scrapy的使用(一): Scrapyd 部署监控 scrapy 爬虫任务流程
Scrapyd服务 是用来部署、远程监控scrapy 的服务。
1. 环境安装
Sudo pip install scrapyd (安装scrapyd 服务端)
Sudo pip install scrapyd client (安装 scrapyd 客户端)
如果在 window 上,还需要安装 curl 包(链家下载)。并添加到环境变量(把 .exe 添加到环境变量)。
2. 运行服务端
在需要执行爬虫的远程服务器上运行scrapyd 服务端: scrapyd(命令)
在编写爬虫的电脑上运行客户端部署(可以有多个爬虫客户端):
(1) 打开需要部署的scrapy 项目里的 scrapy.cfg 文件。
(2) 将文件中的:

改为:

(3) 打开 /usr/local/lib/python2.7/site-package/scrapyd 文件夹,查找 default_scrapyd.conf 文件,修改为
![]()
0.0.0.0表示可接受外部访问(不限制ip)。
注意:在windows中路径为 python2.7/site-package/scrapyd
3. 在同一局域网内,通过浏览器访问 开启scrapyd 服务端的远程服务器 ip:port ( 6800 )。
4. 在编写爬虫的电脑上(scrapyd客户端)对项目进行启用挂载(命令如下):
scrapyd-deploy scrapyd配置名 -p scrapy项目名
注意: Window中执行 scrapyd-deploy前要进行配置:
在c:\python27\Scripts下新建一个scrapyd-deploy.bat,文件内容如下:
@echo off
C:\Python27\python C:\Python27\Scripts\scrapyd-deploy %*
并添加 C:\Python27\Scripts; 到环境变量
5. 将爬虫部署到 scrpayd 服务上(在编写爬虫的客户端执行命令),并启动:
curl http: //scrapyd服务端ip:6800/schedule.json -d project=爬虫项目名 -d spider=爬虫名
以上将返回一个字典 { },其中 “jobid“ 是任务id,可以用来停止指定爬虫任务。
6. 停止任务:
curl http: //scrapyd服务端ip:6800/cancel.json -d project=爬虫项目名 -d job=“jobid”
注意:如果使用的是python2.7 且安装的scrpayd 版本较高,会导致第4 、5 环节出错,这需要改一下scrapyd源码(操作如下):
将\Python27\Lib\site-packages\scrapyd\ utils.py 文件中的 def get_spider_list 方法中的:
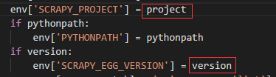 改为
改为 