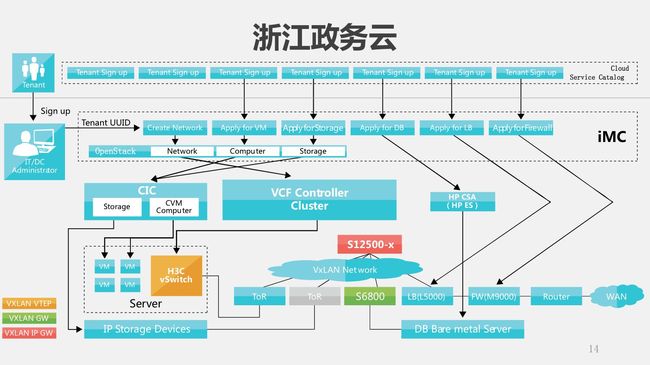
第一个,浙江政务云。这个项目包含两个部分,一个是公有云,一个是政务云,公有云由阿里云承担,政务云由我们公司承建。我们看一下结构,在这个图里面我们会发现,有计算、存储,中间是一个由核心交换机和边缘交换机构成的网络把这些全部连接起来,同时还有网络的管理控制器和云的管理控制器,之上就是iMC——一个更高层的资源编排和管理软件。上面的OpenStack没有直接管理交换机,而是通过往OpenStack里面注入插件,把控制功能转给了控制器,包括云控制器和网络控制器,然后再去管理物理的设备。这样有什么好处呢?保留了开源云管理平台OpenStack的开放性,第三方应用可以用同一个API来做控制;而同时因为使用了专用的控制器,效率会有进一步的提升。
这个专用控制器就是SDN和Overlay技术的实现,可以对外控制三种网络角色:VxLAN VTEP控制虚拟化的vSwitch,VxLAN GW控制数据中心内的边缘交换机,VxLAN IP GW控制对外界连接的网关——核心交换机。
Overlay这个技术有一个特点,就是它初始化的时候,所有节点上的流表是空的。在什么时候才形成转发控制的能力呢?是随着业务的部署形成的。比如说当有一个VM想跟另外一个通讯的时候,第一个报文就被vSwitch捕获,然后分析一下,就知道应该从哪个虚机到哪个虚机,在源和目的的之间建立一个隧道下发流表,把这个初始的报文返给vSwitch,这样就过去了。
这样处理有甚么好处呢?最大的好处是节约资源。我们知道像这样的数据中心可能有几千或者几万个节点,就是几十万个虚拟机,如果让任意两个VM之间都可以通的话,大家算一下要多少的流表——这个资源是有限的。实际上不会所有的VM之间都有通讯的要求,根据业务部署可能只有很少数量的VM之间才会通信的要求,所以这样的方案很节省流表的资源。这个方案如果说有缺点的话是什么呢,因为它的这个首包上送给了控制器,越到后期在控制器这块的压力就会越来越大。这个问题怎么解决我们后面讲。
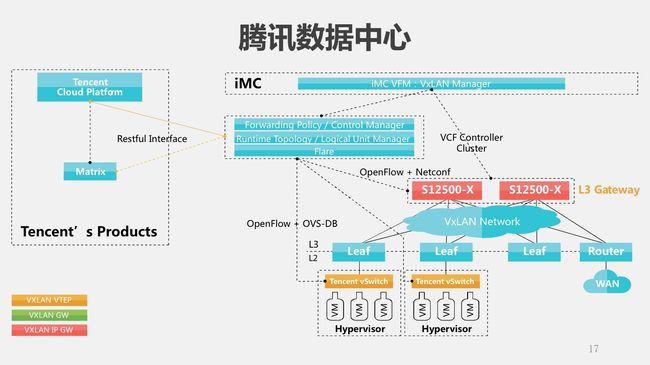
再看腾讯的这个方案。腾讯数据中心的情况是,他们自己已经有云管理平台,有自己的vSwitch,只是需要我们的物理交换机和控制器。这个方案展开一看大家会发现跟我刚刚讲的这个浙江政务云的方案其实是很类似的,也是SDN加Overlay的方案。只不过在这个方案里面,第一,不是所有的设备都是我们的,所以需要我们在我们的控制器上面有一些东西跟腾讯的云管理平台进行对接;第二,就是规模的问题,腾讯让我们建立这样的数据中心到什么规模呢?物理的服务器一万五千台。这给我们整个管理带来了很多的挑战,我们怎么才能部署控制器管理一万五千台的服务器,几十万的虚机?下面讲一下我们这个集群管理的部署方案以及具体的优化。
SDN Controller集群部署方案以及优化
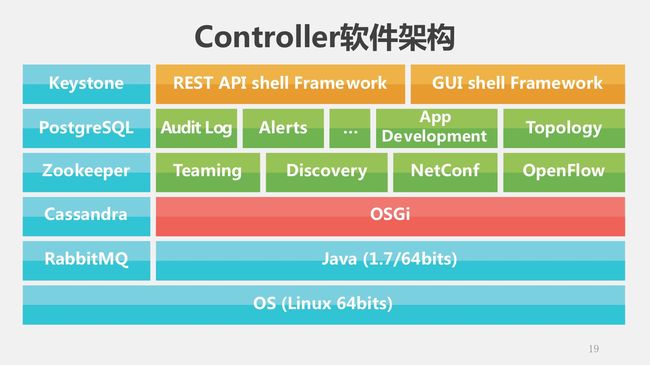
讲解控制器部署之前,我们花一点时间进入控制器软件的内部,看看这个Controller的软件架构。可以看到我们也用一些开源的工具,然后之后呢还有一些各种层面的模块。我们去看一下具体的逻辑图,可能看的更清楚一点。
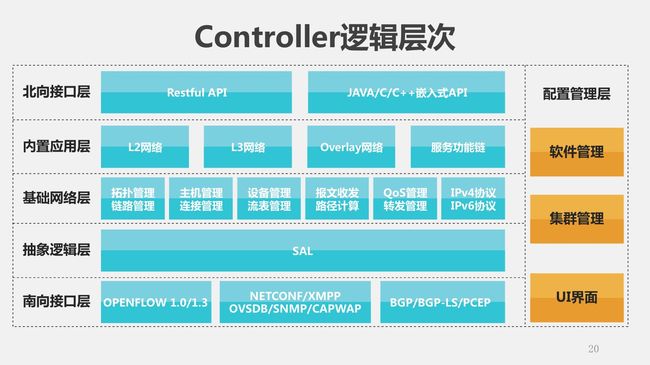
我们把控制器分成不同的层次:最下面我们称之为南向接口层,有OpenFlow、NetConf/XMPP、BGP等等不同的数据协议,这是因为控制器往下要管理不同的节点,这些不同的角色(vSwitch或物理交换机)使用的协议不一样。
第二层是SAL适配层,这一层屏蔽了不同的厂商/不同的设备对南向提供接口的差别,让上层的模块运行起来可以仅仅针对他关心的业务处理,而不用关心不同厂商的API有什么差别。
再往上就是基础的网络功能模块,这一块没什么说的。再往上就是内置应用。在SDN里面有两种应用,一种是内置的应用——就运行在SDN的控制器上,还有一种外置的应用——在上面。我们看到这里有Overlay模块:最关键的计算都是由这个Overlay模块完成的。
再往上就是北向接口层了,就是可编程的控制器要对外提供一个良好的编程接口。
还有一部分就是管理层,有软件的管理、软件自身的升级、增加模块,还有生命周期管理、集群的管理,还有一些UI的界面。

讲完这个层次图以后,回到刚刚的问题上。我们Overlay的过程——送给控制器,下发流表把这个包返回给vSwitch进行转发,这个是一次首包上送。这个方案所造成的问题就是对控制器的计算能力提出挑战。所以我们在这个方案里面重点优化首包上送的处理能力,对刚刚的结构不停的优化、进行重构。
最后我们做到什么性能呢?标准的Intel i7 4核处理器上,可以做到500k的处理能力。在这个基于Java的架构上,我想再做出质的提升恐怕就很困难了。
那么这一个控制器能管理多大的网络?瓶颈在首包上送的能力,我们可以计算一下:一个服务器有1个vSwitch,跑20-30个VM,每秒大概可以产生500以上的新流,就是每秒有500次跟一个新的、不同的设备通信。那么用我们刚刚的首包上送一除就知道,500K的TPS性能,一个控制器大概可以管理一千个Host;当一个数据中心规模在15k的时候,单节点控制器肯定搞不定了,就需要控制器集群。
我们把所有的控制器就是称之为一个团队(team),一部分成员是领导者(leader),一部分是成员(member)。Leader对上提供北向的访问接口,负责对cluster进行管理;Member就负责管理控制交换机,连接交换机的方式就是刚刚讲的南向接口。
单一的节点可能会不安全或者是不可靠,所以就提供了另外一个东西就是Region。我们把所有的leader放在一个Region里,作为主集群,其他的作为备份,这样就保持这个集群有一个持续的不间断的对外提供北向接口的能力。下面这些member划了一个一个Region,一个Region中有多个Member,Switch要同时连接到一个 Region中的所有Member上,并选取一个作为主。这样的好处是什么呢?一个switch有多个member,如果我的主域宕掉了,这个switch发现了以后就可以从剩余的里面选择一个新的,备变为主,这样就可以提供一个不间断的服务能力。
我们拿两台服务器做主,然后划分15个Region,一个控制器可以管理一千台的服务器,15个正好是15000台。总的来说就是对控制器进行分层的设计,让leader提供向北接口,member提供向南接口。
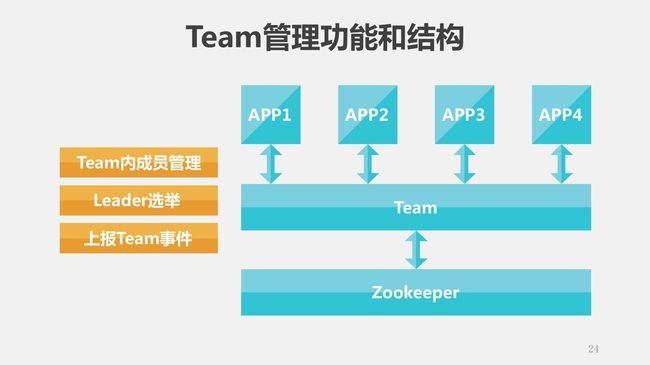
简单介绍一下我们实现这个集群采用的技术。Team管理功能,是在Zookeeper之上封装的,这个Team实现了成员管理、leader选举、上报Team事件,具体的方式是很标准的Zookeeper使用方式,这个就不多说了。
那么还有一个重要的问题,不是说你的成员加入集群就完事儿了,我刚刚讲腾讯的方案的时候,腾讯的云管理平台上有大量的VM的信息,这些需要你做一个模块抓取过来,要在你所有的控制器之间共享,所以说就需要有一些数据在所有的控制器间共享,也就是HA。按照我们做网络的习惯,我们把HA分成两种功能,一个是实时备份,一个是批量备份,目标就是希望这个HA系统对上述的APP是不可见的,具体看一下实现。
第一个就是BUS,它提供通讯的通道,当你写入一个数据的时候,就在主那里创建一个单元,发现这个节点发生变化,就把这个单元读出来,这个数据就传过去了。
KeyStore,实现了一个非常简单的数据库功能,采用Key-Value机制,不支持范围查找,只提供了设置和获取接口,没有通知接口。有的同学会问了,说你们跟Zookeeper干上了是吧?那我们做开发的人都知道,当我们熟悉一个工具的时候,就会很自然的重复使用,尽量用熟为止。
实际使用当中的实时备份过程就是这样的,很简单,集群中某个成员业务数据变化时,发送bus消息通知其他成员,同时将本成员的运行数据以key&value的形式保存在KeyStore中。
批量备份就是当新的控制节点加入时,KeyStore就会自动将其他节点的数据备份到本地,App需要先从KeyStore中恢复数据,当恢复完成后,再开始接收bus消息。做keyStore数据恢复时,要求bus可以从批备开始的时间点开始缓存bus消息,等恢复完成后补报这些bus消息,这样就可以保证了最终数据的同步。
今天跟大家分享的话题就到这里,谢谢大家!