转一篇关于神经网络的小品文
https://mp.weixin.qq.com/s?__biz=MzA4MTA5MjE5Mw==&mid=401758390&idx=1&sn=a870201b307b6531abfe9c571461876e&scene=1&srcid=0122t2d7CyeurEFwtlp2ya3k&pass_ticket=5vlHG30VriwzFjNjxIzDT9YjTp2c0tOsRclaa6RliQEmlEGduKOiY9XcBWb0Yoq5#rd
1.开场先扔个段子
在互联网广告营销中,经常会有这样的对话:
问:你们的人群标签是什么样的?
答:我们是专门为您订制的look-alike标签!
问:好吧,你们的定向算法能不能说明一下?
答:我们用的是deep learning技术!
一般来说,话题到此,广告主会因为自己理论知识的匮乏而羞愧得无地自容。唯一的办法就是先透过投放广告的方式先学习起来。
——刘鹏《广告技术公司十大装逼姿势》
像deep learning、DNN、BP神经网络等这些高逼格的词,真的很能吓唬人,但真正的内容什么,很多人却解释得不多,要么说得太晦涩,要么说得太神叨。其实,就我们的粗浅了解,神经网络、深度学习啥的,入门还是很容易的。如果去除外面浮夸的包装,它们的理论基础也相当直白。当然这并不是说神经网络不难,它们真正难的地方是在实践方面,但这也是有方法可处理的。为了浅显易懂地给大家解释这个过程,我们开设了“手把手入门神经网络系列”。
在本篇文章中,我们依然少用公式多画图,只用初等数学的知识解释一下神经网络。
2.神经网络有什么牛逼之处?
机器学习算法这么多,为什么神经网络这么牛逼?
为了解释这个问题,我们呈现了神经网络在分类问题上优于逻辑回归的地方——它几乎可以实现任意复杂的分类边界,无误差地实现训练集上的分类。
然而,这是有代价的:由于其强大的拟合能力,极容易产生过拟合。为了降低过拟合,我们介绍了一种降低过拟合的思路。
在这个过程中,我们尽量解释神经网络每一步操作对应的现实意义和最终目的。可是,神经网络的可解释性往往是个非常大的难题。为此,我们采用了最易于理解的“交集”(逻辑与)、“并集”(逻辑或)神经网络,希望能帮助大家进行启发式理解。
但是,神经网络的问题并没有解决完。之后,我们引出了用神经网络的一些典型问题,我们将在接下来的系列文章对其进行深入探讨。
3.从逻辑回归到神经网络
神经网络主要应用场景之一是分类,我们之前博文中提到的逻辑回归也是解决分类问题的一类机器学习算法,有趣的是,实际上两者有着很紧密的关系,而逻辑回归作为帮助我们理解神经网络的切入口也是极好的,所以我们先从逻辑回归开始。看过本我们前文《机器学习系列(2)_用初等数学解读逻辑回归》的读者盆友应该会有个印象,逻辑回归可以理解成将空间中的点经过一系列几何变换求解损失函数而进行分类的过程,具体过程如图:

具体分析一下我们所求的“参数” 的几何意义,(θ1,θ2)就是图中法向量p的方向,θ0 对应着法向量p的起点距离坐标系原点的偏移。在神经网络中,向量(θ1,θ2)也叫做权重,常用w表示;θ0就叫做偏移,常用b表示。
而上面的逻辑回归过程,用神经元的表达方式如下,这就是传说中的“感知器”:
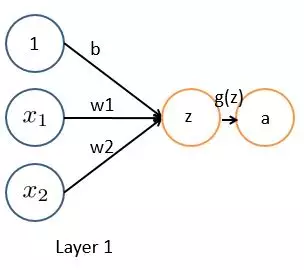
其中,z=θ0+θ1X1+θ2X2,a=g(z)=11+e−z ,g(z)叫做激励函数
逻辑回归的激励函数自然就是sigmoid函数,输出值a对应着输入样本点x(X1,X2)在法向量p所指向的那部分空间的概率。本文为了兼容逻辑回归,只考虑sigmoid函数作为激励函数的情况,而且这也是工业界最常见的情况。其他激励函数的选择将会在后面系列文章继续介绍。
补充说明一下,以上只是为了表示清晰而这样画神经网络。在一般的神经网络画法中,激励函数的操作节点会与输出节点写成同一个节点,如下图:
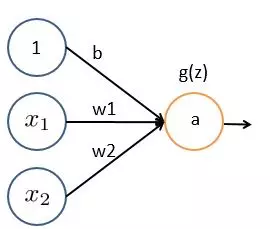
好了,到此为止,神经网络相对于逻辑回归没有提供任何新的知识,就是换了个花样来表示。
但神经网络这样表示有个重大的作用:它方便我们以此为基础做逻辑回归的多层组合嵌套——比如对同样的输入x(X1,X2)可以同时做n个逻辑回归,产生n个输出结果,这就是传说中的“单层感知器”或者叫“无隐层神经网络”。示意图如下:
你还可以对n个逻辑回归的n个输出再做m个逻辑回归,这就是传说中的“单隐层神经网络”。示意图如下:
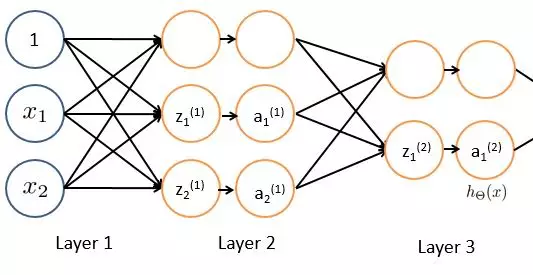
如果你愿意,可以继续做下去,子子孙孙无穷匮也:
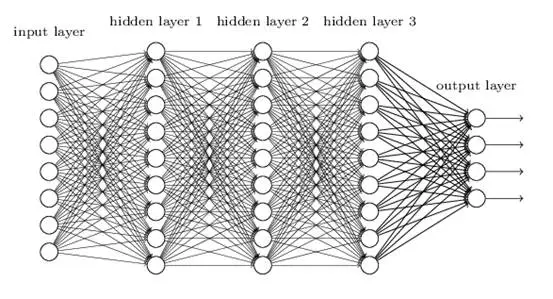
最左边的层叫做输入层,最右边的层叫做输出层,二者之间的所有层叫做隐藏层。
如果层数比较少,就是传说中的SNN(shallow nerual network) “浅层神经网络”;如果层数比较多,就是传说中的DNN(Deep Neural Networks) “深度神经网络”。对“浅层神经网络”的建模叫做“浅层学习”,那么对于“深度神经网络”……“深度学习”!
恭喜你已经会抢答了!
到目前为止,我们没有运用任何更多的数学知识,就已经收获了一大批装逼术语。
如果你愿意,把上面的所有情况叫做“逻辑回归的逻辑回归的逻辑回归的逻辑……”,我也觉得蛮好哈。(喘不过气来了……)
4.双隐层神经网络彻底实现复杂分类
我们之前已经探讨过,逻辑回归的比较擅长解决线性可分的问题。对于非线性可分的问题,逻辑回归有一种运用复杂映射函数的思路,但这种思路只做了一次(非线性的)几何变换,就得到了线性可分的情形。可参考下图:

神经网络的视角则给我们提供了另一种思路,可以连续做几次的几何变换,每次变换都是一些极简单的逻辑回归,最终达到线性可分情形。看起来似乎很不错哦。比如下面这个貌似很简单的问题,我们怎么找出他的分离边界?
发现无论怎么用一条直线切都不行。那么两条直线行不行?
这么看确实是可以的,我们只需要把两个”半平面”取交集就可以找到一个楔形区域的非线性分离边界了,而且并不是唯一的解。因此我们发现如果允许对同一个输入做多种不同的逻辑回归,再对这些结果取交集,就可以解决很大一部分非线性可分问题。
那么,对于取交集怎么用逻辑回归表达?我们考虑两个输入的情况,每一个输入是样本点x(X1,X2)属于某一个”半平面”的概率,取交集意味着该样本点属于两个”半平面”的概率均接近于1,可以用一条直线将其区分开来。
可见,对于交集运算,通过选取合适的权重和偏移,就可以得到一个线性的分离边界。这也就是所谓用神经元实现“逻辑与”运算,这是神经网络的一个常见应用:
以上过程如果用神经网络来展现的话,可以设计成一个单隐层神经网络,每层的节点数依次为:3、3、1,如下如图:
解释下每一层的作用:
第一层是输入层,对应着每一个输入的二维样本点x(X1,X2)的2个输坐标和1个辅助偏移的常量“1”,总共3个节点。
第二层是第一层的输出层,每个节点对应着输入样本点属于某个”半平面”的概率,该”半平面”的正向法向量就对应着输入层(输入样本点坐标)到该节点的权重w和偏移b。为了定位中间这2个X点,我们围绕它们上下切2刀,用2个”半平面”相交产生的楔形开放凸域定位这2个X点,所以这一层对应着总共产生了的2个”半平面”,有2个节点。第二层同时也是第三层的输入层,要考虑再加上求第三层节点时要用的1个辅助偏移的常量节点“1”,第二层总共有2+1=3个节点。
第三层是第二层也是整体的输出层,输出节点对应着输入样本点属于楔形开放凸域的概率,也就是与这2个X点属于同一类的概率。
但是这种方法有局限,这些直线分割的”半平面”取的交集都有个特点,用专业的说法“都是凸域的”——其边界任意两点的连线都在域内。如下图各个色块,每一个色块都是一个凸域。
单独一个凸域的表现能力可能不是很强,无法构造一些非凸域的奇怪的形状。于是我们考虑是不是把n个凸域并在一起,这样就可以组成任意非凸域的奇葩的形状了:如上图所有彩色色块拼起来的区域。那对应于神经元是怎么一个操作?……再加一层,取他们的并集!
恭喜你又会抢答了。
而取并集就意味着该样本点属于两个”半平面”的概率至少有一个接近于1,也可以用一条直线将其区分开来。
可见,对于并集运算,通过选取合适的权重和偏移,也可以得到一个线性的分离边界。这就是所谓用神经元实现“逻辑或”运算,这也是神经网络的一个常见应用:
我们用一下这张图总结上面所说的内容,一图胜千言唉:
数学家们经过严格的数学证明,双隐层神经网络能够解决任意复杂的分类问题。
5.以三分类问题为例演示神经网络的统一解法
对于一切分类问题我们都可以有一个统一的方法,只需要两层隐藏层。以下面这个3分类问题为例:
我们通过取”半平面”、取交集生成精确包含每一个样本点的凸域(所以凸域的个数与训练集的样本的个数相等),再对同类的样本点的区域取并集,这样无论多复杂的分离界面我们可以考虑进去。于是,我们设计双隐层神经网络结构如下,每一层的节点数依次为:3、25、7、3:
解释下每一层的作用:
第一层是输入层,对应着每一个输入的二维样本点x(X1,X2)的2个输坐标和1个辅助偏移的常量“1”,总共3个节点。
第二层是第一层的输出层,每个节点对应着输入样本点属于某个”半平面”的概率,该”半平面”的正向法向量就对应着输入层(输入样本点坐标)到该节点的权重w和偏移b。为了精确定位总共这6个点,我们围绕每个点附近平行于坐标轴切4刀,用四个”半平面”相交产生的方形封闭凸域精确包裹定位该点,所以这一层对应着总共产生了的4*6=24个”半平面”,有24个节点。第二层同时也是第三层的输入层,要考虑再加上求第三层节点时要用的1个辅助偏移的常量节点“1”,第二层总共有24+1=25个节点。
第三层是第二层的输出层,每个节点对应着输入样本点属于第二层区分出来的某4个”半平面”取交集形成的某个方形封闭凸域的概率,故总共需要24/4=6个节点。因为采用我们的划分方式,只需要四个”半平面”就可以精确包裹某一个样本点了,我们认为其他的”半平面”贡献的权重应该为0,就只画了生成该凸域的四个”半平面”给予的权重对应的连线,其他连线不画。第三层同时也是第四层的输入层,要考虑再加上求第四层节点时要用的1个辅助偏移的常量节点“1”,第三层总共有6+1=7个节点。
第四层是第三层的输出层,每个节点对应着输入样本点属于某一类点所在的所有区域的概率。为找到该类的区分区域,对第三层属于同一类点的2个凸域的2个节点取并集,故总共需要6/2=3个节点。(同样,我们不画其他类的凸域贡献的权重的连线)
小结一下就是先取”半平面”再取交集最后取并集。
如果看文字太累,请看下图。只可惜图太小,省略了很多节点,请见谅。如果觉得还是有些问题,欢迎在评论区中参与讨论哈。
6.一种降低过拟合的方法
我们的确有了一个统一的解法。但估计很多同学看到还没看完就开始吐槽了:“总共也就6个样本,尼玛用了32个隐藏节点,训练111个(24*3+6*5+3*3)参数,这过拟合也太过分了吧!”
的确如此,这个过拟合弄得我们也不忍直视。如果我们多增加几个样本,就会发现上面训练出来的模型不够用了。
通过这个反面教材我们发现,神经网络是特别容易过拟合的。而如何降低过拟合就是神经网络领域中一个非常重要的主题,后面会有专文讨论。本例只是简单应用其中一个方法——就是降低神经网络的层数和节点数。
我们仔细观察样本点的分布,发现每两个类别都可以有一条直线直接将它们分开,这是所谓的one-vs-one的情况,用三条直线就可以完全将这些类别区分开来。
相应的,我们只需要求出每两个类别的分离直线,找出每个类别所属的两个半平面,对它们求一个交集就够了。神经网络结构如下:
解释下每一层的作用:
第一层是输入层,对应着每一个输入的二维样本点x(X1,X2)的2个输坐标和1个辅助偏移的常量“1”,总共3个节点。
第二层是第一层的输出层,每个节点对应着输入样本点属于某个”半平面”的概率,该”半平面”的正向法向量就对应着输入层(输入样本点坐标)到该节点的权重w和偏移b。因为3个”半平面”足以定位每一个类型的区域,所以这一层有3个节点。第二层同时也是第三层的输入层,要考虑再加上求第三层节点时要用的1个辅助偏移的常量节点“1”,第二层总共有3+1=4个节点。
第三层是第二层的输出层,每个节点对应着输入样本点属于第二层区分出来的某2个”半平面”取交集形成的某个开放凸域的概率。我们同样认为其他的”半平面”贡献的权重应该为0,就只画了生成该凸域的2个”半平面”给予的权重对应的连线,其他连线不画。只是这里与上面例子的情况有一点小小的不同,因为一个分离直线可以区分出两个“半平面”,两个“半平面”都被我们的利用起来做交集求凸域,故每个第二层的节点都引出了两条权重的连线到第三层。而这取交集的结果足以定位每一个类型的区域,因此第三层也就是总体的输出层。故第三层总共需要3个节点。
在这里,我们只用了1个隐藏层4个节点就完成了分类任务,能够识别的样本还比之前多。效果是很明显的。
从以上推导我们可以得出一个启发式的经验:通过适当减少神经元的层数和节点个数,可以极大地提高计算效率,降低过拟合的程度。我们会在另一篇文章中有更加全面系统的论述。
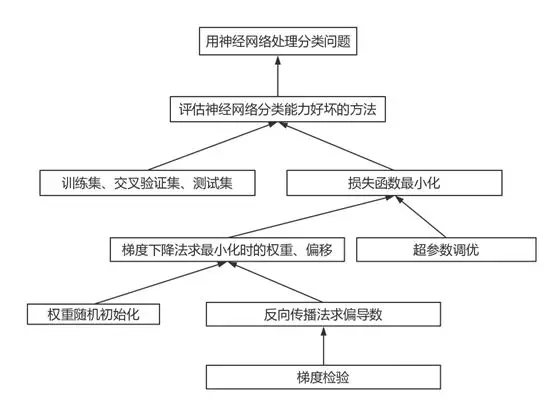
7.然而,问题真的解决了吗?
其实并没有。
我们凭什么知道上面改进的模型还有没有过拟合?
其实我们并不知道。因此我们需要更加科学客观的方法进行评估模型。
降低神经网络过拟合的方式有哪些?
我们凭什么知道我们的节点数和隐藏层个数的选择是合适的?
我们刚才只是直接是画出了分界线和相应的神经元组合。问题是,很多时候你并不知道样本真实的分布,并不知道需要多少层、多少个节点、之间的链接方式怎样。
我们怎么求出这些(超)参数呢?
假设我们已经知道了节点数和隐藏层数,我们怎么求这些神经元的权重和偏移呢?
最常用的最优化的方法是梯度下降法。求梯度就要求偏导数,但是你怎么求每一个权重和偏移的偏导数呢?
假设我们已经知道了传说中的BP算法,也就是反向传播算法来求偏导数。但是对于稍微深一点的神经网络,这种方法可能会求出一些很奇葩的偏导数,跟真实的偏导数完全不一样,导致整个模型崩溃。那么我们怎么处理、怎么预防这样的事情发生呢?
为什么神经网络这么难以训练?
除掉逻辑回归类型对应的sigmoid激励函数神经元,还有很多其他的激励函数,我们对不同的问题,怎么选择合适的激励函数?
神经网络还有其他的表示形式和可能性吗?
怎样选择不同的神经网络类型去解决不同的问题?
…….
其实,本文举例中将后几层的神经网络直接解释成做交集、并集的“与”、“或”逻辑运算,这些技术很早就出现了,神经网络依然只是对它们的包装,并不能显示神经网络有多强大。神经网络的独特特点是它能够自动调整到合适的权重,不拘泥于交集、并集等逻辑运算对权重的限制。而神经网络真正的威力,是它几乎可以拟合一切函数。它为什么这么牛?怎么解释神经网络的拟合特性呢?能不能形象地解释一下?也将是我们下一步需要探讨的问题。
……
可见,神经网络深度学习有很多问题还没有解决。我们会在接下来的文章中一一与大家探讨。
但是这么多问题从哪入手?其实,我们觉得,直接给大家一个栗子,解决一个真实的问题,可能更容易理解。所以下一篇文章我们将给大家演示怎么用神经网络计算解决问题,并做进一步的启发式探讨。而且,我们将会发码——让大家之间在自己的电脑上运行python代码——来进行手写数字的识别。你们猜猜代码有多短?只有74行!