基于TensorFlow的手写体数字识别
目录
一、MNIST数据集介绍
二、原理
2.1、卷积神经网络简介( convolutional neural network 简称CNN)
2.1.1卷积运算过程
2.1.2滑动的步长
2.1.3卷积的边界处理
2.1.4池化
2.1.5全连接
2.1.6卷积核相关:梯度下降
2.2LeNet-5模型的介绍
2.3手写数字识别算法模型的构建
2.3.1各层设计
2.3.2网络模型的总体结构
三、代码实现
3.1训练MNIST数据集图像
3.2封装成模型
四、结果分析
一、MNIST数据集介绍
MNIST是一个非常有名的手写体数字识别数据集。很多的深度学习都是采用
数据集下载地址:http://yann.lecun.com/exdb/mnist/
下载后用下面的代码导入到你的项目里面,也可以直接复制粘贴到你的代码文件里面。
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)下载下来的数据集被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不用于训练而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上(泛化)。
这个数据集由四部分组成,分别是:
也就是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集;我们可以看出这个其实并不是普通的文本文件或是图片文件,而是一个压缩文件,下载并解压出来,我们看到的是二进制文件,其中训练图片集的内容部分如此。
在MNIST图片集中,所有的图片都是28×28的,也就是每个图片都有28×28个像素;
下面是MNIST的一些数据:
0的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
1的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
2的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
3的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
4的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
5的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
6的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
7的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
8的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
9的数据集示例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
这些数字的数据集的形状大部分都不是很规范的数字形状,里面包含了每个数字尽可能可以写出的形状,数字0有时写出来的会像数字6;数字1有时会和7很像;数字5,3,8这三个数字有时会写得很像;数字4,9,6这三个数字有时也会写得很像;MNIST数据集里面数据的不规则性,数字间的相似性,给识别数字造成很大的干扰,会把某个数字识别成另一个数字,带来很大的挑战。
二、原理
2.1、卷积神经网络简介( convolutional neural network 简称CNN)
卷积神经网络是今年发展起来,并引起广泛重视的一种高效识别方法。
2.1.1卷积运算过程
上图中展示了一个3*3的卷积核在5*5的图像上做卷积的过程。每一个卷积都是特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分帅选出来。左侧绿色5*5矩阵是输入的图片的灰度值,黄色部分是用来提取特征值的卷积核(也可以叫作滤波器)卷积核在图片灰度矩阵上从左到右,从上到下滑动,每一次滑动两个矩阵对应位置的元素相乘然后求和就可以得到右边矩阵的一个元素。
在上图的左图中,卷积的运算方式是模拟人脑神经网络的运算方式。右下角是卷积的数学公式,基本原理是矩阵的对应元素相乘求和然后加上一个偏振值。
2.1.2滑动的步长
在上面的计算过程中,卷积核从左到右每次移动一格,也可以移动多个,每次移动的格数就是步长。
2.1.3卷积的边界处理
在上面的计算过程中,计算完成后得到的矩阵只有3*3,因为边界没有了,所以比原来的图片要小,卷积边界处理方式有两种:
第一种:丢掉边界。也就是后面的运算直接按照之前的出的结果来。
第二种:复制边界。也就是把源矩阵最外层数据原封不动的复制起来。
2.1.4池化
池化分为两种:
一种是最大池化,在选中区域中找到最大的值最为抽样后的值。另一种是平均值池化,把选中的区域中的平均值作为抽样后的值。这样做就是为了后面的全连接的时候减少连接数。
2.1.5全连接
左边是没有卷积的全连接,假设图片是1000*1000的,然后用1M的神经元去感知,最后需要10^12个权值作为参数。右边是经过卷积过的,每个圆点都是一个神经元,因此只是用一个卷积核的话,其实只要100*10^6,数量级就大大减少。而且因为提取的就是所需的特征,所以在加快训练速度的时候对结果并不产生过大的影响,甚至更为精确。
2.1.6卷积核相关:梯度下降
卷积核是被各种训练集训练出来的,利用梯度下降法可以使参数达到最优解。
梯度下降原理:把函数比作一座山,我们站在山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快。
2.2LeNet-5模型的介绍
本文实现手写数字识别,使用的是卷积神经网络,建模思想来自LeNet-5,如下图所示:
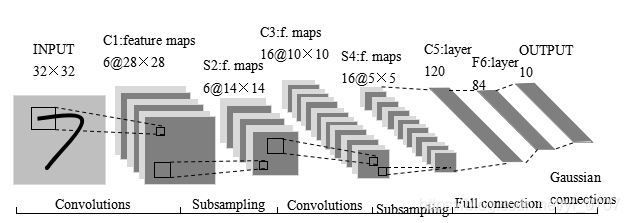
LeNet—5结构
这是原始的应用于手写数字识别的网络,我认为这也是最简单的深度网络。
LeNet-5不包括输入,一共7层,较低层由卷积层和最大池化层交替构成,更高层则是全连接和高斯连接。
LeNet-5的输入与BP神经网路的不一样。这里假设图像是黑白的,那么LeNet-5的输入是一个32*32的二维矩阵。同时,输入与下一层并不是全连接的,而是进行稀疏连接。本层每个神经元的输入来自于前一层神经元的局部区域(5×5),卷积核对原始图像卷积的结果加上相应的阈值,得出的结果再经过激活函数处理,输出即形成卷积层(C层)。卷积层中的每个特征映射都各自共享权重和阈值,这样能大大减少训练开销。降采样层(S层)为减少数据量同时保存有用信息,进行亚抽样。
第一个卷积层(C1层)由6个特征映射构成,每个特征映射是一个28×28的神经元阵列,其中每个神经元负责从5×5的区域通过卷积滤波器提取局部特征。一般情况下,滤波器数量越多,就会得出越多的特征映射,反映越多的原始图像的特征。本层训练参数共6×(5×5+1)=156个,每个像素点都是由上层5×5=25个像素点和1个阈值连接计算所得,共28×28×156=122304个连接。
S2层是对应上述6个特征映射的降采样层(pooling层)。pooling层的实现方法有两种,分别是max-pooling和mean-pooling,LeNet-5采用的是mean-pooling,即取n×n区域内像素的均值。C1通过2×2的窗口区域像素求均值再加上本层的阈值,然后经过激活函数的处理,得到S2层。pooling的实现,在保存图片信息的基础上,减少了权重参数,降低了计算成本,还能控制过拟合。本层学习参数共有1*6+6=12个,S2中的每个像素都与C1层中的2×2个像素和1个阈值相连,共6×(2×2+1)×14×14=5880个连接。
S2层和C3层的连接比较复杂。C3卷积层是由16个大小为10×10的特征映射组成的,当中的每个特征映射与S2层的若干个特征映射的局部感受野(大小为5×5)相连。其中,前6个特征映射与S2层连续3个特征映射相连,后面接着的6个映射与S2层的连续的4个特征映射相连,然后的3个特征映射与S2层不连续的4个特征映射相连,最后一个映射与S2层的所有特征映射相连。此处卷积核大小为5×5,所以学习参数共有6×(3×5×5+1)+9×(4×5×5+1)+1×(6×5×5+1)=1516个参数。而图像大小为28×28,因此共有151600个连接。
S4层是对C3层进行的降采样,与S2同理,学习参数有16×1+16=32个,同时共有16×(2×2+1)×5×5=2000个连接。
C5层是由120个大小为1×1的特征映射组成的卷积层,而且S4层与C5层是全连接的,因此学习参数总个数为120×(16×25+1)=48120个。
F6是与C5全连接的84个神经元,所以共有84×(120+1)=10164个学习参数。
卷积神经网络通过通过稀疏连接和共享权重和阈值,大大减少了计算的开销,同时,pooling的实现,一定程度上减少了过拟合问题的出现,非常适合用于图像的处理和识别。
2.3手写数字识别算法模型的构建
2.3.1各层设计
输入层设计:
输入28*28的矩阵而不是向量。
激活函数的选取:
Sigmoid函数具有光滑性、鲁棒性和其导数可用自身表示的优点,但其运算涉及指数运算,反向传播求误差梯度时,求导又涉及乘除运算,计算量相对较大。同时,针对本文构建的含有两层卷积层和降采样层,由于sgmoid函数自身的特性,在反向传播时,很容易出现梯度消失的情况,从而难以完成网络的训练。因此,本文设计的网络使用ReLU函数作为激活函数。
ReLU表达式:

卷积层设计:
本文设计卷积神经网络采取的是离散卷积,卷积步长为1,即水平和垂直方向每次运算完,移动一个像素。卷积核大小为5×5。
降采样层:
本文降采样层的pooling方式是max-pooling,大小为2×2。
输出层设计:
输出层设置为10个神经网络节点。数字0~9的目标向量如下表所示:
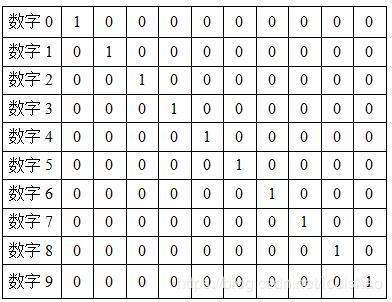
2.3.2网络模型的总体结构

其实,本文网络的构建,参考自TensorFlow的手写数字识别的官方教程的,读者有兴趣也可以详细阅读。
三、代码实现
本文使用Python,调用TensorFlow的api完成手写数字识别的算法。
3.1训练MNIST数据集图像
1、我们先要获取训练集和测试集:
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
sess = tf.InteractiveSession()
def getTrain():
train=[[],[]] # 指定训练集的格式,一维为输入数据,一维为其标签
# 读取所有训练图像,作为训练集
train_root="mnist_train"
labels = os.listdir(train_root)
for label in labels:
imgpaths = os.listdir(os.path.join(train_root,label))
for imgname in imgpaths:
img = cv2.imread(os.path.join(train_root,label,imgname),0)
array = np.array(img).flatten() # 将二维图像平铺为一维图像
array=MaxMinNormalization(array)
train[0].append(array)
label_ = [0,0,0,0,0,0,0,0,0,0]
label_[int(label)] = 1
train[1].append(label_)
train = shuff(train)
return train
def getTest():
test=[[],[]] # 指定训练集的格式,一维为输入数据,一维为其标签
# 读取所有训练图像,作为训练集
test_root="mnist_test"
labels = os.listdir(test_root)
for label in labels:
imgpaths = os.listdir(os.path.join(test_root,label))
for imgname in imgpaths:
img = cv2.imread(os.path.join(test_root,label,imgname),0)
array = np.array(img).flatten() # 将二维图像平铺为一维图像
array=MaxMinNormalization(array)
test[0].append(array)
label_ = [0,0,0,0,0,0,0,0,0,0]
label_[int(label)] = 1
test[1].append(label_)
test = shuff(test)
return test[0],test[1]
def shuff(data):
temp=[]
for i in range(len(data[0])):
temp.append([data[0][i],data[1][i]])
import random
random.shuffle(temp)
data=[[],[]]
for tt in temp:
data[0].append(tt[0])
data[1].append(tt[1])
return data
count = 0
def getBatchNum(batch_size,maxNum):
global count
if count ==0:
count=count+batch_size
return 0,min(batch_size,maxNum)
else:
temp = count
count=count+batch_size
if min(count,maxNum)==maxNum:
count=0
return getBatchNum(batch_size,maxNum)
return temp,min(count,maxNum)
def MaxMinNormalization(x):
x = (x - np.min(x)) / (np.max(x) - np.min(x))
return x
2、接下来,权重初始化,偏置初始化。为了创建这个模型,我们需要创建大量的权重和偏置项,为了不在建立模型的时候反复操作,定义两个函数用于初始化。
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)#正太分布的标准差设为0.1
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
3、卷积层和池化层也是接下来要重复使用的,因此也为它们定义创建函数
tf.nn.conv2d是Tensorflow中的二维卷积函数,参数x是输入,w是卷积的参数
strides代表卷积模块移动的步长,都是1代表会不遗漏地划过图片的每一个点,padding代表边界的处理方式
padding = 'SAME',表示padding后卷积的图与原图尺寸一致,激活函数relu()
tf.nn.max_pool是Tensorflow中的最大池化函数,这里使用2 * 2 的最大池化,即将2 * 2 的像素降为1 * 1的像素
最大池化会保留原像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体缩小图片尺寸
ksize:池化窗口的大小,取一个四维向量,一般是[1,height,width,1]
因为我们不想再batch和channel上做池化,一般也是[1,stride,stride,1]
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1,1,1,1],padding='SAME') # 保证输出和输入是同样大小
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1],padding='SAME')
iterNum = 500
batch_size=1024
print("load train dataset.")
train=getTrain()
print("load test dataset.")
test0,test1=getTest()4、参数
这里的x,y_并不是特定的值,它们只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值
输入图片x是一个2维的浮点数张量,这里分配给它的shape为[None, 784],784是一张展平的MNIST图片的维度
None 表示其值的大小不定,在这里作为第1个维度值,用以指代batch的大小,means x 的数量不定
输出类别y_也是一个2维张量,其中每一行为一个10维的one_hot向量,用于代表某一MNIST图片的类别
x = tf.placeholder(tf.float32, [None,784], name="x-input")
y_ = tf.placeholder(tf.float32,[None,10]) # 10列5、第一层卷积,它由一个卷积接一个max pooling完成
# 张量形状[5,5,1,32]代表卷积核尺寸为5 * 5,1个颜色通道,32个通道数目
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32]) # 每个输出通道都有一个对应的偏置量
# 我们把x变成一个4d 向量其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(灰度图的通道数为1,如果是RGB彩色图,则为3)
x_image = tf.reshape(x,[-1,28,28,1])
# 因为只有一个颜色通道,故最终尺寸为[-1,28,28,1],前面的-1代表样本数量不固定,最后的1代表颜色通道数量
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) # 使用conv2d函数进行卷积操作,非线性处理
h_pool1 = max_pool_2x2(h_conv1) # 对卷积的输出结果进行池化操作
6、第二个和第一个一样,是为了构建一个更深的网络,把几个类似的堆叠起来
第二层中,每个5 * 5 的卷积核会得到64个特征
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)# 输入的是第一层池化的结果
h_pool2 = max_pool_2x2(h_conv2)6、密集连接层
图片尺寸减小到7 * 7,加入一个有1024个神经元的全连接层,
把池化层输出的张量reshape(此函数可以重新调整矩阵的行、列、维数)成一些向量,加上偏置,然后对其使用Relu激活函数
w_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1,7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)8、使用dropout,防止过度拟合
dropout是在神经网络里面使用的方法,以此来防止过拟合
用一个placeholder来代表一个神经元的输出
tf.nn.dropout操作除了可以屏蔽神经元的输出外,
还会自动处理神经元输出值的scale,所以用dropout的时候可以不用考虑scale
keep_prob = tf.placeholder(tf.float32, name="keep_prob")# placeholder是占位符
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)9、输出层,最后添加一个softmax层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2, name="y-pred")
10、训练和评估模型
损失函数是目标类别和预测类别之间的交叉熵
参数keep_prob控制dropout比例,然后每100次迭代输出一次日志
cross_entropy = tf.reduce_sum(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 预测结果与真实值的一致性,这里产生的是一个bool型的向量
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 将bool型转换成float型,然后求平均值,即正确的比例
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化所有变量,在2017年3月2号以后,用 tf.global_variables_initializer()替代tf.initialize_all_variables()
sess.run(tf.initialize_all_variables())
# 保存最后一个模型
saver = tf.train.Saver(max_to_keep=1)
for i in range(iterNum):
for j in range(int(len(train[1])/batch_size)):
imagesNum=getBatchNum(batch_size,len(train[1]))
batch = [train[0][imagesNum[0]:imagesNum[1]],train[1][imagesNum[0]:imagesNum[1]]]
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
if i % 2 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1],keep_prob: 1.0})
print("Step %d ,training accuracy %g" % (i, train_accuracy))
print("test accuracy %f " % accuracy.eval(feed_dict={x: test0, y_:test1, keep_prob: 1.0}))
# 保存模型于文件夹
saver.save(sess,"save/model")3.2封装成模型
1、权重初始化,偏置初始化
为了创建这个模型,我们需要创建大量的权重和偏置项
为了不在建立模型的时候反复操作,定义两个函数用于初始化
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)#正太分布的标准差设为0.1
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)2、卷积层和池化层也是接下来要重复使用的,因此也为它们定义创建函数
tf.nn.conv2d是Tensorflow中的二维卷积函数,参数x是输入,w是卷积的参数
strides代表卷积模块移动的步长,都是1代表会不遗漏地划过图片的每一个点,padding代表边界的处理方式
padding = 'SAME',表示padding后卷积的图与原图尺寸一致,激活函数relu()
tf.nn.max_pool是Tensorflow中的最大池化函数,这里使用2 * 2 的最大池化,即将2 * 2 的像素降为1 * 1的像素
最大池化会保留原像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体缩小图片尺寸
ksize:池化窗口的大小,取一个四维向量,一般是[1,height,width,1]
因为我们不想再batch和channel上做池化,一般也是[1,stride,stride,1]
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1,1,1,1],padding='SAME') # 保证输出和输入是同样大小
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1],padding='SAME')
3、参数
这里的x,y_并不是特定的值,它们只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值
输入图片x是一个2维的浮点数张量,这里分配给它的shape为[None, 784],784是一张展平的MNIST图片的维度
None 表示其值的大小不定,在这里作为第1个维度值,用以指代batch的大小,means x 的数量不定
输出类别y_也是一个2维张量,其中每一行为一个10维的one_hot向量,用于代表某一MNIST图片的类别
x = tf.placeholder(tf.float32, [None,784], name="x-input")
y_ = tf.placeholder(tf.float32,[None,10]) # 10列
4、第一层卷积,它由一个卷积接一个max pooling完成
张量形状[5,5,1,32]代表卷积核尺寸为5 * 5,1个颜色通道,32个通道数目
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32]) # 每个输出通道都有一个对应的偏置量
# 我们把x变成一个4d 向量其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(灰度图的通道数为1,如果是RGB彩色图,则为3)
x_image = tf.reshape(x,[-1,28,28,1])
# 因为只有一个颜色通道,故最终尺寸为[-1,28,28,1],前面的-1代表样本数量不固定,最后的1代表颜色通道数量
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) # 使用conv2d函数进行卷积操作,非线性处理
h_pool1 = max_pool_2x2(h_conv1) # 对卷积的输出结果进行池化操作
5、第二个和第一个一样,是为了构建一个更深的网络,把几个类似的堆叠起来
第二层中,每个5 * 5 的卷积核会得到64个特征
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)# 输入的是第一层池化的结果
h_pool2 = max_pool_2x2(h_conv2)6、密集连接层
图片尺寸减小到7 * 7,加入一个有1024个神经元的全连接层,
把池化层输出的张量reshape(此函数可以重新调整矩阵的行、列、维数)成一些向量,加上偏置,然后对其使用Relu激活函数
w_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1,7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1) 7、使用dropout,防止过度拟合
dropout是在神经网络里面使用的方法,以此来防止过拟合
用一个placeholder来代表一个神经元的输出
tf.nn.dropout操作除了可以屏蔽神经元的输出外,
还会自动处理神经元输出值的scale,所以用dropout的时候可以不用考虑scale
keep_prob = tf.placeholder(tf.float32, name="keep_prob")# placeholder是占位符
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
8、输出层,最后添加一个softmax层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2, name="y-pred")
9、训练和评估模型
损失函数是目标类别和预测类别之间的交叉熵
参数keep_prob控制dropout比例,然后每100次迭代输出一次日志
cross_entropy = tf.reduce_sum(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 预测结果与真实值的一致性,这里产生的是一个bool型的向量
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 将bool型转换成float型,然后求平均值,即正确的比例
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化所有变量,在2017年3月2号以后,用 tf.global_variables_initializer()替代tf.initialize_all_variables()
sess.run(tf.initialize_all_variables())
# 保存最后一个模型
saver = tf.train.Saver(max_to_keep=1)
for i in range(1000):
batch = mnist.train.next_batch(64)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1],keep_prob: 1.0})
print("Step %d ,training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %f " % accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
# 保存模型于文件夹
saver.save(sess,"save/model")完整代码下载:https://download.csdn.net/download/yf_0707/11222368
四、结果分析
iterNum = 500 时


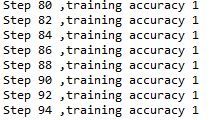
从图中可以看出在训练的过程中,准确率从刚开始80%多、99%到后面的100%,然后维持一段时间准确率都是100%。
但是训练到100多以后,准确率又开始降到80%多。

训练到136后准确率就开始降到85%,直至训练结束单次的准确率一直是85%。
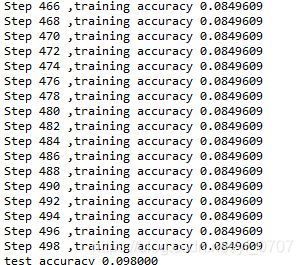
最终训练结束后,测试的准确率是98%。
为了更好的观察,我加了一个可视化窗口,

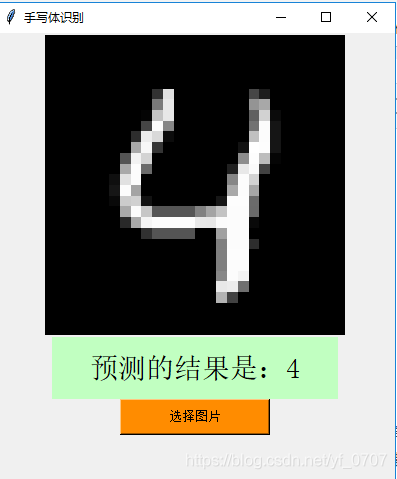

预测结果和所选图片匹配正确。
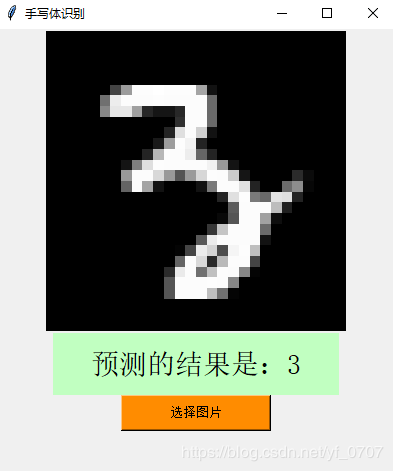

不同写法的数字的预测结果和所选的图片匹配还是非常正确的。

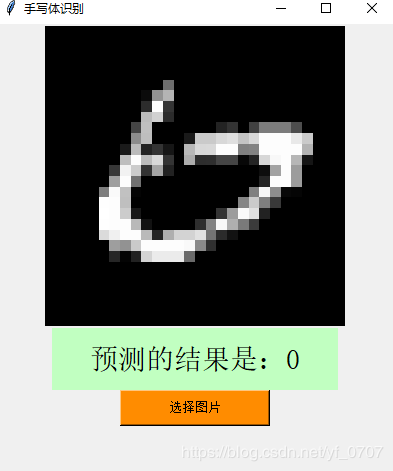
但也还会出现一些错误,上图所选的图片是4,预测结果是9,所选图片是6,预测结果是0,有些手写的数字写得和其他数字想象时,这个通常会把它和它想象的数字弄混。预测的结果虽然大部分都正确,但不排除有预测错误的情况。
本文实现的系统其实是基于卷积神经网络的手写数字识别系统。该系统能快速实现手写数字识别,成功识别率高。缺点:只能正确识别单个数字,图像预处理还不够,没有进行图像分割,读者也可以自行添加,进行完善。
ps:因为我们会用到TensorFlow,所以在这之前,我们需要安装好TensorFlow,而TensorFlow有GPU和CPU版本,个人建议下载GPU版,本人使用的是CPU版的,运行了十几个小时;超花时间;后来果断弃掉CPU版的安装GPU版。相较于CPU,GPU版的安装虽然要麻烦些,但运行速度要快很多,安装GPU版的TensorFlow,网上都有很多教程,直接按照教程一步一步往下走就可以了。
这是我安装GPU版TensorFlow所看的教程,供大家参考
https://blog.csdn.net/titansm/article/details/88755173