python-计算机视觉 - 图像检索
文章目录
- 一 . 环境安装
- 1.1 项目形式
- 1.2 一些要修改的地方
- 二 . 基于BOW图像检索原理
- 2.1 BOF(Bag of features)原理
- 2.2 创建视觉单词
- 2.2.1 SIFT算法提取特征,创建视觉单词词汇
- 2.2.2 建立视觉单词
- 2.2.3 建立图像索引
- (1)建立数据库
- (2)将图片添加到数据库
- 2.2.4 检索图像
- (1)利用索引获取候选图像
- (2)查询一幅图像
- 三. 代码运行
- 3.1 生成词汇
- 3.2 图像索引
- 3.3 搜索图像
- 四. 结果测试及分析
- 4.1 搜索结果:
- 4.2 结果分析
- 4.2.1 测试一
- 4.2.2 测试二
- 4.3 小结
一 . 环境安装
1.1 项目形式
要将项目和以下几个文件放在一起
first1000 为1000张图片数据集;
1.2 一些要修改的地方
- 在anaconda文件夹中找到:

可以看到一个sqlite3的包,说明anaconda2自带数据库包,不需要安装pysqlite库,所以需要更改PCV\imagesearch中的imagesearch.py文件第三行为from sqlite3 import dbapi2 as sqlite就行; - 有关sift在之前的实验项目里直接使用即可;
二 . 基于BOW图像检索原理
2.1 BOF(Bag of features)原理
Bag-of-Features模型仿照文本检索领域的Bag-of-Words方法,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book),即码字的集合,词典中所含词的个数反映了词典的大小。图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现与否或次数,图像可描述为一个维数相同的直方图向量,即Bag-of-Features。
Bag-of-Features更多地是用于图像分类或对象识别。在上述思路下对训练集提取Bag-of-Features特征,在某种监督学习(如:SVM)的策略下,对训练集的Bag-of-Features特征向量进行训练,获得对象或场景的分类模型;对于待测图像,提取局部特征,计算局部特征与词典中每个码字的特征距离,选取最近距离的码字代表该特征,建立一个统计直方图,统计属于每个码字的特征个数,即为待测图像之Bag-of-Features特征;在分类模型下,对该特征进行预测从实现对待测图像的分类。
从文本挖掘中获取灵感——矢量空间模型
矢量空间模型(也称BOW模型)是一个用于表示和搜索文本文档的模型。BOW模型基本上可以用于任何对象类型,包括图像。这些矢量是由文本词频直方图构成,即矢量包含了每个单词出现的次数,而且在其他地方包含很多0元素。BOW模型是忽略了单词出现的顺序及位置。
通过单词计数来构成文档直方图向量,从而建立文档索引。由于每篇文档长度不同,故以直方图总和和将向量归一化成单位长度。对于直方图向量中的每个元素可根据每个单词的重要性赋予相应的权重,通常数据集中的一个单词的重要性与它在文档中出现的次数成正比,与在数据集出现次数成反比。
2.2 创建视觉单词
2.2.1 SIFT算法提取特征,创建视觉单词词汇
对于计算机而言,不能同人一样具有主观意识对图像之间进行区分,而无法把两张相似或不相似的图片进行区分,这时就需要进行机器学习,学习 “视觉词典(visual vocabulary)对图像进行“身份证”标记,即进行图像特征提取;
目前比较通用的提取方法为sift描述算子进行特征提取,从而标记每张图片,达到唯一标识。特征点的提取主要是针对图像的关键部分提取,sift算法优点就在于对一些特殊点提取比较敏感,例如:sift算法对图像旋转、尺度缩放、亮度变化具有保持不变性,对视角变化、仿射变换、噪声有一定稳定性,即特征点取的是一些边缘角点、亮点等。
sift 原理详情:https://editor.csdn.net/md/?articleId=104716460
2.2.2 建立视觉单词
- 为了将文本挖掘技术运用到图像中,首先要建立视觉等效单词;
- 可以采用SIFT局部描述算子获得,针对输入特征集,根据视觉词典进行量化。
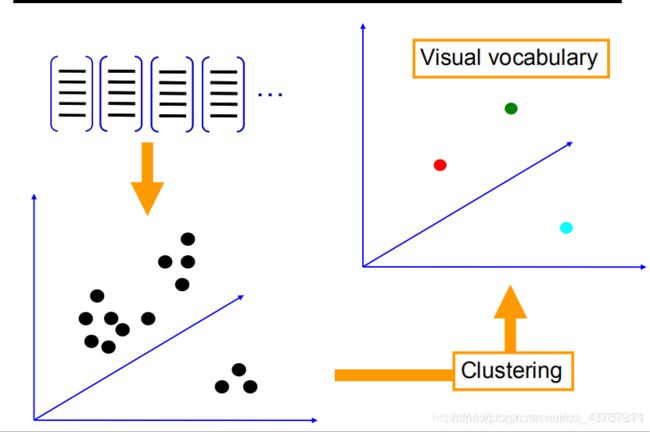
- 建立视觉单词的思想就是将描述算子空间量化成一些典型实例,并将图像中的每个描述算子指派到其中的某个实例中,这些典型实例可通过分析训练图像集确定。即从一个很大的训练集提取特征描述算子,利用一些聚类算法可以构建出视觉单词(聚类算法最常用的是K-means),视觉单词是在给定特征描述算子空间中一组向量集,采用K-means进行聚类得到的聚类质心;把输入图像,根据TF-IDF转化成视觉单词( visual words)的频率直方图 ,用视觉单词直方图来表示图像。如图下所示:
2.2.3 建立图像索引
(1)建立数据库
在索引前,需要建立一个数据库。对图像进行索引是从图像中提取描述子,利用词汇将描述子转换成视觉单词,并保存视觉单词及对应图像的单词直方图。从而可以利用图像对数据库进行查询,并返回相似的图像。
这里使用了SQlite作为数据库,SQlite对应的python版本是pysqlite。
(2)将图片添加到数据库
建立图像数据库,就需要加入图像,实现方法为在pcv包的imagesearch.py 文件里的add_to_index()方法;此方法主要是获取一幅带有特征描述子的图像,投影到词汇上添加进数据库中。
2.2.4 检索图像
(1)利用索引获取候选图像
利用建立起来的索引找到包含特定的所有图像,即相似物体、相似的脸、相似颜色等;
为了获得包含多个单词的候选图像,例如一个单词直方图中全部非零元素,在每个单词上进行遍历,得到包含改单词的图像列表,合并这些列表。然后创建一个元组列表有单词id和次数构成,其中次数以候选列表中每个单词出现的次数为准。同时还以元组中的第二个元素为准进行排序。最后会得到一个包含图像id的列表,排在列表最前面的是最好的匹配图像。
(2)查询一幅图像
利用一副图像进行查询是没必要进行完全的搜索,为了比较单词直方图,需要从数据库中读入图像单词直方图,检索每个单词直方图及候选图像列表,对于每个候选图像,用标准的欧式距离比较它和查询图像间的直方图,返回一个已经排好序的的元组列表。
三. 代码运行
3.1 生成词汇
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夹下图像的sift特征
#for i in range(nbr_images):
# sift.process_image(imlist[i], featlist[i])
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
#保存词汇
# saving vocabulary
with open('first1000/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print 'vocabulary is:', voc.name, voc.nbr_words
结果显示:


3.2 图像索引
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print con.execute('select count (filename) from imlist').fetchone()
print con.execute('select * from imlist').fetchone()
数据库文件:

3.3 搜索图像
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
f = open('first1000/vocabulary.pkl', 'rb')
voc = pickle.load(f)
f.close()
src = imagesearch.Searcher('testImaAdd.db',voc)
locs,descr = sift.read_features_from_file(featlist[0])
iw = voc.project(descr)
print ('ask using a histogram...')
print (src.candidates_from_histogram(iw)[:10])
src = imagesearch.Searcher('testImaAdd.db',voc)
print ('try a query...')
nbr_results = 10
res = [w[1] for w in src.query(imlist[68])[:nbr_results]]
imagesearch.plot_results(src,res)
print("计算搜索结果得分:")
print(imagesearch.compute_ukbench_score(src,imlist[:10]))
通过图像编号选择搜索的图片:

四. 结果测试及分析
4.1 搜索结果:


4.2 结果分析
4.2.1 测试一
- 要搜索的图像77号:

- 打印从索引中查找出的前十个图像,其中第一幅为查询图像本身,其他的图像,根据匹配效果由前往后排序:

- 根据计算前4个位置中搜索到相似图像数评判搜索结果的正确率,分数为4时,结果最理想;分数为0时,则说明不准确,正确率为0.
搜索评分为3.3 说明效果还算理想。

4.2.2 测试二
- 搜索图像为60号时:


4.3 小结
- 本次实验一共有1000张照片作为数据集,每四张较相似照片为一组,测试时输出10张结果图,根据两组实验发现正确率效果还算理想;
- 但也存在一些问题,如特征简单的图片则会出现偏差;
原因分析:
3. 字典大小问题,字典过大,单词缺乏一般性,对噪声敏感,计算量大,关键是图象投影后的维数高;字典太小,单词区分性能差,对相似的目标特征无法表示。
4. 相似性测度函数用来将图象特征分类到单词本的对应单词上,其涉及线型核,塌方距离测度核,直方图交叉核等的选择。
5. 词袋表征特征的过程其实牵涉到量化的过程,这其实损失了特征的精度
存在的一些问题:
7. 检索模块设计的太粗糙,速度太慢
8. Kmeans聚类时间长