Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution
转载请附上原文链接,谢谢
0 abstract:
最近卷积神经网络经常被用到对单图像超分辨率的高质量重建中。在这篇论文中,我们提出了Laplacian金字塔超分辨率网络(LapSRN)来逐步重构高分辨率图像的子频带残差(sub-band residuals)。在每个金字塔的层,我们将粗分辨率特征图作为输入,预测高频残差(high-frequency residuals),并使用反卷积(transposed convolutions)来进行向上采样到finer level。我们的方法并没有将双三次差值(bicubic interpolation)作为预处理步骤,从而减小了计算的复杂性。我们使用了一个强大的Charbonnier损失函数对所提出的LapSRN进行了深入的监督,实现了高质量的重建。我们的网络通过渐进的重构,在一个前馈的过程(feed-forward)中产生了多尺度的预测,从而促进了资源感知(resorce-aware)的应用。对基准数据集进行了大量的定量和定性评估,结果表明,该算法在速度和精度方面优于最先进的方法。
1 Introduction:
单图像超级分辨率(SR)旨在从单个低分辨率(LR)输入图像重建高分辨率(HR)图像。近年来,基于实例(example-based)的SR方法通过使用大型图像数据库从LR到HR图像块的映射展示了最先进的性能。目前已经应用了大量的学习算法来学习这样的映射,包括字典学习(dictionary learning)【37、38】、本地线性回归(linear regression)【30、36】和随机森林(random forest)【26】。
最近,Dong 等人提出了一种超分辨率卷积神经网络(SRCNN)来学习非线性的LR-to-HR映射。这个网络被扩展到嵌入一个稀疏的基于编码的网络【33】或者使用一个更深层次的结构。虽然这些模型显示了Promissing 的结果,但有三个主要问题。首先,现有的方法使用预先定义的上采样处理器(upsampling operator),e.g.:①双三次差值。在应用网络进行预测之前,上采样输入图像为目标分辨率大小的图像。这个预处理步骤增加了不必要的计算成本,并且经常导致可见的人工痕迹(artifacts)。②一些算法通过在LR图像上执行卷积和用亚像素的卷积【28】或反卷积(转置卷积)来代替预定义的向上采样处理器来加速SRCNN。然而,这些方法使用相对较小的网络,由于网络容量有限,不能很好地学习复杂的映射。其次,现有的方法用 l2 loss对网络进行优化,不可避免地产生了模糊的预测。由于这 l2 loss 无法捕捉HR补丁的底层多模式分布(the underlying multi-modal distributions)(例如同样的LR补丁可能有许多相应的HR补丁),重建的HR图像往往过于平滑,不接近人类对自然图像的视觉感知。第三,大多数方法在一个向上的采样步骤中重建HR图像,这增加了对大尺度因子(例如,8×)的训练的难度。此外,前一种方法不能在多个分辨率下生成中间SR预测。因此,我们需要为各种不同 目标上采样范围和计算负载(different desired upsampling scales and computational loads)的应用训练各种不同的模型。
为了解决这些缺点,我们提出了基于级联(a cascade of)卷积神经网络(CNNs)的Laplacian金字塔超分辨率网络(LapSRN)。我们的网络工作以一个LR的图像作为输入,并以一种粗到细的方式(in a coarse-to-fine fashion)逐步预测子带残差(sub-band residuals)。在每个层次(level)上,我们首先应用一个级联(a cascade of)卷积层(layers)来提取特征图。然后我们使用一个转置卷积层来将特征映射向上采样到一个更细的层次(a finer level)。最后,我们使用一个卷积层来预测子带残差(sub-band residuals)(在各自的层次上,向上采样的图像与地面真实的HR图像之间的区别)。每一层的预测残差被用来有效地重建HR图像,通过向上采样和其他的操作。虽然提议的LapSRN由一组级联子网络组成,但我们以端到端的方式( in an end-to-end fashion,without stage-wise optimization)用稳健的Charbonnier 损失函数( robust Charbonnier loss function)对网络进行训练。如下图1(e),我们的网络架构自然能容纳深度的监督(例如监控信号可以同时应用于金字塔的每一个层面上)。

图1:涂上表示了各个网络的结构图,红色的箭头表示卷积层,蓝色箭头表示反卷积(上采样),绿色箭头表示元素加法操作,橘色的箭头表示周期性的层
我们的算法在以下三个方面与现有的基于cnn的方法不同:
(1) 精度。提出的LapSRN提取方法直接从LR图像中提取t特征图,并用深度卷积层联合优化了上采样过滤器以预测子带残差。使用Charbonnier loss的深入监督提高了性能,因为它能更好地处理离群值(outliers)。因此,我们的模型有很大的容量来学习复杂的映射,并且有效地减少了artifacts。
(2)速度。我们的LapSRN既拥有快速处理速度,也拥有深度网络的高容量( high capacity of deep networks)。实验结果表明,我们的方法比基于CNN的超分辨率模型快得多,例如,SRCNN【7】、SCN 【33】、VDSR【17】和DRCN【18】。与FSRCNN 8相似,我们的LapSRN在大多数被评估的数据集上实现了实时速度。此外,我们的方法有更好的重建精度。
(3)渐进式重建(Progressive reconstruction)。我们的模型通过使用 Laplacian金字塔的渐进重建,在一个前馈式( in one feed-forward)中产生了多个中间SR预测。这一特性使我们的技术应用于广泛的应用程序( require resource-aware adaptability)。例如,同一个网络可以用来增强视频的空间分辨率,这取决于可用的计算资源。对于具有有限计算资源的ios来说,我们的8×模型仍然可以通过简单地绕过在更细的水平上的残差计算来执行2×或4×SR。然而,现有的基于cnn方法的方法并没有提供这种灵活性。
2.Related Work and Problem Context
文献中提出了大量的单图像超分辨率方法。在这里,我们将重点讨论最近基于实例的方法。
基于内部数据库的SR:一些方法【9、12】利用自然图像中的自相似性属性,基于低分辨率输入图像的尺度空间金字塔构造LR-HR补丁对。然而内部数据库包含的相关训练补丁比外部数据库要多,LR-HR补丁对的数量可能不足以覆盖图像中较大的纹理变化。Singh【29】等人将补丁分解成定向频率子带(directional frequency sub-bands ),并独立地在每个子带金字塔(sub-band pyramid)中确定更好的匹配。Huang等人【15】扩展了补丁搜索空间,以适应仿射变换和透视变形。基于内部数据库的SR方法的主要缺点是,由于在比例空间的金字塔中,补丁搜索的计算成本很高,所以它们的速度非常慢。
基于外部数据库的SR:大量的SR方法通过从外部数据库中收集的图像对学习LR-HR映射,使用监督学习算法,比如earest neighbor [10] manifold embedding [2, 5], kernel ridge regression [19], and sparse representation [37, 38, 39]。不是直接在整个数据库上对复杂的补丁空间进行建模,而是通过k均值【36】、稀疏字典【30】或随机森林【26】来划分图像数据库,并学习每个集群的局部线性回归。
基于SR的卷积神经网络:与在补丁空间中对LR-HR映射建模不同的是,SRCNN 【7】联合优化了所有的步骤,并在图像空间中学习了非线性映射。VDSR网络【17】通过将网络深度从3个层增加到20个卷积层,显示了对SRCNN 7的显著改进。为了促使训练出一个更快收敛速度的更深的模型,VDSR训练网络来预测剩余的值,而不是实际的像素值。Wang【33】等人将稀疏编码的领域知识与深度CNN结合起来,并训练一个级联网络(SCN),逐步将图像提升到所需的比例因子。Kim等人【18】提出了一个具有深度递归层(DRCN)的浅层网络,以减少参数的数量。
为了实现实时性能,ESPCN网络【28】提取了LR空间中的特征图,并用一个高效的子像素卷积(efficient sub-pixel convolution)取代了双三次上采样操作。FSRCNN网络【8】采用了类似的想法,使用了一个沙漏形(a hourglass-shaped)的CNN,它的层次比ESPCN上的要多,但参数更少。所有以上的基于cnn的sr的方法都是用L2 loss function 优化网络,但这通常会导致过于平滑的结果而使不符合人类的感知。在SR的背景下,我们证明了2个损失对于学习和预测稀疏残差的效果较差。
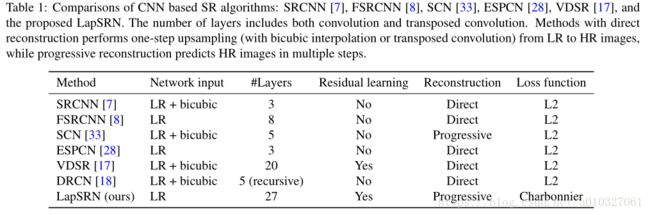
我们之前在 图1 中对比了各个方法的网络结构,现在我们在 表1 中列出现有的基于cnn方法和已经提出的框架之间的主要区别
我们的方法建立在现有的基于cnn的SR算法之上,有三个主要的区别: 1.我们用卷积和转置卷积层来共同学习残差和向上采样滤波器。使用学习得到的上采样滤波器不仅有效地抑制了由双三次插值引起的重构 artifacts,而且极大地降低了计算复杂度。 2.我们不是L2损失函数来处理离群值( outliers),而是利用一个强大的Charbonnier损失函数来优化深层网络,提高重建的准确性。 3.当提出的LapSRN逐步重构HR图像时,同样的模型可以应用于需要不同规模因子的应用程序,将网络截断到一定的级别。
Laplacian pyramid:Laplacian金字塔已经被广泛应用于各种各样的应用中,如图像混合(image blending) [4],纹理合成(texture synthesis) [14],边缘感知过滤(edge-aware filtering) [24]和语义分割(semantic segmentation) [11, 25]。Denton 等人提出了一种基于Laplacian金字塔框架(LAPGAN)的生成模型(generative model)以在[6]中生成逼真的图像,这是与我们的工作最相关的。然而,提出的LapSRN与LAPGAN的不同之处在于三个方面:
1.首先,LAPGAN是一种生成模型,它被设计成从随机噪音和样本输入中合成各种自然图像(synthesize diverse natural images)。相反,我们的LapSRN是一个超分辨率模型,它可以根据给定的LR映像来预测特定的HR映像。LAPGAN使用交叉熵损失函数( cross-entropy loss function)来使输出图像尊从训练数据集的数据分布。与此相反,我们使用Charbonnier惩罚函数(Charbonnier penalty function)来惩罚来自地面真值子带残余的预测偏差(penalize the deviation of the prediction from the ground truth sub-band residuals)。
2.其次,LAPGAN的子网络是独立的(即没有权重共享)。因此,网络容量受到每个子网络的深度的限制。与LAPGAN不同,LapSRN的每个层次上的卷积层通过多通道转置卷积层连接起来。因此,更高层次上的残差图像(residual images)是由一个在较低的层次上具有共享特征表示的较深的网络预测的( a deeper network with shared feature representations at lower levels)。较低层次的特性共享增加了在更细的卷积层(at finer convolutional layers)上的非线性,从而学习复杂的映射。此外,LAPGAN的子网络也得到了独立的培训。另一方面,在LapSRN中,所有用于特征提取、向上采样和残余预测层的卷积过滤器都是通过一种端到端的、深入监督的方式进行联合训练的。
3.第三,LAPGAN上采样图像是通过卷积,因此速度取决于HR图像的大小。相反,我们的LapSRN的设计,通过从LR空间中提取特性,有效地增加了感受野 receptive field的大小并加速了速度。我们在补充材料中提供了与LAPGAN的对比。
Adversarial training. (对抗训练)SRGAN方法【20】利用感知损失( the perceptual loss)【16】和与现实图片的对抗损失(the adversarial loss)来优化网络。我们注意到,我们的LapSRN可以很容易地扩展到对抗训练框架中。由于这不是我们的贡献,我们在补充材料中提供了对抗损失的实验。
3.Deep Laplacian Pyramid Network for SR
在本节中,我们描述了提出的Laplacian金字塔网络的设计方法,利用深度监督的鲁棒损失函数进行优化,以及网络训练的细节。
3.1. Network architecture
我们提出基于拉帕拉斯金字塔框架(Laplacian pyramid framework)来构造我们的网络,如图1(e)所示。我们的模型将一个LR图像作为输入(而不是一个上采样过的LR映像),并逐步预测在log2 S级别上的残差图像,S是比例因子。例如,该网络由3个子网络组成,用于超分辨LR图像的比例因子为8。我们的模型有两个分支:(1)特征提取和(2)图像重建。
Feature extraction. 在level s状态下,特征提取分支由d个卷积层和一个上采样因子为2的特征提取的反卷积层组成,以2的比例对提取的特征进行采样。每一个转置卷积层的输出连接到两个不同的层:(1)用于在s水平上重建残差图像一个卷积层;(2)用于在s+1水平上重建残差图像一个卷积层。请注意,我们只用一个转置卷积层,在粗糙的分辨率下执行特性提取,更高分辨率下生成特征映射。与现有的在高分辨率下执行所有特征提取和重建网络相比,我们的网络设计大大降低了计算复杂度。请注意,低级别的特征表示与更高的级别共享,因此可以增加网络的非线性,从而在更细的级别上学习复杂的映射。
Image reconstruction. 在level s状态下,输入图像通过一个转置卷积层被2比例上采样。我们用双线性内核初始化这一层,并允许它与所有其他层一起进行优化。然后将上采样得到的图像和来自特征提取分支的预测的残差图像组合起来(使用元素求和)来生成高分辨率的输出图像。然后将输出的HR图像输入到级别s+1的图像重建分支中。整个网络是一个由相同的结构在每个层次上的cnn级联。
3.2. Loss function
假设x为输入的LR映像,θ是一系列需要被优化的网络参数集。我们的目标是学习生成接近真实HR影像y(ground truth HR image)的高分辨率图像![]() 的映射函数f,即
的映射函数f,即![]() 。我们把level s 的残差图像表示为
。我们把level s 的残差图像表示为![]() ,把上采样的LR影像表示为
,把上采样的LR影像表示为![]() ,他对应的HR影像为
,他对应的HR影像为![]() ,在level s 层输出的HR影像为:
,在level s 层输出的HR影像为:![]() 。我们在每一个层次用双三次降采样对真实的HR影像y 调整到ys大小。我们在这里使用一个健壮的损耗函数来处理离群值,而不是最小化
。我们在每一个层次用双三次降采样对真实的HR影像y 调整到ys大小。我们在这里使用一个健壮的损耗函数来处理离群值,而不是最小化![]() 之间的均方误差( the mean square errors)。总体损失函数的定义是:
之间的均方误差( the mean square errors)。总体损失函数的定义是:

其中![]() 是Charbonnier penalty function(a differentiable variant of L1 norm,L1范数的可微变型) [3],N是每批的训练样本数,L是我们金字塔的level数。根据经验,我们将其设置
是Charbonnier penalty function(a differentiable variant of L1 norm,L1范数的可微变型) [3],N是每批的训练样本数,L是我们金字塔的level数。根据经验,我们将其设置![]() 为1e -3。
为1e -3。
在提出的LapSRN中,每个 level s都有它的损失函数和相应的地面真值图像ys。这种multi-loss结构类似于分类【21】和边缘检测【34】中的深度监测网的。然而,在【21、34】中用于监督中间层的标签在整个网络中是相同的。在我们的模型中,我们在相应的层中使用不同尺度的HR图像作为监督。深度监督指导网络训练来预测不同层次的子带残留图像,并产生多尺度输出图像。例如,我们的8×模型可以在一个前馈传递中产生2×、4×和8×的超级分辨率的结果。这个属性对于资源敏感的应用程序(resource-aware applications)特别有用,例如,移动设备或网络应用程序。
3.3. Implementation and training details
在提出的LapSRN中,每个卷积层由64个过滤器组成,大小为3×3。我们使用He等人【13】的方法初始化卷积滤波器。转置卷积滤波器的大小是4× 4,权重是从一个双线性滤波器(a bilinear filter)中初始化的。所有的卷积和转置卷积层(除了重建层)都伴随着一个 leaky rectified linear units (LReLUs),斜率为 -0.2。在应用卷积之前,我们在边界上补0,以保持所有特征图的大小与每个层次的输入相同。卷积滤波器具有小的空间支持 small spatial supports(3×3),但是,我们可以达到高的非线性,并用深度结构增加接受域(receptive fields)的大小。
我们使用来自Yang 等【38】的91张图片和伯克利的分割数据集( Berkeley Segmentation Dataset)【1】的200张图片作为我们的训练数据。【17、26】中也使用的同样训练数据集。在每个批训练( training batch)中,我们随机抽取64个大小为128×128补丁。一个 epoch 有1000次的反向传播迭代。我们以三种方式增加训练数据:(1)缩放( Scaling):随机地下采样比例为[0.5-1.0]。(2)旋转( Rotation):随机旋转图像90°,180°,或270°。(3)翻转(Flipping):水平或垂直翻转图像 with a probability of 0.5。按照现有方法【7、17】的协议,我们使用双三次下采样生成LR训练补丁。我们用 MatConvNet toolbox [31]来训练我们的模型。我们把动量参数( momentum parameter)设为0.9,权重衰减到1e -4。所有层的学习率被初始化为1e-5,每50个epochs学习率减少了2个因子。
4. Experiment Results
我们首先分析了所提出的网络不同组成部分的贡献。然后我们将我们的LapSRN与5个基准数据集( benchmark datasets)的最先进的算法进行比较,并演示我们的方法在超解析真实世界的照片(super-resolving real-world photos )和视频上的应用。
4.1. Model analysis
Residual learning.为了演示残差学习的效果,我们删除了图像重建分支( branch),并直接预测了每个层次的HR图像。图2显示了DET14数据for 4× SR中PSNR的收敛曲线(convergence curve),非剩余网络( “non-residual” network蓝色曲线)收敛缓慢( converges slowly)且波动较大( fluctuates significantly.)的。另一方面,提出的LapSRN(红色曲线)在10个epochs内优于SRCNN。


Loss function. 为了验证( validate)Charbonnier损失函数的影响,我们用L2损失函数对所建议的网络进行了训练。我们使用更大的学习速率(1e- 4),因为L2的梯度幅值更小。如图2所示,用L2 loss优化的网络(绿线)需要更多的迭代(iterations)才能在SRCNN中获得类似的性能。在图3(d)中,我们展示了用L2损失训练的网络产生了更多的 ringing artifacts。与此相反,由所提的算法重构的SR图像(图3(e))包含相对清晰和清晰的细节。
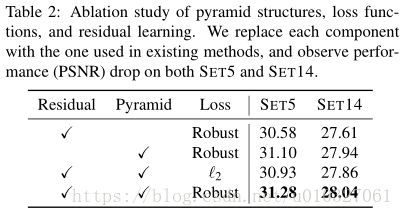
Pyramid structure.通过移除金字塔结构(pyramid structure),我们的模型可以变成类似于FSRCNN的网络,但是有 residual learning。我们使和LapSRN相同数量的卷积层,我们训练一个有10个卷积层和一个转置卷积层的网络。表2中的量化结果表明,金字塔结构导致了适度的性能改进 moderate performance improvement(例如,在S ET 5上的0.7 dB和S ET 14上0.4 dB)。
Network depth.我们在每个层次上对模型进行了不同深度的训练,d=3,5,10,15,在表3中展示了性能和速度之间的权衡(tradeoffs)。一般来说,深度网络以增加计算成本为代价,使浅层网络效果更好。我们为2×和4×SR模型选择d=10,以在性能和速度之间取得平衡( strike a balance )。我们发现,我们的LapSRN深度为10的速度比大多数现有的基于cnn的sr算法速度快(见图6)。对于8×模型,我们选择d=5,因为我们使用更多的卷积层没有观察到显著的性能提升。

4.2. Comparisons with the state-of-the-arts
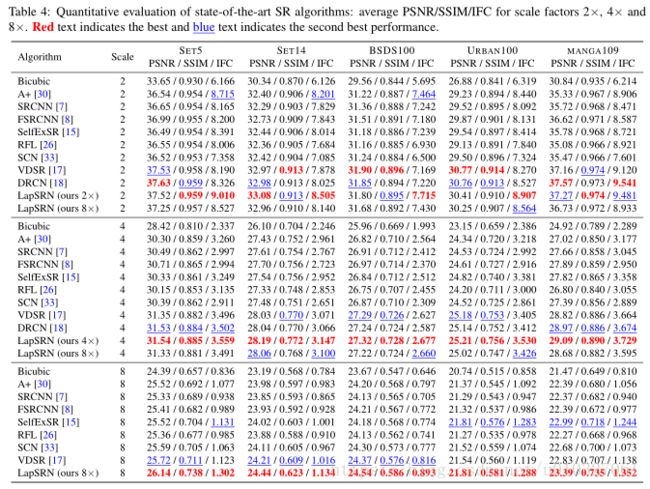
我们将LapSRN与8种最先进的SR算法进行比较: A+ [30], SRCNN [7], FSRCNN [8],SelfExSR [15], RFL [26], SCN [33], VDSR [17] and DRCN [18]。我们用5个数据集进行了广泛的实验: S ET 5 [2], S ET 14 [39], BSDS100 [1], U RBAN 100 [15] and MANGA 109 [23]。在这些数据集中,S ET 5, S ET 14 and BSDS100包含的是自然场景(natural scenes);U RBAN 100中包含具有挑战性的包含不同频率波段的细节城市场景图像; MANGA 109是日本漫画的一个数据集。我们训练LapSRN,直到学习速率降低到1e -6,并且在泰坦X GPU上的训练时间大约是3天。
我们用三种常用的图像质量指标来评估(evaluate)SR图像: PSNR, SSIM [32], and IFC [27]。表4显示了2×、4×和8× SR的定量比较( quantitative comparisons),我们的LapSRN在大多数数据集上比现有方法表现良好(performs favorably)。特别地,我们的算法实现了更高的IFC值,IFC 被证明与人类对图像超分辨率[35]的感知密切相关。我们注意到,最好的结果可以通过特定的 scale factors(我们的2×和4×)来实现。当中间的卷积层(intermediate convolutional layers)被训练来最小化相应级别和更高层次的预测误差(prediction errors)时,我们的8×模型的中间预测略稍微( slightly inferior to)没有我们的2×和4×模型效果好。虽然如此,我们的8×模型在2×和4× SR中的其他先进的方法中仍有一定的竞争力。
在图4,我们对比例因子为4的U RBAN 100,BSDS100和MANGA 109展示了视觉比较(visualcomparisons)。我们的方法精确地重新构造了平行直线和网格模式( parallel straight lines and grid pattern),如窗户和老虎的条纹。我们观察到,使用bicubic向上采样进行预处理的方法可以产生明显的artifacts[7、17、26、30、33]。相反,我们的方法通过渐进重构和健壮的损失函数(progressive reconstruction and the robust loss function.)有效地抑制了这些( suppresses such artifacts)。

对于8× SR,我们使用公开的代码重新训练A+、SRCNN、FSRCNN、RFL和VDSR的模型。使用渐进重构方法,Both SelfExSR and SCNmethods可以处理不同的尺度因子。我们在图5中显示了BSDS100和U RBAN 100的 8× SR结果。对于8× SR来说,从bicubic上采样的图像【7、17、30】或使用一步向上的采样【8】来预测HR图像是很有挑战性的。最先进的方法不能很好地解决好结构( super-resolve the fine structures well)。与此相反,LapSRN以相对较快的速度重新构建高质量的HR图像。我们在补充材料中展示了所有被评估的方法所产生的SR图像。
4.3. Execution time
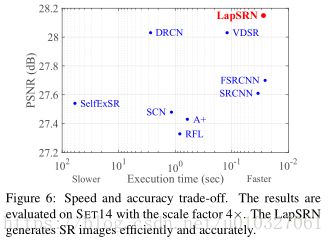
我们使用最先进的方法的原始代码使用相同的机器来进行评估,使用的是 3.4GHz Intel i7 CPU (64G RAM) and NVIDIA Titan X GPU(12G Memory)。因为SRCNN和FSRCNN用于测试的代码是基于CPU实现的,我们使用相同的网络权重在MatConvNet上重建这些模型,来测量他们在GPU上的运行时间。图6显示了在S ET 14上4 ×SR 的运行时间和性能(在PSNR上)之间的权衡(trade-offs),LapSRN的速度比FSRCNN的所有现有方法(除了FSRCNN)都要快。我们在补充材料中对所有评估数据集的运行时间进行详细的评估。

4.4. Super-resolving real-world photos
我们展示了一个带有 JPEG compression artifacts的超分辨率历史图像来( super-resolving historical photographs)的应用。在这些情况下,既没有地面实况图像(ground-truth images),也没有下采样的内核( downsampling kernels)。如图7所示,我们的方法可以比最先进的方法重建出更清晰、更准确的图像。
4.5. Super-resolving video sequences
我们在22个视频序列中进行基于帧( frame-based)的SR实验,其空间分辨率为1200×800像素。我们对每一帧进行了8×的采样,然后分别对2×、4×和8×进行了超分辨率帧重建。计算成本依赖于输入图像的大小,因为我们从LR空间中提取特性。相反,SRCNN和VDSR的速度受到输出图像大小的限制。FSRCNN和我们的方法在所有的上采样尺度上都实现了实时性能(超过30帧/秒)。与之相反,在8× SR 下FPS的FPS是8.43,VDSR是1.98。图8可视化了一个代表性框架上的8×SR的结果。
4.6. Limitations
虽然我们可以在很大的范围内获得clean and sharp的HR图像,例如,8×,但它并没有产生任何细微的细节(“hallucinate” fine details)。如图9所示,在8×下采样的LR 影像的建筑物的顶部非常模糊。所有的SR算法都不能恢复精细结构,除了 SelfExSR [15],它明确的(explicitly)检测到3D场景的几何形状,并使用自相似性来构造常规结构(hallucinate the regular structure)。这是由参数SR(parametric SR)方法【7、8、17、18】共享的一个常见限制。网络的另一个限制是相对较大的模型大小。为了减少参数的数量,可以用递归层替换每个层次上的深层卷积层。
5. Conclusions
在这项工作中,我们提出了一个在 Laplacian pyramid framework上的深度卷积网络,用于快速和精确的单图像超级分辨率。我们的模型以粗到细的方式( in a coarse-to-fine manner)逐步预测高频残差。通过将预先定义的双三次插值替换为已学习的转置卷积层,并利用一个 robust loss function来优化网络,LapSRN可以 减轻undesired artifacts ,并降低计算复杂度。对基准数据集( benchmark datasets)的广泛评估表明,在视觉质量和运行时间方面,该模型相对最先进的SR算法具有良好的性能。
Acknowledgments & References
略
此时在回过头看之前的大纲,你会有更深刻的理解:https://blog.csdn.net/royole98/article/details/79617550