爬虫入门实战系列(五)通过【selenium进行Ajax模拟爬取】·网易云音乐评论
前言:一些网页可能通过Ajax来实现页面局部的动态加载,那么前面基于静态网页爬取的方法就不稳了。
AJAX简介(来自菜鸟教程):
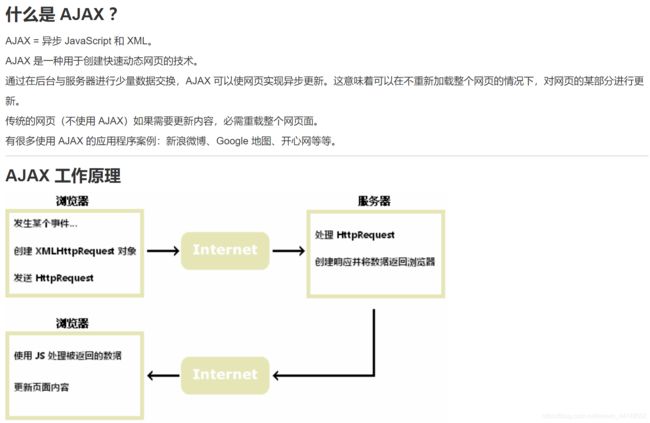
原理上简单说,就是在浏览网页更新时,向服务器发起的(HttpRequest)请求会得到返回数据响应,而返回的数据会经过JS处理,并实现页面(部分)相应内容的更新。
零、先观察一波情况
爬取评论站点:https://music.163.com/#/song?id=32835565 ,观察规律只有id=xxx,改了一下发现id是不同曲目的编号。
点击进入网页后,还是先按F12,拖动到下部评论区,然后ctrl+shirft+c看一下评论文本的对应标签,并尝试翻页评论区。
在这个过程中,可以注意到几点有意思的现象:
上下滑动网页时操作台里有个别标签的属性值出现了变化,评论区翻页后整体网页页面没有完全刷新,浏览器地址栏的url没变。
那么我们可以有一个初步的判断,评论区部分内容是在我们滑动进度条、点击翻页按钮控件时,触发了向服务器发起请求的动作,服务器端根据用户端发起的表单数据等信息,判断返回需要更新的部分数据,然后浏览器接收后使用JS处理并在页面上局部更新。
那么,(在翻页/滚动触发时)我们从浏览器端发起了什么样的HttpRequests呢?
一、从找到Ajax请求/响应开始
那么我们不妨找从浏览器向服务器发的的Ajax请求与服务器响应返回的数据康康~

Ajax是通过XHR(XLMHttpRequest的缩写~)来实现浏览器与服务器间交互的(不熟可以多看下AJAX工作原理图哈),我们可以先在工作台清除掉所有请求记录,再进行翻页操作,这时操作台就有了新的请求记录,时间轴也有了变化,我们就可以先通过时间轴选取最近的活动范围,或选择查看XHR类型的方式来缩小搜索范围。
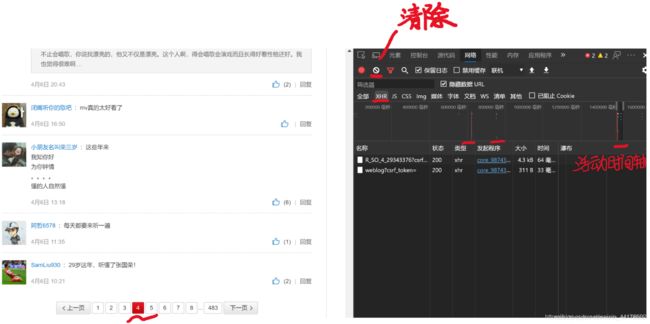
剩下两个XHR类型的请求,我们分别点开【Preview/预览】看看内容,发现第二个与评论内容无关,第一个里面有conmment(评论)标签,展开多级后果然就是它哩~
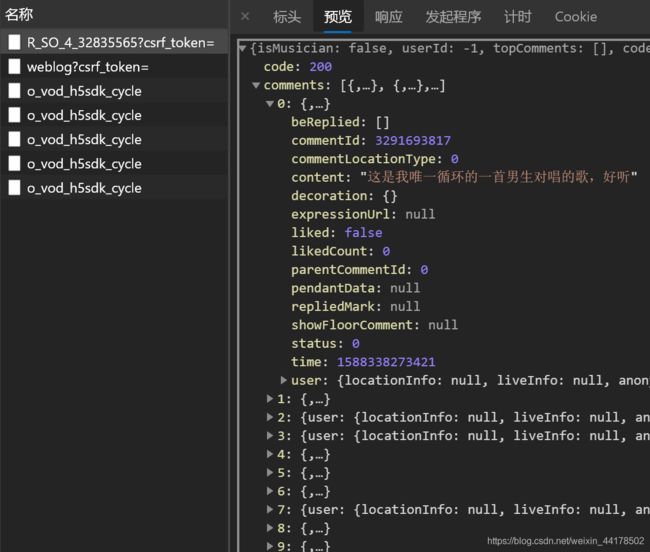
(这一部分应该就是服务器端接受XHR请求后的响应返回的数据内容了,那么咱浏览器发出去的XHR请求在哪呢?)
再看看旁边的【Headers/标头】:
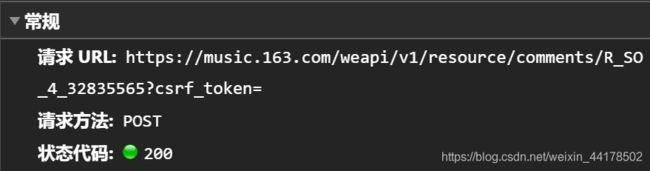
这里就可以看到url了~,以及了解到是通过向站点发起请求(POST)的方式来获取更多评论页内容的。 (可以进一步了解AJAX的两种请求方式,POST和GET)
滑动到底部,可以看到发起请求的表单内容
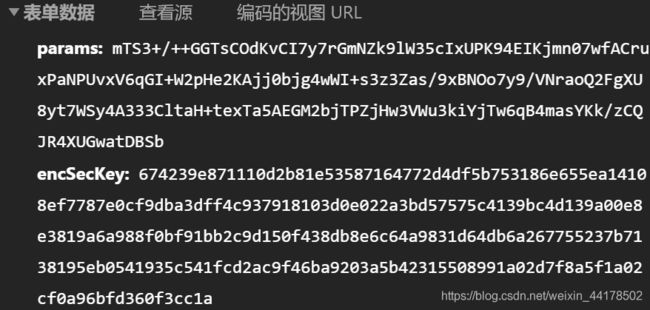
有了url、表头、发起表单内容(这些就是从浏览器发出去的XHR请求的内容啦!),我们就可以把表单内容、url参数从操作台一个个copy过来,用requests库的post请求方式,在py上模拟发起XHR请求,获得该页面的编码内容:
import requests
headers = {'User-Agent': 'Mozilla/5.0 '}
data={
'params':'OaDxOf2WTDG2Y4xxy6wlUKO4wcA/z5CQ5DHCqe/XhO7n4EcOKs+fGDxUiovZR6h6j/WIvgbc+ZuAzteClNdYUXrGKi9yJc85ovsdWskYJ8yd3BYj6fzIsc6GF21YZfqZr4j47iMmYODdxtNsxsF0VnCUKjCiike11nXc7s/pQMlhihxWxQAnouhgrRIPvxSL',
'encSecKey':'7cdd63c8f0bdc58da9faeae82598f7015313c24c13a6be8e94e10917da26c42ce0fe63d702babfa529939362e5ab3b56d5465178ae659d1a2b8df49e7d008199d25194e0c7095a7a78bfb0e71ba9a353d8a60a48ec346934c87be36e45bafff164746824806f758fc9fb0e8fdf17b933c57e5781cb3a95ff8aa3328f47db455b'
}
url='https://music.163.com/weapi/v1/resource/comments/R_SO_4_32835565?csrf_token='
html=requests.post(url,data=data,headers=headers)
html #看一下连接状态~
html.text #看看内容有没有想要的文本~扫一眼用python模拟向服务器发起请求后,返回得到的编码内容,有像昵称、是否会员、评论编号、评论内容等字段:

之后用之前的标签定位、编码解析(bs或lxml)方式其实可以就可以获得该页评论区的规整文本内容啦~
但是问题来了,我们可以明显发现这里的url压根莫得规律,咱怎么进行多页面内容爬取呢?
(无论是浏览器窗口栏的url,还是我们从浏览器控制台观察XHR请求里的url,都与不同评论 页码等信息没有字面上的规律!)
二、这时就要请Selenium出场啦~
Selenium是一种自动化方式,简单说我们可以通过它,用编码来控制浏览器实现像人一样一步步操作。
关于浏览器自动化的Selenium配置,第一步是根据浏览器版本下载相应驱动,下面是chrome浏览器自动化驱动的一个下载地址:
https://npm.taobao.org/mirrors/chromedriver/
第二步呢,就是下好驱动文件后要把它复制到chrome浏览器的安装路径下,并添加环境变量,再复制一份到python环境(如Anaconda的安装路径下,可以参考这位博主的说明:
https://blog.csdn.net/u012765157/article/details/84864924
然后就可以开始操作啦!
from selenium import webdriver #调用库
driver = webdriver.Chrome() #打开浏览器
url = 'https://music.163.com/#/song?id=32835565'
driver.get(url) #转到抓取页面
driver.switch_to.frame('contentFrame') #转到具体内容块在具体内容的筛选上,选择利用xpath规则确定;而因为正文内容为一个iframe标签所包含,尝试后发现xpath定位无法穿过iframe标签,故需要自动化切入该标签(相应的如果之后要定位iframe外的标签,要切回去哦~)。然后就是手写xpath语句定位内容:
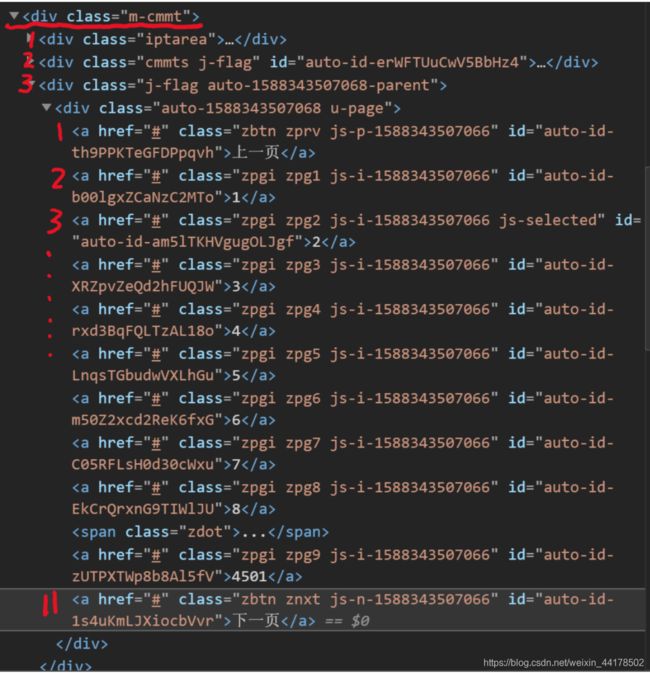
next_page = driver.find_element_by_xpath('//*[@class="m-cmmt"]/div[3]/div/a[11]') #定位下一页按钮
comments = driver.find_elements_by_xpath('//*[@class="m-cmmt"]/div[2]/div/div[2]/div[1]/div') #定位评论内容
#第一项的规则说明(结合上图看),选取内部某个属性为"m-cmmt"的标签,然后向内遍历其第三个div子标签,再继续向内遍历该div子标签的第11个a标签,第二项评论的定位同理不赘叙之后就是从定位的内容中提取文本、自动化执行翻页、打印的操作了,注意!翻页操作涉及到模拟执行js:
(先看一下执行js相关内容,下图来自博客https://blog.csdn.net/MDZeChan/article/details/72621823)
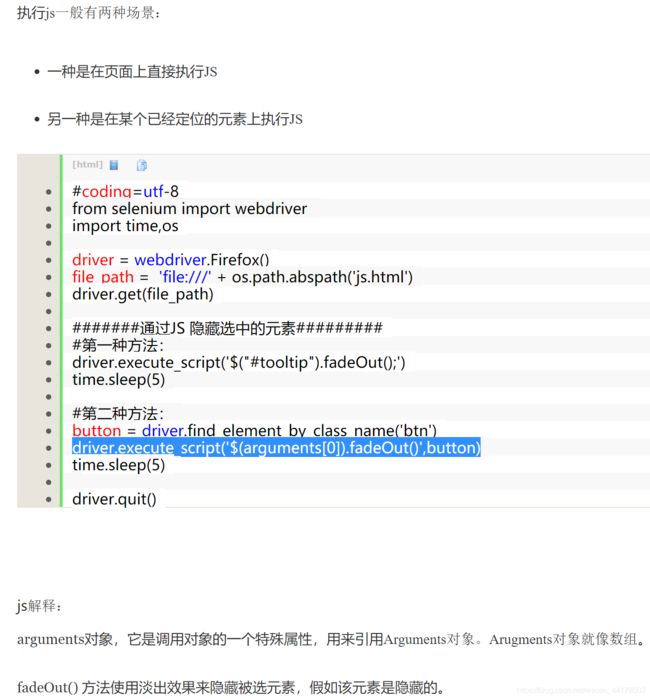
前面我们已经用xpath定好翻页空间的位置了(且咱暂时对js不是很熟悉),所以咱进行的就是第二种在已经定位的元素上执行js啦!
操作代码:driver.execute_script(传入参数.动作(),元素定位),意即自动化执行script(js命令一般放这标签里),这个的arguments[0]是传入首个参数的意思,也就是后面的元素定位。
(PS:在循环爬取时,开头咱都放了个time.sleep()的简单延时操作,这是因为评论部分是通过ajax动态加载的,不设置延时的话,在模拟翻页后马上xpath定位,新的评论会定不到!comments会为空,咱要等翻页后ajax加载完才行!这里的延时咱只是粗略先设置一下,专业的话,Selenium里面其实有“隐式等待”与“显示等待”的特别设置,之后我们再了解使用)
最后是Selenium模拟访问及执行js(翻页)方法下,爬虫的完整代码:
from selenium import webdriver
import time
driver = webdriver.Chrome()
url = 'https://music.163.com/#/song?id=32835565'#歌曲页面的URL地址
driver.get(url)
driver.switch_to.frame('contentFrame')
for i in range(3):
time.sleep(5) //不等待的话只能爬到第一页哦~
next_page = driver.find_element_by_xpath('//*[@class="m-cmmt"]/div[3]/div/a[11]')
comments = driver.find_elements_by_xpath('//*[@class="m-cmmt"]/div[2]/div/div[2]/div[1]/div')
for item in comments:
pinglun = item.text
print(pinglun)
driver.execute_script("arguments[0].click();", next_page)