OpenCV中的KMeans算法介绍与应用

一、KMeans算法介绍
KMeans算法是MacQueen在1967年提出的,是最简单与最常见的数据分类方法之一。它做为一种常见数据分析技术在机器学习、数据挖掘、模式识别、图像分析等领域都有应用。如果从分类角度看,KMeans属于硬分类即需要人为指定分类数目,而MeanSift分类方法则可以根据收敛条件自动决定分类数目。从学习方法上来说,KMeans属于非监督学习方法即整个学习过程中不需要人为干预的学习方法,自动完成整个数据集合分类。对于给定的数据集合DS (Data Set)与输入的分类数目K,KMeans的整个工作原理可以描述如下:
1. 根据输入的分类数目K定义K个分类,每个分类选择一个中心点
2. 对DS中每个数据点做如下操作:
- 计算它与K个中心点之间的距离
- 把数据点指定属于K个中心点中距离最近的中心点所属的分类
3. 对K个分类中每个数据点计算平均值得到新的K个中心点
4. 比较新K个中心点之间与第一步中已经存在的K个中心差值
- 当两者之间的差值没有变化或者小于指定阈值,结束分类
- 当两者之间的差值或者条件不满足时候,用新计算的中心点值做为K个分类的新中心点,继续执行2~4步。直到条件满足退出。
从数学的角度来说KMeans就是要找到K个分类而且他们的中心点到各个分类中各个数据的之间差值平方和最小化,而实现这个过程就是要通过上述2~4步不断的迭代执行,直到收敛为止。公式表示如下:

以上是KMeans算法的基本思想,想要实现或者应用该算法有三个注意点值得关注:
1. 初始的K个分类中每个分类的中心点选择,多数的算法实现都是支持随机选择与人工指定两种方式,OpenCV中的KMeans实现同样支持这两种方式。
2. 多维数据支持,多数时候我们要分类的特征对象的描述数据不止一个数据特征,而是一个特征向量来表示,OpenCV中通过Mat对象构建实现对多维数据KMeans分类支持。
3. 收敛条件 - 一般情况下在达到指定的迭代次数或者两次RSS差值小于给定阈值的情况下,结束执行分类处理,输出最终分类结果。
下图是一个例子,黑色的点代表数据点,十字表示中心点位置,初始输入的分类数目K=2时,KMeans各步执行结果:
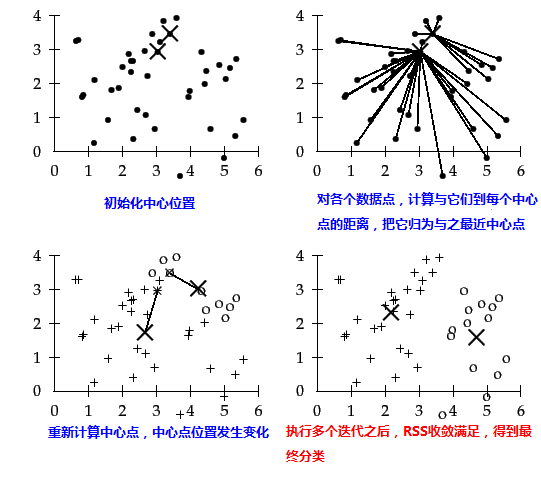
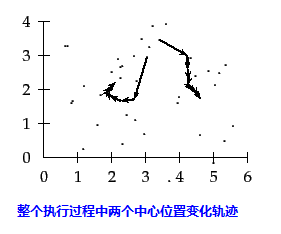
二、OpenCV中KMeans相关函数说明
KMeans是OpenCV核心模块的一个API函数。

各个参数的详细解释如下:
- data表示输入的数据集合,可以一维或者多维数据,类型是Mat类型,比如:
Mat points(count, 2, CV_32F)
表示数据集合是二维,浮点数数据集。
- K表示分类的数目,最常见的是K=2表示二分类。
-bestLabels表示计算之后各个数据点的最终的分类索引,是一个INT类型的Mat对象。
-criteria表示算法终止的条件,达到最大循环数目或者指定的精度阈值算法就停止继续分类迭代计算。
- attempts表示为了获得最佳的分类效果,算法要不同的初始分类尝试次数
- flags表示选择初始中心点选择方法用哪一种
KMEANS_RANDOM_CENTERS 表示随机选择中心点
KMEANS_PP_CENTERS 基于中心化算法选择
KMEANS_USE_INITIAL_LABELS第一次分类中心点用输入的中心点
- centers表示输出的每个分类的中心点数据。
三、应用案例-利用KMeans实现图像分割
KMeans在图像处理中经典应用场景就是根据用户输入的分类数目实现图像自动区域分割,本例就是基于OpenCV KMeans函数实现图像的自动分割, 对彩色图像来说,每个像素点都有RGB三个分量,整个图像可以看成是一个3维数据集合,只要把这个三维数据集作为输入参数传给KMeans函数即可,算法执行完毕之后,根据分类标记的索引设置不同的颜色即可。所以演示程序的实现步骤如下:
1. 将输入图像转换为数据集合
2. 使用KMeans算法对数据实现分类
3. 根据每个数据点的分类索引,对图像重新填充颜色,显示分割后图像。
运行效果如下:

完整的代码实现如下:
- #include
- #include
- usingnamespace cv;
- usingnamespace std;
- int main(intargc, char** argv) {
- Mat src = imread("D:/vcprojects/images/toux.jpg");
- imshow("input", src);
- int width = src.cols;
- int height = src.rows;
- int dims = src.channels();
- // 初始化定义
- int sampleCount = width*height;
- int clusterCount = 4;
- Mat points(sampleCount, dims, CV_32F, Scalar(10));
- Mat labels;
- Mat centers(clusterCount, 1, points.type());
- // 图像RGB到数据集转换
- int index = 0;
- for (int row = 0; row < height; row++) {
- for (int col = 0; col < width; col++) {
- index = row*width + col;
- Vec3b rgb = src.at
(row, col); - points.at
(index, 0) = static_cast (rgb[0]); - points.at
(index, 1) = static_cast (rgb[1]); - points.at
(index, 2) = static_cast (rgb[2]); - }
- }
- // 运行K-Means数据分类
- TermCriteria criteria = TermCriteria(CV_TERMCRIT_EPS + CV_TERMCRIT_ITER, 10, 1.0);
- kmeans(points, clusterCount, labels, criteria, 3, KMEANS_PP_CENTERS, centers);
- // 显示图像分割结果
- Mat result = Mat::zeros(src.size(), CV_8UC3);
- for (int row = 0; row < height; row++) {
- for (int col = 0; col < width; col++) {
- index = row*width + col;
- int label = labels.at
(index, 0); - if (label == 1) {
- result.at
(row, col)[0] = 255; - result.at
(row, col)[1] = 0; - result.at
(row, col)[2] = 0; - }
- elseif (label == 2) {
- result.at
(row, col)[0] = 0; - result.at
(row, col)[1] = 255; - result.at
(row, col)[2] = 0; - }
- elseif (label == 3) {
- result.at
(row, col)[0] = 0; - result.at
(row, col)[1] = 0; - result.at
(row, col)[2] = 255; - }
- elseif (label == 0) {
- result.at
(row, col)[0] = 0; - result.at
(row, col)[1] = 255; - result.at
(row, col)[2] = 255; - }
- }
- }
- imshow("kmeans-demo", result);
- //imwrite("D:/vcprojects/images/cvtest.png", result);
- waitKey(0);
- return 0;
- }
作者:贾志刚
来源:51CTO