Java基础面试题
JDK:java development kit: Java开发工具包,包括了JRE,提供有一堆Java工具(javac/java/jdb等)和Java基础的类库(即Java API 包括rt.jar)
JRE:Java runtime environment:java运行时环境,包括有Java的JVM,runtime class libraries和Java application launcher,这些是运行Java程序的必要组件。
JVM:java virtual machine:就是我们常说的java虚拟机,它是整个java实现跨平台的最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行。
也就是说class并不直接与机器的操作系统相对应,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解释给本地系统执行。
只有JVM还不能成class的执行,因为在解释class的时候JVM需要调用解释所需要的类库lib,而jre包含lib类库。
JVM屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
######## 图解:  ##### 2.main方法能否声明为private
根据Java语言规范,main方法必须声明public(可参考Java语言规范的官方文档),不过,当main方法不是public时,某些版本的Java解释器也可以编译通过,在[Java Bug库](http://bugs.java.com/bugdatabase/index.jsp) 中输入bug号4252539可以查看,这个bug被标明“关闭,不予修复”,sun公司工程师解释说:“Java虚拟机规范工并没有强制要求mian方法为public,并且“修复这个bug有可能带来其他的隐患”,不过,在Java SE 1.4版本后强制mian方法为public
3.&和&&的区别:
4.不通过中间变量交换两个变量的值
class one{
int a=10;
int b=20;
a=a+b;//a=30
b=a-b;//b=10
a=a-b;//a=20
}
class two{
int a=10;
int b=20;
a=a*b;//a=200
b=a/b;//b=10
a=a/b;//a=20
}
class three{
int a=10;
int b=20;
a=b+(b=a)*0;
}5.Java中跳出当前的多重循环
break? 只能跳出当前层循环
跳出多重循环要label/flag标签;
class Test{
public static void main(String[] args){
mark://标签,下面break mark
for(int i=0;i<10;i++){
for(int j=0;j<10;j++){
if(i==j){
break;//只能跳出当前层
break mark;//跳出到标记层
}
}
}
}
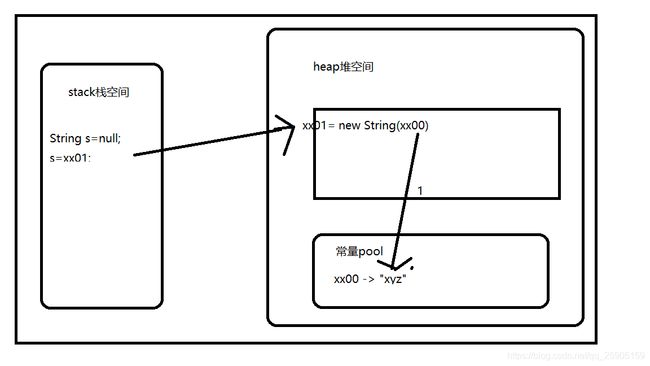
}6.String s=new String(“xyz”)创建了几个String Object;
创建了可以是一个,可以是两个对象,先创建了个常量,又在栈中创建了引用指向堆中地址为xx01的对象
class Test{
public static void main(String[] args){ //入栈,main方法中的所有代码同处一个内存空间
String s1=new String("xyz");//创建了2个对象
String s2="xyz";//创建了0个字符串对象,指向了s1创建的常量对象
String s3=s2;//创建了0个字符串对象,s3指向了s2,最终指向s1的常量对象
String s4=new String("xyz");//创建了1个,因为常量池中已有xyz
System,out.print(s2=="xyz");//return true
System,out.print(s1==s4);//return false 指向不同堆地址
System,out.print(s1==s2);//return false s1在堆中创建对象指向常量池而s2直接指向常量池
System,out.print(s1=="xyz");//return false 与上题一致
}
}
7.hashCode和equals的关系
重写过hashCode和equals吗?
为什么重写equals时必须重写hashCode?
hash是散列的意思,即把任意长度的输入,通过散列算法转换成固定长度的输出,该输出就是散列值
1.不同关键字经过散列算法变换后可能会得到同一个散列地址,这种的称为Hash碰撞
2.如果两个Hash值不同,(前提是同一个Hash算法)那么这两个Hash值对应的原始输入必定不同
HashCode()的作用:为了获取哈希散列码,返回int型整数
1.HashCode的存在主要是为了提高在散列结构中查找的效率,在线性表中没有作用
在HashMap中put里调用了hashCode算法,那么get肯定也有,int比对肯定比String比对要快。即先用hash懂得确定一个范围。
2.两个相等对象分别调用equals时都会返回true
3.如果两个对象equals() return true,则HashCode一定相同
4.两个对象Hash Code相同,不代表两个对象相同,只能说明这两个对象在散列存储结构中处于相同的位置
5.因此equals方法被覆盖,则HashCode方法也必须被覆盖
6.hashCode的默认行为是在堆中的对象产生独特值
7.Integer的HashCode是它自身
8.求最大公约数和最小公倍数
class Test{
public static void main(String[] args){
int a=10;
int b=20;
int min=a>b?b:a;
int result=0;
for(int i=min;i>1;i--){
if(a%i==0 && b%2==0){
result=i;
break;
}
}
System.out.print(result);
}
}面向对象方面:
1.Java和C++的区别
都是面向对象,但C++提供指针使程序员可以直接操作内存,同时也要手动进行垃圾回收,C++可以多继承。
2.简述面向对象的特征
封装:将对象的属性和方法隐藏,提供外部访问接口,保证安全性
继承:在原有类的基础上创建新的类,不改变原有的类,对原有类进行重写或扩展,实现更复杂的功能。提高程序的可扩展性。
多态:程序运行过程中不确定的状态,在实际编码中,我们将子类的引用指向父类,在传入参数时我们传的是父类的引用,在执行是才确定这个引用会指向哪个类的实例。在编译时不确定。
2.重载和重写
重载:在一个类中,不存在继承关系,是编译时多态,方法名相同,参数列表不同,方法返回值和访问修饰符可以不同,但我们不能根据返回值相同与否来判断重载。因为无法确定上下文的调用,不知道调用的哪一个。除非编译器能够有判断上下文调用的机制
重写:存在继承关系,方法名,参数列表必须相同,返回值范围和抛出异常范围小于等于父类,访问修饰符的范围大于等于父类。
构造器能否被重写
在继承方面,父类的构造器和私有属性并不能被继承,因此构造器不能被重写。(不能存在继承关系自然不能被重写)
静态变量和实例变量的区别
首先语法上静态变量要用static修饰
在程序运行时:实例变量需要创建了(new)实例对象才可以使用,静态变量不属于某个对象,而是属于类,也叫类变量,只要程序加载了类的字节码,不用创建任何实例对象就可以被分配空间。
总之实例变量需要创建对象才可被使用,而静态变量可以通过类名直接调用。
一个静态方法中不能调用类中的非静态的方法和变量
static修饰的变量在类加载后在内存中只有一份内存空间,可以被一个类的所有实例对象所共享
Java类的初始化顺序
class Test{
public static void main(String[] args){
new B();
}
}
class A{
}
class B extends A{
}类的大致加载顺序:
静态块,普通方法块,构造方法,成员变量
实际顺序:
父类的静态代码块 || 父类的静态成员 --->子类的静态代码块 || 子类的静态成员 --->
父类普通代码块 || 父类的普通成员 ---> 父类的构造方法 --->子类的普通代码块 || 子类的普通成员---> 子类的构造方法
String 为什么时final的,String,StringBuilder,StringBuffer的区别
- 被final修饰的对象不能被改变,保证了被修饰属性的安全性。
- 为了字符串常量池更好的存储字符串。
上文提及被final修饰的对象不能被改变,是引用(对象的地址)不能变。
StringBuffer是线程安全的,多线程环境使用
StringBuilder非线程安全, 单线程使用,不同步,效率高
String放在常量池,本身就是线程安全的,但String不可变。适合操作少量数据
描述值传递和引用传递
Java中只有值传递,
class Test{
public static void main(String[] args){
int age=20;
changeAge(age);
System.out.print(age);//结果为20,是因为此时传值到方法中,产生了一个副本
//方法中修改的值是副本的值。
User u=new User();
u.setAge(20);
changeAge(u);
System.out.print(u.getAge());//结果为30,但传递的也不是引用,
//而是对象的物理内存地址
}
private static void changeAge(int age){
age=age+10;
}
private static void changeAge(User u){
int temp=u.getAge()+10;
u.setAge(temp);
}
}
class User{
private int age;
get/set...
}局部变量使用前要显式的赋值,否则编译不能通过,为啥这样设计
成员变量的赋值是由JVM操作的,可以在方法执行前后赋值,这个是在运行时发生的。
局部变量的赋值是交给编译器做的为了给编码人员一个约束,避免犯错。
自动装箱和拆箱(语法糖),==和equals
装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
Integer的缓存在-128-127,不在范围内则重新new一个Integer。
==:比较的是两个对象的内存地址是否相同,基本数据类型比较的是内容。
equals:两种情况:
- Object类中原生的equals)(),比较的是两个对象的地址
- 其他类对equals()进行了重写,就看具体情况
比较包装类型用equals
异常处理方面
final,finally,finalize的区别
final修饰类,方法,属性,都是最终的,不可被继承,重写,修改。(String和Math)
finally:用于异常处理,正常情况下都会被执行,除非在此之前遇到了错误或两次return;
finalize:是Object类中的方法,调用此方法会通知GC进行垃圾回收,只是通知,不是立即执行,因此当调用此方法后对象已经被GC处理了,就会报一些错误,因此不推荐使用。
Error和Exception的区别:
首先,Error类和Exception类都是继承Throwable类首先,Error类和Exception类都是继承Throwable类
- Error(错误)是系统中的错误,程序员是不能改变的和处理的,是在程序编译时出现的错误,只能通过修改程序才能修正。一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
- Exception(异常)表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
- CheckedException:(编译时异常) 需要用try——catch显示的捕获,对于可恢复的异常使用CheckedException。(编码过程中编译器会报错)
我们在编写程序过程中try——catch捕获到的一场都是CheckedException。
io包中的IOExecption及其子类,都是CheckedException。 - UnCheckedException(RuntimeException):(运行时异常)不需要捕获,对于程序错误(不可恢复)的异常使用RuntimeException。(编码时不会报错但运行时报错)
illegalArgumentException:此异常表明向方法传递了一个不合法或不正确的参数。
illegalStateException:在不合理或不正确时间内唤醒一方法时出现的异常信息。换句话说,即 Java 环境或 Java 应用不满足请求操作。
NullpointerException:空指针异常(我目前遇见的最多的)
IndexOutOfBoundsException:索引超出边界异常
- CheckedException:(编译时异常) 需要用try——catch显示的捕获,对于可恢复的异常使用CheckedException。(编码过程中编译器会报错)
try{}中有return ,finally会不会执行,是在return前还是return后
会执行,会在return 执行中执行。
try{
int a=1/0;
return 0;
}catch (Exception e){
return 1;
}finally{
return 2;
}
最终结果为:1;
因为:try中有异常,到了catch中,return 1执行,但并不会直接返回值,进入finally,执行完后
‘返回catch中的返回值。简述Java中异常处理机制的原理和应用
Java异常处理机制保证了程序的健壮性,用它来避免我们错误操作的出现。
应用:做支付时突然断网,这是就要给用户做出提示,这就是应用。
有无自定义异常,为什么自定义异常
在调用支付宝接口时会发现它有很多错误码。后来发现这就是他们定义的自定义异常,为保证程序的健壮性,我们可以去找它的错误码去改BUG。
集合框架部分:
List,Set,Map三者的区别
- 类结构:
List,Set都实现了Collection接口
Map是个顶层接口。 - 元素重复:
List可以重复,可以添加空值,有序,可根据下标存取
Set不可以重复,可以添加一个空值,无序
Map:key-value:key只能有一个空值,value可以有多个空值。默认无序,根据key的hash码查找
ArrayList,LinkedList,Vector的存储性能和特性
ArrayList是在List下的AbstractList下,与Vector平级,LinkedList是在他俩的下一级。
Vector是线程安全的实现(同步)数组增强版,可通过下标访问;利于查询,不利于插入
ArrayList非线程安全(非同步),数组增强版,可通过下标访问;效率较高;利于查询,不利于插入,实现的RandomAccess,执行随机访问
LinkedList:非同步,双向链表,通过节点访问node,node与node之间存在指向关系。利于输入,不利于查询。
查询量大用ArrayList和Vector,多线程用Vector
插入量大用LinkedList
HashMap和HashTable区别
都是实现Map接口
HashMap:继承自AbstractMap,(数组+链表+红黑树(JDK8))初始化容量为16(合数),非同步,效率高,但多线程下造成死循环
HashTable:继承自Dictionary,初始化容量为11(素数),同步,每次枷锁访问阻塞,效率变低。
ConcurrentHashMap:(JDK1.5提出的)
解决多线程下的安全和效率问题,
JDK1.8之前采用的是分段锁技术,之后采用的是CAS保证一致性。
HashSet如何保证不重复
HashSet底层就是HashMap,实际上是利用了HashMap的key不能重复,值就是个Object。
(ConcurrentHashMap中的get,clear, 迭代都是弱一致性,
强一致性是什么?就是我们在添加进去之后,再get,肯定能get到)
Iterator
Iterator使用场景:遍历集合框架(LinkedList,ArrayList,Set)
ArrayList:根据下标添加,默认加到最后,
LinkedList:与ArrayList相似,默认加到最后。
Set:底层是put
知道数据结构为List的情况下,使用一个可以添加的迭代器:ListIterator
/**
为什么有remove()而没有add()? 因为有的集合是无序的,不知到加到那去
ArrayList
**/
LinkedList<String> linked=new LinkedList<String>();
Interator<String> iterator=linked.iterator();
while(iterator.hasNext()){
String next=iterator.next();
iterator.remove();
//在遍历时移除元素用迭代器
}Iterator和Iterable的区别:
Collection所有子类都具有返回Iterator的能力
Interator负责数据结构的迭代,获取数据(1.2引入)
Iterable表示数据结构拥有迭代的能力(1.5引入)
为什么要引入able?
Interable中包含一个Iterator,iterator重实现,Iterable更多的是给一个规范。
Enumeration和Iterator
枚举:一个个举例拿出来,意思就是迭代。JDK1.0即引入;不能remove
Vector和HashTable都实现了Enumeration枚举功能。
Iterator<String> iterator=vector.iterator();
while(iterator.hasNext()){
String next=iterator.next();
}
Enumeration<String> elements=vector.elements();
while(elements.hasMoreElements()){
String nextElement=elements.nextElement();
}当遍历集合想remove元素时,用集合的remove方法会抛异常,应该用iterator的remove。因为元素移除之后,下标就不准了。
会抛出ConcurrentModificationException,foreach是Iterator的简单实现。
在迭代器迭代时,不能对该数据进行更改,如果发生更改,就造成我们迭代出的数据不一致。
fail-fast:快速失败,是一种检测机制。
modCount():表示集合发生了多少次更改,更新次数。
expectedModCount():是迭代器自己声明的标记。
java.util下的集合框架中使用Iterator迭代器,都是采用的fail-fast,更改的为数据本身
java.util.concurrent包下的集合都是 fail-safe,安全失败,更改的数据为副本,占用空间比较大
在多线程情况下,如果一个线程在迭代该数据,如果使用Iterator,会造成modCount和expectedModCount不一致。
更多的情况下不建议直接修改,如果有这样的程序代码,建议改成fail-safe.
Comparable和Comparator的区别
- Comparable:内部比较器
compareTo(o1):返回int自然数(负,正,0)将传入的对象与当前对象对比 - compare(o1,o2):外部比较器
compare(o1,o2):一般用于不想修改类的情况
TreeMap在没有指定比较器的情况下,会按照TreeMap的内部排序方式排序。
队列和栈
- 栈
先进后出FILO(压栈),底层采用Vector
Stack<String> stack=new Stack<String>();
stack.push("");//添加
stack.pop();//弹出并移除
stack.peek();//弹出不移除- 队列
Queue企业中经常用消息队列(流量100W,但服务器只能处理1W,那么剩下的就存在队列消息服务器中。activeMQ)
先进先出; 还有一个双端队列–Deque,本身来自于Queue,能够代替Stack。
IO
-
按照流向来分:
输入流:InputStream和Reader
输出流:OutputStream和Writer -
按照处理单元来分:
- 字节流:Input/OutputStream,按byte处理
- FileInputStream
- ByteArrayInputStream
- BufferedInputStream
- ObjectInputStream
- DataInputStream
所有文件都能处理
- 字符流:Reader/Writer,按char处理
- FileReader
- CharArrayInputStream
- BufferedReader
只能处理文本文件
- 字节流:Input/OutputStream,按byte处理
字符流和字节流相互转换:InputStreamReader/OutPutStreamWriter
AIO BIO NIO
- BIO:block-IO 传统的阻塞IO JDK1.4之前默认使用
- ServerSocket(在Socket进行通信时,服务器需要指派线程为当前的Socket服务,并且时阻塞式服务)
- NIO:None-Block-IO:同步非阻塞IO,JDK1.4之后,现在用的较多的服务IO模型(netty,zooleeper)
一个线程对应多个服务(客户端)弊端是:多个客户端请求时,单个线程不够用。
有三个模型:(多路复用机制)- 单线程模型
- 多线程模型
- 主从线程模型
- AIO:NIO2–异步非阻塞IO,JDK1.7后支持,应用的不太多
什么叫序列化
要将一个Java对象进行网络传输(RPC)或保存到硬盘,做持久化操作。
session对象支持持久化操作。
实现Serializable接口后会有一个序列化ID,它是反序列化需要的对象
递归读取文件夹下的文件,代码实现
//给定一个路径去构造一个File
public static void getFile(String path){
File file=new File(path);
boolean flag=file.isDirectory();
if(flag){
File[] listFiles=file.listFiles();
for(File temp:listFiles){
if(temp.isDirectory){
System.out.println("目录名"+temp.getName());
getFile(temp.getPath());
}else{
System.out.println("是个文件"+temp.getName());
}
}
}else{
System.out.println("这就是个文件"+file.getName());
}
}网络编程
HTTP响应码301和302的区别
都是重定向,301:永久性重定向,302:非永久性重定向
SEO知识点:对于搜索引擎优化,301是无伤害的(对爬虫无伤害),302:有伤害的,不知道具体跳哪一个。
简述TCP和UDP
- TCP
- 面向连接的协议,Socket通信时需要三次握手
- 正因为需要连接,因此会出现DDOS攻击
- 基于流的协议
- ServerSocket
- 用于比较稳定,对数据有效性有很高要求的地方
- TCP报文头较复杂
- UDP
- 无连接协议
- 基于数据报(报文),不太可靠,会出现数据丢失
- DataGramSocket,DataGramPacket
- 应用于直播,视频,效率较高
- 报文头简单
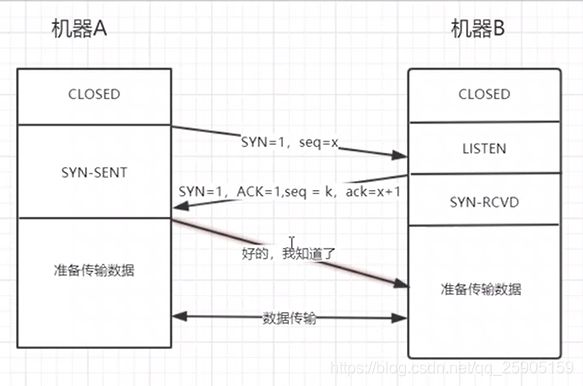
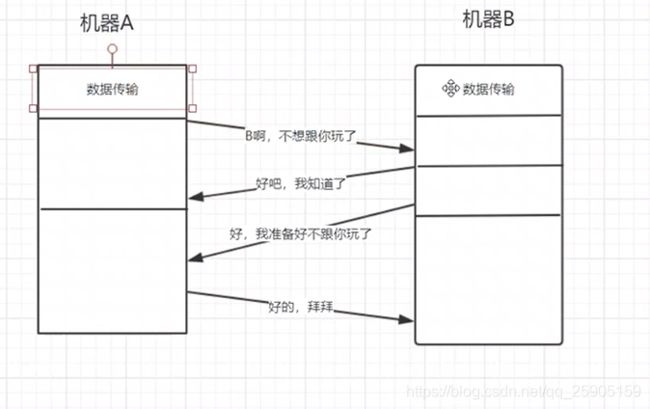
简述三次握手,四次挥手
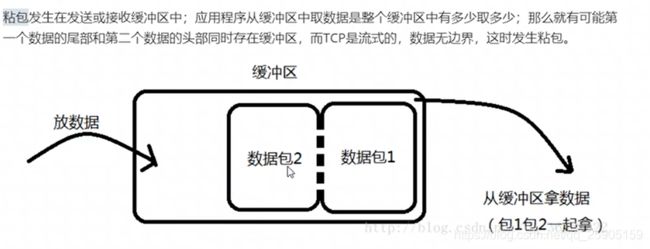
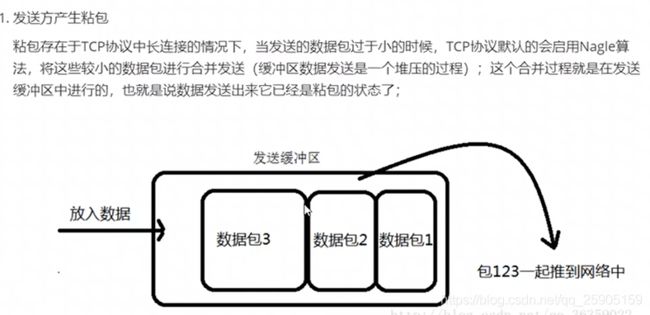
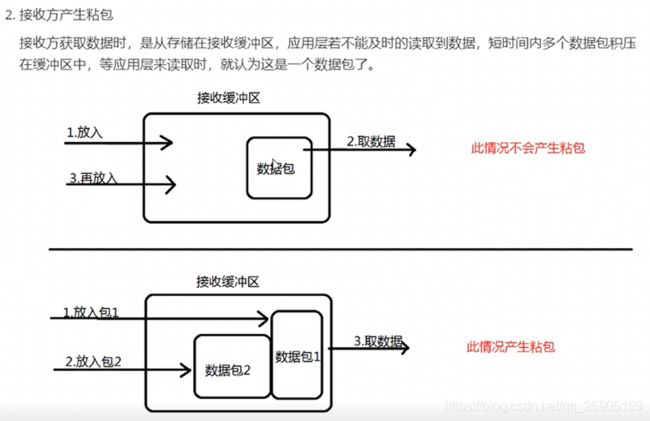
TCP粘包