【Faster R-CNN全文翻译】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Abstract
先进的目标检测网络依赖于区域提议算法来假设对象位置。像SPPnet和Fast R-CNN的改进减少了这些检测网络的运行时间,使区域提议计算成为瓶颈。在这项工作中,我们引入了一个区域提议网络(RPN),它与检测网络共享全图像卷积特征,从而实现了几乎无成本的区域提议。RPN是一个完全卷积网络,可同时预测每个位置的物体边界和对应分数。RPN被端到端地训练以生成高质量区域提议,其被Fast R-CNN用于检测。通过简单的交替优化,可以训练RPN和快速R-CNN以共享卷积特征。对于非常深的VGG-16模型,我们的检测系统在GPU上的帧速率为5fps(包括所有步骤),同时每张图片使用300个区域提议,在PASCAL VOC 2007(73.2%mAP)和VOC 2012(70.4%mAP)上实现了最先进的物体检测精度。
Code is available at https://github.com/ShaoqingRen/faster_rcnn. (https://github.com/facebookresearch/Detectron)
1. Introduction
目标检测的最新进展是由区域提议方法和基于区域的卷积神经网络(R-CNN)的成功推动的。尽管基于区域的CNN在计算上是昂贵的,如R-CNN中最初开发的那样,但由于跨提案共享卷积,它们的成本已经大大降低。 最新版本的Fast R-CNN使用非常深的网络VGG实现接近实时的速率,忽略了在区域提案上花费的时间。现在,提案是最先进的检测系统中的计算瓶颈。
区域提议方法通常依赖于廉价的特征和经济的推理方案。选择性搜索(SS)是最流行的方法之一,它基于工程化的低级特征贪婪地合并超像素。然而,与有效的检测网络Fast R-CNN相比,选择性搜索速度慢了一个数量级,在CPU实现中每个图像2s。 EdgeBoxes目前在提案质量和速度之间提供最佳权衡,每张图像0.2秒。然而,区域提议步骤仍然消耗与检测网络一样多的运行时间。
可以注意到,基于区域的快速CNN利用了GPU,而研究中使用的区域提议方法是在CPU上实现的,这使得这种runtime的比较是不公平的。加速提案计算的一个明显方法是为GPU重新实现它。这可能是一种有效的工程解决方案,但重新实施会忽略下游检测网络,因此错过了共享计算的重要机会。
在本文中,我们做了一个算法变化,通过深度网络计算提案,这是一个优雅而有效的解决方案,在给定的检测网络中提案计算几乎是无成本的。为此,我们引入了新颖的区域提议网络(RPN),它与最先进的物体检测网络共享卷积层。通过在测试时共享卷积,提案计算的边际成本很小(例如,每个图像10ms)。
我们的观察结果是,基于区域的检测网络(如快速R-CNN)使用的卷积特征映射(maps)也可用于生成区域提议。在这些卷积特征之上,我们通过添加两个额外的卷积层构建RPN:一是将每个卷积映射位置编码为短特征向量(例如,256维);二是在每个卷积映射位置处输出相对于该位置处的各种尺度和纵横比的 k区域提议的对象得分和回归边界(k = 9是典型值)。
因此,我们的RPN是一种完全卷积网络(FCN),它们可以针对生成检测提案的任务进行端到端的训练。为了将RPN与Fast R-CNN目标检测网络统一起来,我们提出了一种简单的训练方案,该方案在区域提议任务的微调和目标检测的微调之间交替,同时保持提议的固定。该方案快速收敛并产生具有在两个任务之间共享的卷积特征的统一网络。
我们在PASCAL VOC检测benchmarks上评估我们的方法,其中具有Fast R-CNN的RPN产生的检测精度优于具有Fast R-CNN的选择性搜索算法。同时,我们的方法在测试时放弃了SS的几乎所有计算负担,提案的有效运行时间仅为10毫秒。使用昂贵的超深模型VGG,我们的检测方法在GPU上的帧速率仍为5fps(包括所有步骤),因此在速度和准确度方面都是一个实用的物体检测系统(PASCAL VOC 2007上的mAP为73.2%,VOC 2007上的mAP为70.4%)。
2. Related Work
最近的几篇论文提出了使用深度网络来定位特定类或不可知类边界框的方法。在OverFeat方法中,训练全连接层(fc)以预测假定单个对象的定位任务的框坐标。然后将全连接层转换为卷积层,用于检测多个特定类的对象。Multi-Box方法使用网络生成区域提议,其最后的fc层同时预测多个框(例如,800个),其用于R-CNN目标检测检测。它们的提议网络应用于单个图像或多个大裁剪图像(例如,224 * 224)。我们将在后面的方法中更深入地讨论OverFeat和MultiBox。
卷积的共享计算已经引起越来越多的关注,以获得有效但准确的视觉识别。OverFeat论文计算了图像金字塔中的卷积特征,用于分类,定位和检测。针对共享卷积特征映射提出了自适应大小的池(SPP),用于有效的基于区域的对象检测和语义分割。 Fast R-CNN可在共享卷积特征上实现端到端检测器训练,并显示出引人注目的准确性和速度。
3. Region Proposal Networks
区域提议网络(RPN)将任意大小图像作为输入并输出一组矩形对象提议,每个提议具有对象分数. (“Region” is a generic term and in this paper we only consider rectangular regions, as is common for many methods. “Objectness” measures membership to a set of object classes vs. background.) 我们使用全卷积网络对此过程进行建模,我们将在本节中对其进行描述。因为我们的最终目标是与Fast R-CNN目标检测网络共享计算,我们假设两个网络共享一组共同的卷积层。在我们的实验中,我们研究了具有5个可共享卷积层的Zeiler和Fergus模型(ZF)以及具有13个可共享卷积层的Simonyan和Zisserman模型(VGG)。
为了生成区域提议,我们在最后一个共享卷积层输出的卷积特征映射上滑动一个小网络。该网络完全连接到输入卷积特征映射的n * n空间窗口。每个滑动窗口被映射到较低维向量(对于ZF为256维,对于VGG为512维)。该向量被馈送到两个兄弟的完全连接的层,盒回归层(box-regression layer, reg)和盒分类层(box-classification layer, cls)。我们在本文中使用n = 3,注意到输入图像上的有效感受野很大(ZF和VGG分别为171和228像素)。该迷你网络在Figure 1(左)中的单个位置示出。请注意,由于迷你网络以滑动窗口方式运行,因此所有空间位置共享全连接的层。该架构自然地用n * n卷积层实现,然后是两个兄弟1 * 1卷积层(分别用于reg和cls)。ReLU应用于n * n卷积层的输出。
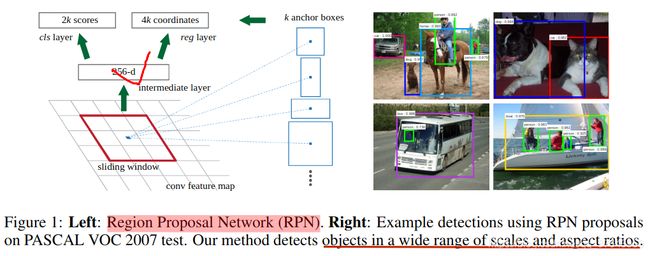
Translation-Invariant Anchors. 在每个滑动窗口位置,我们同时预测 k 个区域提议,因此reg层具有 4k 个输出,编码k个盒子的坐标。cls层输出 2k 个分数,用于估计每个提案的对象/非对象的概率。(For simplicity we implement theclslayer as a two-class softmax layer. Alternatively, one may use logistic regression to produce k scores) k个提议相对于k个参考框参数化,称为锚。每个锚点都在所讨论的滑动窗口的中心,并且与尺度和纵横比相关联。 我们使用3个刻度和3个纵横比,在每个滑动位置产生k = 9个锚。 对于大小为W * H(通常为~2,400)的卷积特征映射,总共存在W * H * k个锚。我们方法的一个重要特性是它是平移不变的,无论是锚点还是计算提案相对于锚点的函数。
作为比较,MultiBox方法使用k-means生成800个锚,这些锚不是平移不变的。如果平移图像中的对象,则提案也应该平移,并且同一函数应该能够在任一位置预测提案。此外,因为MultiBox锚不是平移不变的,所以它需要(4 + 1)* 800维输出层,而我们的方法需要(4 + 2)* 9维输出层。我们的提议层的参数减少了一个数量级(使用GoogLeNet的MultiBox为2700万,而使用VGG-16的RPN为240万),因此PASCAL VOC等小数据集的过度拟合风险较小。
学习区域提案的损失函数. 为了训练RPN,我们为每个锚分配一个二类标签(是或不是对象)。我们为两种锚框分配一个正标签:(i)与真实框重叠且具有最高IoU的锚框(ii)与任意真实框的IoU重叠高于0.7的的锚框。请注意,单个真实框可以为多个锚框分配正标签。如果与所有真实框的IoU比率低于0.3,我们会为非正锚框分配负标签。 既不是正标签也不是负标签的锚点对训练目标没有贡献。
通过这些定义,我们跟随Fast R-CNN中的多任务损失来最小化目标函数。 我们对图像的损失函数定义为:

这里,i 是小批量锚的索引,p{i} 是锚i 作为对象的预测概率。如果锚框为正,则真实标签 p{i *} 为1,如果锚为负,则为0。t {i}是表示预测边界框的4个参数化坐标的向量,并且t {i *}表示与正锚框相关联的真实框。分类损失 Lcls 是两类(对象与非对象)的对数损失。对于回归损失,我们使用 Lreg(t {i},t {i *}) = R(t {i} - t {i *}) ,其中 R 是Fast R-CNN中定义的鲁棒损失函(smooth L1)。p{i *} Lreg 表示仅对正锚(p{i *} = 1)激活回归损失,否则表达式失效(p{i *} = 0)。cls和reg层的输出分别由{pi}和{ti}组成。这两个术语用 Ncls 和 Nreg 标准化,以及平衡权重Lamda。
在我们的早期实现中(也在发布的代码中),Lamda设置为10,并且上式中的cls项由小批量大小(即,Ncls = 256)标准化,并且通过以下方式归一化 锚点位置的数量(即Nreg~2400)。cls和reg都是以这种大致相等的方式加权。

对于回归,我们采用R-CNN中4个坐标进行参数化:
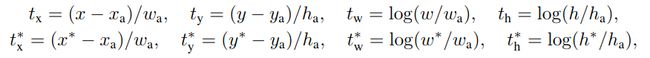
其中x,y,w和h表示盒子中心的两个坐标,宽度和高度。变量x,xa和x *分别用于预测框,锚框和真实框(同样适用于y,w,h)。这可以被认为是从锚框到附近的真实框进行边界框回归。
然而,我们的方法通过与先前基于特征图的方法不同的方式实现边界框回归。在SPPNet和Fast R-CNN中,对从任意大小区域池化得到的特征执行边界框回归,并且回归权重由所有大小区域共享。在我们的公式中,用于回归的特征在特征图上具有相同的空间大小(n*n)。为了考虑不同的大小,学习了一组k个边界框回归量。 每个回归量负责一个比例和一个宽高比,并且k个回归量不共享权重。因此,即使特征具有固定的尺寸/比例,仍然可以预测各种尺寸的框。
Optimazation. 由全卷积网络实现的RPN可以通过反向传播和随机梯度下降(SGD)进行端到端训练。我们遵循Fast R-CNN中的“以图像为中心”的采样策略来训练这个网络。每个小批量产生于包含许多正负锚的单个图像。可以针对所有锚框的损失函数进行优化,但是这将偏向负样本,因为它们占主导地位。相反,我们在图像中随机采样256个锚点来计算小批量的损失函数,其中采样的正和负锚点的比率高达1:1。如果图像中的正样本数少于128个,我们对小批量填充负样本。
共享区域提议和目标检测的卷积特征. 到目前为止,我们已经描述了如何训练用于区域提议生成的网络,而不考虑将利用这些提议的基于区域的目标检测CNN。对于检测网络,我们采用Fast R-CNN并提出了一种算法,该算法学习在RPN和快速R-CNN之间共享的卷积层。
独立训练的RPN和Fast R-CNN都将以不同方式修改其卷积层。因此,我们需要开发一种技术,允许在两个网络之间共享卷积层,而不是学习两个独立的网络。请注意,这并不像简单地定义包含RPN和Fast R-CNN的单个网络,然后使用反向传播优化那样容易。原因是Fast R-CNN训练依赖于固定对象提议,以及目前尚不清楚如果在改变提议机制的同时学习快速R-CNN是否会会收敛。虽然这种联合优化是未来工作中的一个有趣问题,但我们开发了一种实用的4步训练算法,通过交替优化来学习共享特征。
在第一步中,我们如上所述训练RPN。该网络使用ImageNet预先训练的模型进行初始化,并针对区域提议任务进行端到端微调。在第二步中,我们使用由步骤1中 RPN生成的提议训练Fast R-CNN检测网络。该检测网络也由ImageNet预训练模型初始化。此时,两个网络不共享卷积层。在第三步中,我们使用检测器网络来初始化RPN训练,但我们固定了共享卷积层,只调整了RPN特有的层。现在这两个网络共享卷积层。最后,保持共享卷积层固定,我们微调Fast R-CNN的fc层。因此,两个网络共享相同的卷积层并形成统一的网络。
Implementation Details. 我们在单尺度图像上训练和测试区域提议和目标检测网络[7,5]。我们重新缩放图像,使其短边s = 600像素[5]。多尺度特征提取可以提高准确性,但没有表现出良好的速度,准确性权衡[5]。我们还注意到,对于ZF和VGG网络,最后一个卷积层上的总步幅在重新缩放的图像上是16个像素,因此在典型的PASCAL图像上是~10个像素(~500*375)。即使是如此大的步幅也能提供良好的效果,尽管可以通过更小的步幅进一步提高精度。
对于锚框,我们使用3个刻度,框区域为 128 * 128, 256 * 256和512 * 512 像素,3个宽高比为 1:1, 1:2和2:1。我们注意到,我们的算法允许在预测大型提案时使用大于潜在感受野的锚框。这样的预测并非不可能 - 如果只有对象的中间可见,人们仍然可以粗略地推断对象的范围。通过这种设计,我们的解决方案不需要多尺度特征或多尺度滑动窗口来预测大区域,从而节省了大量的运行时间。Figure 1(右)显示了我们的方法适用于各种尺度和纵横比的能力。下表显示了使用ZF网络的每个锚点学习平均提议大小.(s = 600)
![]()
需要小心处理跨越图像边界的锚框。在训练期间,我们忽略所有跨边界锚框,因此它们不会造成损失。对于典型的1000 * 600图像,总共将有大约20k(60 * 40 * 9)个锚框。由于忽略了跨界锚框,每个图像大约有6k个锚框用于训练。如果在训练中不忽略过境异常值,则会在目标函数中引入大的,难以纠正的误差项,并且训练不会收敛。然而,在测试期间,我们仍然将全卷积RPN应用于整个图像。这可能会生成跨界建议框,我们将其剪切到图像边界。
一些RPN提案彼此高度重叠。为了减少冗余,我们根据其cls分数对提议区域采用非最大抑制(NMS)。我们将NMS的IoU阈值修正为0.7,这使得每个图像的建议区域大约为2k。正如我们将要展示的那样,NMS不会损害最终的检测准确性,但会大大减少提议的数量。在NMS之后,我们使用排名 top-N 的提议区域进行检测。在下文中,我们使用2k RPN提议训练Fast R-CNN,但在测试时评估不同数量的提议。
4. Experiments
我们全面评估了PASCAL VOC 2007检测基准的方法[4]。该数据集包括20个类别,大约5k 训练图像和5k 测试图像。我们还为部分网络提供了PASCAL VOC 2012基准测试的结果。对于ImageNet预训练网络,我们使用具有5个卷积层和3个fc层的ZF网络的“快速”版本,以及具有13个卷积层和3个fc的公共VGG-16模型。我们主要评估检测平均精度(mAP),因为这是目标检测的实际度量(而不是关注对象提议代理指标)。
5. Conclusion
我们提出了区域提议网络(RPN),以实现高效准确的区域提案生成。通过与下游检测网络共享卷积特征,区域提议步骤几乎是免费的。我们的方法使基于深度学习的统一目标检测系统能够以5-17 fps的速度运行。学习到的RPN还改善了区域提议质量,从而提高了整体目标检测精度。
Reference paper:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks