python3爬虫selenium+chrom爬取今日头条热点新闻保存到数据库
本人是菜鸟一枚,学了python爬虫有一段时间了,想找个网站练练手,网上搜索今日头条是动态加载的页面,用requests库,需要破as:A175DBDFDEC7024
cp: 5BFE87208254DE1,_signature: 4P9lsBAcuwy3yC3rgtk6COD.Za,这些参数都是加密处理的,破解有一定的难度,但是有selenium驱动chrom浏览器就比较好爬取了。
一,准备
1,需要安装好python3,并配置好开发坏境,可以去官网下载安装,官网:https://www.python.org/downloads/
2。下载好chrom浏览器,并下载好对应的驱动,我用的pycharm开发工具,可以自行选择。chrom驱动下载地址:http://chromedriver.storage.googleapis.com/index.html
3,mongodb下载官网:https://www.mongodb.com/download-center
安装过程这里就不在赘述了,百度搜索就可以的。
二,实现过程
1,打开ychrom新建一个python文件,导入需要的库
from selenium import webdriver #导入web驱动库
import time #导入时间库
import pymongo#monggo #导入数据库
2,因为获取的数据需要保存到mongodb数据库中,所以可以先连接数据库
链接数据库
client = pymongo.MongoClient() #链接数据库
db =client['db'] #设置数据库名
toutiao =db['toutiao'] #设置集合名
3,
#启动webdrive
base_url ='https://www.toutiao.com'
brower =webdriver.Chrome()
brower.get(base_url)
brower.implicitly_wait(10)
brower.maximize_window() # 最大化窗口
brower.implicitly_wait(10)
brower.find_element_by_link_text('热点').click()
brower.implicitly_wait(10)
4,用selenium自带的find_elements_by_xpath()方法获取页面需要的元素,这里我们获取新闻的标题title,详情页面的链接url,发布者source,评论总数comment
def get_info():
titles= brower.find_elements_by_xpath('//div[@class="title-box"]/a')
for title in titles:
title_list.append(title.text)
urls = brower.find_elements_by_xpath('//div[@class="title-box"]/a')
for url in urls:
url = url.get_attribute('href')
url_list.append(url)
sources = brower.find_elements_by_xpath('//a[@class="lbtn source"]')
for source in sources:
sources_list.append(source.text)
comments =brower.find_elements_by_xpath('//a[@class="lbtn comment"]')
for comment in comments:
comments_list.append(comment.text)
5,因为今日头条是用ajax动态加载的,浏览器向下拉的过程中,页面会一直在下面加载出来,可以通过execute_script(“window.scrollTo();”)功能模拟浏览器下拉页面刷新数据
def get_manyinfo():
brower.execute_script("window.scrollTo(0,1000);")
time.sleep(1)
while len(title_list) < 100:
for i in range(30):
brower.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(3)
get_info()
brower.refresh()
else:
brower.close()
6,设计保存到数据库中,用zip()函数匹配title,url,source, comment,保存为字典格式,然后将字典保存到数据库中
def save_info():
infos = zip(title_list, url_list, sources_list, comments_list)
for info in infos:
data={
'标题': info[0],
'url': info[1],
'来源': info[2],
'评论': info[3]
}
#result =db['toutiao'].insert_one(data)
print(data)
print('数据写入成功')
三,完整代码
from selenium import webdriver
import time
import pymongo
# 链接数据库
client = pymongo.MongoClient() #链接数据库
db =client['db'] #设置数据库名
toutiao =db['toutiao'] #设置集合名
#启动webdrive
base_url ='https://www.toutiao.com'
brower =webdriver.Chrome()
brower.get(base_url)
brower.implicitly_wait(10)
brower.maximize_window() # 最大化窗口
brower.implicitly_wait(10)
brower.find_element_by_link_text('热点').click()
brower.implicitly_wait(10)
title_list,url_list,sources_list,comments_list=[],[],[],[]
# 获取页面新闻标题,详情页面链接,来源,评论,并添加到列表中
def get_info():
titles= brower.find_elements_by_xpath('//div[@class="title-box"]/a')
for title in titles:
title_list.append(title.text)
urls = brower.find_elements_by_xpath('//div[@class="title-box"]/a')
for url in urls:
url = url.get_attribute('href')
url_list.append(url)
sources = brower.find_elements_by_xpath('//a[@class="lbtn source"]')
for source in sources:
sources_list.append(source.text)
comments =brower.find_elements_by_xpath('//a[@class="lbtn comment"]')
for comment in comments:
comments_list.append(comment.text)
# 通过下拉进度条一直加载页面
def get_manyinfo():
brower.execute_script("window.scrollTo(0,1000);")
time.sleep(1)
while len(title_list) < 100:
for i in range(30):
brower.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(3)
get_info()
brower.refresh()
else:
brower.close()
# 保存获取的信息保存到monggodb中
def save_info():
infos = zip(title_list, url_list, sources_list, comments_list)
for info in infos:
data={
'标题': info[0],
'url': info[1],
'来源': info[2],
'评论': info[3]
}
result =db['toutiao'].insert_one(data)
print(data)
print('数据写入成功')
def main():
get_manyinfo()
save_info()
if __name__=="__main__":
main()
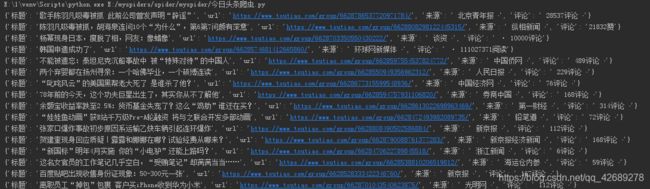
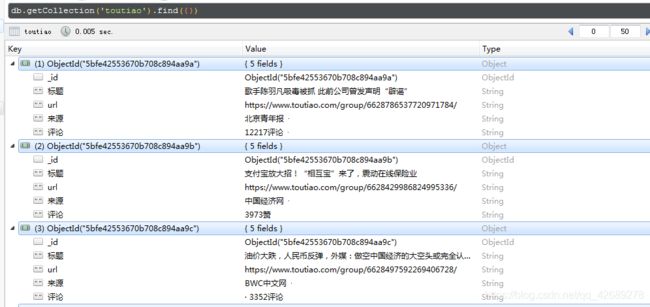
四,最后的效果,由于是新手,代码都是自己写的,可以参考一下,代码和功能肯定不是很完善,希望大佬多多指正啊。