Datawhale第十一期组队学习-Task2
Task2:数据的探索性分析(EDA
- 前言
- EDA目标
- 操作实例
- 导入库
- 判断数据缺失和异常
- 了解预测值的分布
- 特征查看unique分布
- 分离多个特征的方法
- 生成数据报告
- 学习总结
- missingno
- 缺省值
- seaborn
- skew、kurt说明参考
- 预测处理
- 参考链接
前言
操作实例是部分练习,挑着写的,不考虑逻辑,完整练习连接在最后。
学习总结是查阅资料补充的,可能简答了。
EDA目标
-
EDA的价值主要在于熟悉数据集,了解数据集,对数据集进行验证来确定所获得数据集可以用于接下来的机器学习或者深度学习使用。
-
当了解了数据集之后我们下一步就是要去了解变量间的相互关系以及变量与预测值之间的存在关系。
-
引导数据科学从业者进行数据处理以及特征工程的步骤,使数据集的结构和特征集让接下来的预测问题更加可靠。
-
完成对于数据的探索性分析,并对于数据进行一些图表或者文字总结并打卡。
操作实例
导入库
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
##载入数据和观察
## 载入训练集和测试集;
path = './datalab/'
Train_data = pd.read_csv(path+'used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv(path+'used_car_testA_20200313.csv', sep=' ')
#查看维度
print('Train_data.shape:',Train_data.shape)
print('Test_data.shape:',Test_data.shape)
#简略观察数据
Train_data.head().append(Train_data.tail())
#通过describe()来熟悉数据的相关统计量
Train_data.describe()
Test_data.describe()
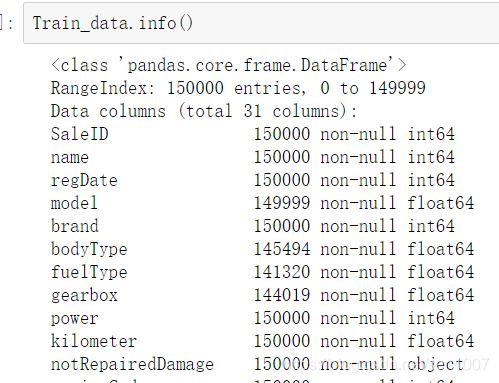
#通过info()来熟悉数据类型
Train_data.info()
Test_data.info()
判断数据缺失和异常
查看每列nan情况
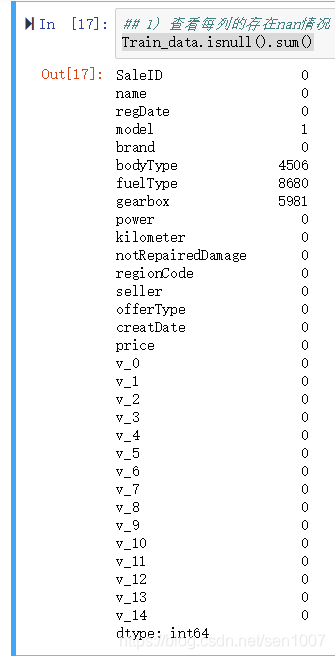
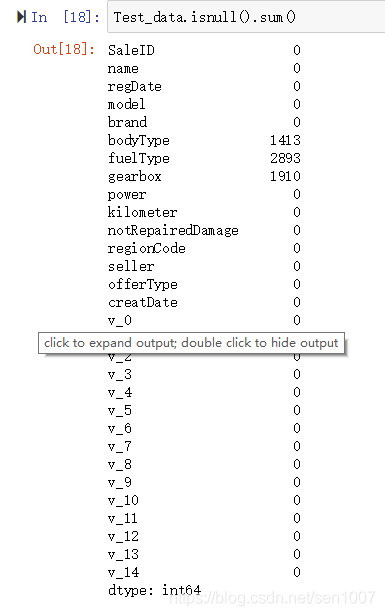
# nan可视化
missing = Train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
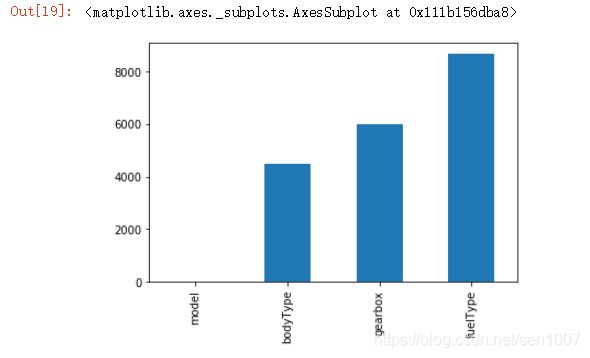
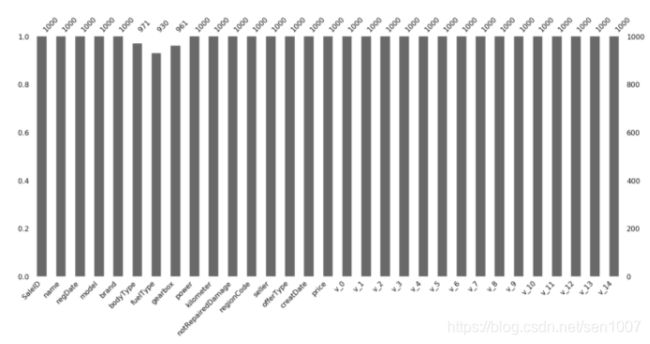
处理缺省值
msno.matrix(Train_data.sample(250))

msno.bar(Train_data.sample(1000))
Train_data['notRepairedDamage'].value_counts()

Train_data['notRepairedDamage'].replace('-',np.nan,inplace=True)
Train_data.isnull().sum()

了解预测值的分布
## 1) 总体分布概况(无界约翰逊分布等)
import scipy.stats as st
y = Train_data['price']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
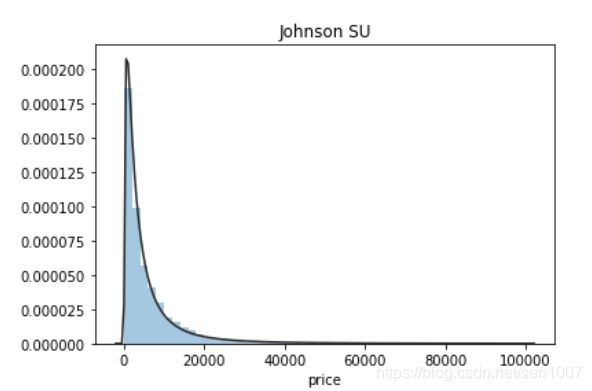
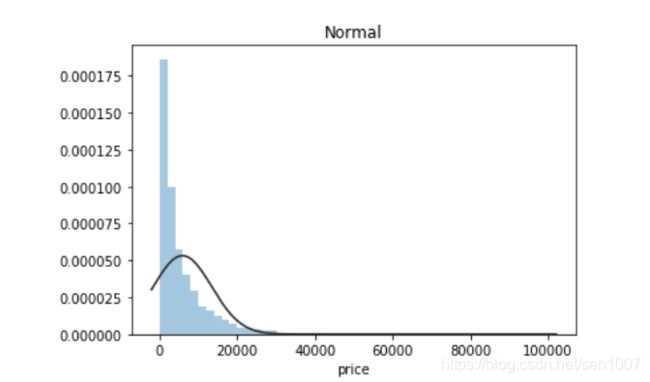
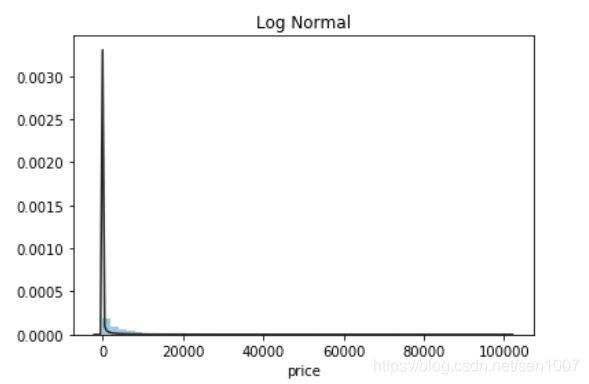
价格不服从正态分布,所以在进行回归之前,它必须进行转换。虽然对数变换做得很好,但最佳拟合是无界约翰逊分布。
特征查看unique分布
分离多个特征的方法
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
或者用
# 数字特征
numeric_features = Train_data.select_dtypes(include=[np.number])
numeric_features.columns
# 类型特征
categorical_features = Train_data.select_dtypes(include=[np.object])
categorical_features.columns
# 特征nunique分布
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有个{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))

生成数据报告
学习总结
missingno
msno.matrix(Train_data.sample(50))//随机抽取50样本,查看nan,是白线
msno.bar(Train_data.sample(50))//跟上msno.matrix差不多,比较直观看出nan
缺省值
null/None/NaN
null经常出现在数据库中
None是python中的缺失值,类型是NoneType。
NaN也是python中的缺失值,意思是不是一个数字,类型是float。
在pandas和Numpy中会将None替换为NaN,而导入数据库中的时候则需要把NaN替换成None。
数字类型数据的具体格式有:int,float64…
类别类型数据的格式是object,也就是字符串,不可相加减。
个人看法:object容器会储存None,在数字类型的列中出现object,这列应该要数据清洗。赛题中出现(-)。
seaborn
seaborn的displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。
seaborn.distplot
sns.distplot(y, kde=False, fit=st.johnsonsu)
sns.distplot(y, kde=False, fit=st.norm)
sns.distplot(y, kde=False, fit=st.lognorm)
skew、kurt说明参考
skew、kurt说明参考
偏度和峰度是看数据跟正态分布的比较。
预测处理
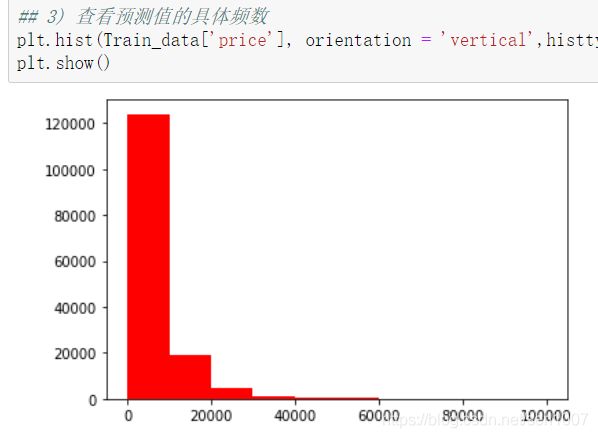
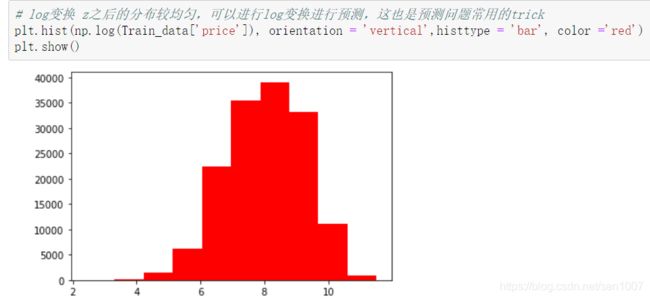
各列偏度和峰值
每列数字特征列分布
数字特征相互关系
参考链接
链接: Datawhale 零基础入门数据挖掘-Task2 数据分析