《计量经济学》学习笔记之一元线性回归模型
注意:本笔记以文字概括为主,公式为辅,问为啥,因为贴图片和打公式对于我来说,太烦啦~所以,就只把每个章节里觉得重要的一些概念记下来。
书籍:《计量经济学(第三版)》–李子奈
导航
下一章:多元线性回归模型
文章目录
- 导航
- 经典单方程计量经济学:一元线性回归模型
- 2.1回归分析概述
- 一、回归分析基本概念
- 二、总体回归函数
- 三、随机干扰性
- 四、样本回归函数
- 2.2一元线性回归模型的基本假设
- 2.3一元线性回归模型的参数估计
- 四、最小二乘估计量的统计性质
- 五、参数估计量的概率分布及随机干扰项方差的估计
- 2.4一元线性回归模型的统计检验
- 一、拟合优度检验
- 二、变量的显著性检验
- 三、参数的置信区间估计
- 2.5一元线性回归分析的应用:预测问题
经典单方程计量经济学:一元线性回归模型
2.1回归分析概述
一、回归分析基本概念
●各种经济变量间的关系可分为两类:一类是确定的函数关系,另一类是不确定的统计相关关系。
●相关分析与回归分析主要研究非确定性现象间的统计相关关系
●回归分析的目的在于通过解释变量的已知值或设定值,去估计和预测被解释变量的(总体)均值
●相关分析与回归分析的联系与区别:
①首先,两者都是研究非确定性变量间的统计依赖关系,并能度量线性依赖程度的大小。
②其次,两者间又有明显的区别。相关分析仅仅是从统计数据上测度变量间的相关程度,而无须考察两者问是否有因果关系,因此,变量的地位在相关分析中是对称的,而且都是随机变量;回归分析则更关注具有统计相关关系的变量间的因果关系分析,变量的地位是不对称的,有解释变量与被解释变量之分,而且解释变量也往往被假设为非随机变量。
③再次,相关分析只关注变量间的联系程度,不关注具体的依赖关系:而回归分析则更加关注变量间的具体依赖关系,因此可以进一步通过解释变量的变化来估计或预测被解释变量的变化,达到深入分析变量间依存关系,掌握其运动规律的目的。
●回归分析的主要内容:
①根据样本观察值对计量经济学模型参数进行估计,求得回归方程
②对回归方程、参数估计值进行显著性检验
③利用回归方程进行分析、评价及预测
二、总体回归函数
●在给定解释变量X条件下被解释变量Y的期望轨迹称为总体回归线。或更一般地称为总体回归曲线。相应的函数:
称为(双变量)总体回归函数.总体回归函数表明被解释变量Y的平均状态(总体条件期望)随解释变量X变化的规律。至于具体的函数形式,是由所考察总体固有的特征来决定的。
●线性总体回归函数:
其中,β0和β1是未知参数,称为回归系数。线性函数形式最为简单,其中参数的估计与检验也相对容易,而且多数非线性函数可转换为线性形式,因此,为了研究的方便,计量经济学中总体回归函数常设定成线性形式。
●经典计量经济方法中所涉及的线性函数,指回归系数是线性的,即回归系数只以它的一次方出现,对解释变量则可以不是线性的。
三、随机干扰性
●随机干扰项μ:
●总体回归函数的随机形式:
●在总体回归函数中引入随机干扰项,主要有以下几个方面的原因:
①代表未知的影响因素
②代表残缺数据
③代表众多细小影响因素
④代表数据观测误差
⑤代表模型设定误差
⑥变量的内在随机性
当随机干扰项仅包含上述③和⑥时,称为“原生”的随机干扰,是模型所固有的;当随机干扰项包含上述①②④⑤,称之为“衍生”的随机误差,是在模型设定过程中产生的。
四、样本回归函数
●由于样本取自总体,可用该直线近似地代表总体回归线该直线称为样本回归线,其函数形式记为:
![]()
称之为样本回归函数。
●同样地,样本回归函数也有如下的随机形式:
![]()
其中,e称为(样本)残差(或剩余)项,代表了其他影响Y的随机因素的集合。由于方程中引入了随机项,成为计量经济学模型,因此也称之为样本回归模型。
2.2一元线性回归模型的基本假设
●为了保证参数估计量具有良好的性质,通常对模型提出若干基本假设:
对模型设定的假设:
①回归模型是正确设定的
对解释变量的假设:
②解释变量X是确定性变量,不是随机变量,在重复抽样中取固定值
③解释变量X在所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X的样本方差趋于一个非零的有限常数。
对随机干扰项的假设:
④随机误差项u具有给定X条件下的零均值、同方差以及不序列相关性。
⑤随机误差项u与解释变量X之间不相关
⑥随机误差项服从零均值、同方差的正太分布。
以上假设也称为线性回归模型的经典假设;而前4个假设也称为高斯马尔科夫假设。
2.3一元线性回归模型的参数估计
●常见的估计方法有3种:
普通最小二乘法(OLS)
最大似然法(ML)
矩估计法(MM)
四、最小二乘估计量的统计性质
●估计量的统计性质:

前3个准则也称为有限样本性质,或者小样本性质。拥有这些性质的估计量称为最佳线性无偏估计量(BLUE)
后3个准则称为估计量的无限样本性质或大样本渐进性质。如果有限样本情况下不能满足估计的准则,则应该扩大样本容量,考察参数估计量的大样本性质。
五、参数估计量的概率分布及随机干扰项方差的估计
●为了达到对所估计参数精度测定的目的,还需进一步确定参数估计量的概
率分布。


2.4一元线性回归模型的统计检验
●在一次抽样中,参数的估计值与真值的差异有多大,是否显著,这就需要进一步进行统计检验,主要包括拟合优度检验、变量的显著性检验及参数的置信区间估计。
一、拟合优度检验
●拟合优度检验,顾名思义,是检验模型对样本观测值的拟合程度。
●有人也许会问,采用普通最小二乘法进行估计,已经保证了模型最好地拟合了样本观测值,为什么还要检验拟合程度呢?
最小二乘的确是拟合最好地,但我们也要找出拟合程度有多大。
●可决系数R2统计量:
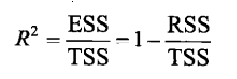
TSS为总离差平方和,ESS为回归平方和,RSS为残差平方和。
检验模型的拟合优度,称R2为可决系数(coefficient of determination)。显然,在总离差平方和中,回归平方和所占的比重越大,残差平方和所占的比重越小,回归直线与样本点拟合得越好。如果模型与样本观测值完全拟合,则有R2=1。当然,模型与样本观测值完全拟合的情况很少发生,R2=1的情况较少。但毫无疑问的是该统计量越接近于1,模型的拟合优度越高。
二、变量的显著性检验
●变量的显著性检验,旨在对模型中被解释变量与解释变量之间线性关系是否显著成立作出判断,或者说考察所选择的解释变量是否对被解释变量有显著的线性影响。
●变量的显著性检验所应用的方法是数理统计学中的假设检验。
三、参数的置信区间估计
●假设检验可以通过一次抽样的结果,检验总体参数可能值的范围,但它并没有指出在一次抽样中样本参数值,到底距总体参数的真值有多近。往往我们要构造一个以样本参数的估计值为中心的“区间”,来考察它以多大的可能性包含着真实的参数值。
●如何才能缩小置信区间?
①增大样本容量n
②提高模型的拟合优度
2.5一元线性回归分析的应用:预测问题
●预测在更大的程度上说是一个区间估计问题,我们得到的仅是预测值的一个估计值,预测值仅以某一个置信度处于该估计值为中心的一个区间里。
●对于被解释变量Y的总体均值E(Y0)与个别值Y0的预测区间,有:
①样本容量n越大,预测精度越高,反之预测精度越低。
②样本容量一定时,置信带的宽度在X的均值处最小,在其附近进行预测(插值预测)精度高;X越远离其均值,置信带越宽,预测精度将降低。