背景知识:
##############################################################
运算符重载:
在类中调用一个符号时,这个符号是有特定的函数名称的,我们可以在类中对此函数进行定义,那么在遇到这个符号调用时,python会自动调用这个方法。
比如,进行索引运算时,出现符号“[ ]”,就会自动调用 getitem方法,返回的就是index的平方。
class Indexer(object):
def __getitem__(self,index):
return index ** 2
X = Indexer()
X[2]
同样,setitem代表的运算操作,就是对item进行赋值操作。有点类似于字典,只要类中定义了这个方法,那么这个类对象就可以进行这个操作,通过重载的运算符实现。
##############################################################
一、二叉搜索树的应用
在二叉搜索树中,左子节点总是小于或等于根节点,而右子节点总是大于或等于根节点。我们可以平均在O(logn)的时间内根据数值在二叉搜索树中找到一个节点。
可见,二叉搜索树,就是搜索数据,根据key找到value。
我们之前已经学习过了两种ADT MAP的实现方式,一种是列表的二分查找,一种是散列表。
同样是搜索,根据键key来搜索值value。这里我们将要学习第三种方式:二叉搜索树。
注意,二叉搜索树也是一种数据结构。这种数据结构跟字典非常相似,所以也是三步走:
- 二叉搜索树的操作
- 二叉搜索树的结构
- 二叉搜索树的操作的代码实现
二、二叉搜索树的操作
- Map() 建立一个新的空map。
- put(key,val) 在map中增加了一个新的键值对。如果这个键已经在这个map中了, 那么就用新的数据来代替旧的数据。
- get(key) 提供一个键,返回map中保存的数据,否则返回None。
- del 用del map[key]这种形式从map中删除键值对。
- len() 返回map中保存的键值对的数目.
- in 对给定的键是否存在map中进行判断,如果所给的键在map中,返回True
三、二叉搜索树的结构
一个二叉搜索树,如果左子树中键值Key都小于父节点,而右子树中键值Key都大于父节点,我们将这种树称为BST搜索树。
四、二叉搜索树的实现
实现二叉搜索树,我们将使用节点和引用方法,这类似于一个我们用来实现链表和表达式树的过程。但是,因为我们必须能够创建和使用一个空二叉搜索树,所以我们的实现将使用两个类: 第一个类我们称为BinarySearchTree,第二个类我们称之为TreeNode。
这两个类的实现代码如下:
class BinarySearchTree:
def __init__(self):
self.root = None
self.size = 0
def length(self):
return self.size
def __len__(self):
return self.size
def __iter__(self):
return self.root.__iter__()
class TreeNode:
def __init__(self,key,val,left=None,right=None,
parent=None):
self.key = key
self.payload = val
self.leftChild = left
self.rightChild = right
self.parent = parent
def hasLeftChild(self):
return self.leftChild
def hasRightChild(self):
return self.rightChild
def isLeftChild(self):
return self.parent and self.parent.leftChild == self
def isRightChild(self):
return self.parent and self.parent.rightChild == self
def isRoot(self):
return not self.parent
def isLeaf(self):
return not (self.rightChild or self.leftChild)
def hasAnyChildren(self):
return self.rightChild or self.leftChild
def hasBothChildren(self):
return self.rightChild and self.leftChild
def replaceNodeData(self,key,value,lc,rc):
self.key = key
self.payload = value
self.leftChild = lc
self.rightChild = rc
if self.hasLeftChild():
self.leftChild.parent = self
if self.hasRightChild():
self.rightChild.parent = self
4.1、put()方法
对put方法的解读
- 如果根节点存在,则递归调用_put方法
- 如果根节点不存在,则直接调用treenode类,作为根节点。
由构造函数添加一个树节点,并且会输入此节点的key与val。
对_put方法的解释:
- 如果新的值小于当前节点,那就对左子树进行搜索
1、如果有左子树,那么再递归调用_put,直到新节点放到正确的位置为止。
2、如果没有左子树,则直接将点调用treenode,并且赋予key和val。 - 如果新的值大于当前节点,那么就对右子树进行搜索
下面执行与上述1、2相同的步骤
def put(self,key,val):
if self.root:
self._put(key,val,self.root)
else:
self.root = TreeNode(key,val)
self.size = self.size + 1
def _put(self,key,val,currentNode):
if key < currentNode.key:
if currentNode.hasLeftChild():
self._put(key,val,currentNode.leftChild)
else:
currentNode.leftChild = TreeNode(key,val,parent=currentNode)
else:
if currentNode.hasRightChild():
self._put(key,val,currentNode.rightChild)
else:
currentNode.rightChild = TreeNode(key,val,parent=currentNode)
用运算符重载的方法,使类对象可以进行类似于字典的赋值操作。
def __setitem__(self,k,v):
self.put(k,v)
随着put方法的定义,我们可以很容易地重载[ ]作为操作符,通过添加 setitem的方法来调用put方法。
定义这个方法以后,这使我们能够编写比如myZTiptree['plymouth’] = 55446一样的python语句,这看上去就像Python字典。
但是上面的put方法还是有一个bug。
bug是因为,若是出现重复的key,那么在_put中,key就不满足小于当前的key,而是else条件语句的大于等于当前节点,这样新的键值对就会被添加在当前节点的右子树上。这样在根据key查找数据是,永远只会找到最上面的key对应的value。因此正确的做法应该是有相同的key时,应该去覆盖这个key对应的value。
4.2 、get()方法
树已经被构建成功。接下来任务是给定键,实现对值的检索。(二叉搜索树的意义)
get方法比put更容易,因为它递归地搜索子树,直到发现无匹配的叶节点或找到一个匹配的键。当一个匹配的键被发现后,存储在节点的值被返回。
get方法
- 若根节点为空,则返回None,不为空,则递归调用_get进行查找操作。若找到key,则返回val。
_get方法
递归调用自身,若找到了key键,就返回对应的val,找不到就返回None。
def get(self,key):
if self.root:
res = self._get(key,self.root)
if res:
return res.payload
else:
return None
else:
return None
def _get(self,key,currentNode):
if not currentNode:
return None
elif currentNode.key == key:
return currentNode
elif key < currentNode.key:
return self._get(key,currentNode.leftChild)
else:
return self._get(key,currentNode.rightChild)
def __getitem__(self,key):
return self.get(key)
通过实施getitem方法,我们可以写若干Python语句,使它们看起来就像我们访问字典一样,而事实上我们只是在用一个二叉搜索树,例如Z = myziptree [ 'fargo’]。如你可以看到,所有的getitem方法都是调用get。
调用get函数时,我们可以为BinarySearchTree写contains方法从而能够使用操作符in。contains会简单的调用get,当get返回值的时候就返回True,如果get返回None就返回False。
def __contains__(self,key):
if self._get(key,self.root):
return True
else:
return False
4.3 、删除节点
删除节点的步骤:
- 1、找到要删除的搜索树的节点。
a、如果树有一个以上的节点,我们使用_get方法搜索找到需要删除的TreeNode;
b、如果树只有一个节点,这意味着我们要移除树的根,但是我们仍然必须检查以确保根的键是否匹配要删除的键。 - 2、在以上两种情况下,如果未发现键值,del操作符就会报错。
以下是删除节点的主函数的代码:
def delete(self,key):
if self.size > 1:
nodeToRemove = self._get(key,self.root)
if nodeToRemove:
self.remove(nodeToRemove)
self.size = self.size-1
else:
raise KeyError('Error, key not in tree')
elif self.size == 1 and self.root.key == key:
self.root = None
self.size = self.size - 1
else:
raise KeyError('Error, key not in tree')
def __delitem__(self,key):
self.delete(key)
而对于其中的nodeToRemove函数的具体操作,因为要删除的节点有三种不同的情况,因此对应的操作也不尽相同。
下面是,要删除的节点要有的三种情况:
- 1、要删除的节点没有子树
- 2、要删除的节点只有左子树(或只有右子树)
- 3、要删除的节点,左子树和右子树都有。
接下来对于三种情况再做具体的分析:
第一种情况:要删除的节点没有子树
第一种情况是简单的。如果当前节点没有子树,所有我们需要做的是删除该节点并把指向该节点的引用移动给其父节点。
if currentNode.isLeaf():
if currentNode == currentNode.parent.leftChild:
currentNode.parent.leftChild = None
else:
currentNode.parent.rightChild = None
例子:
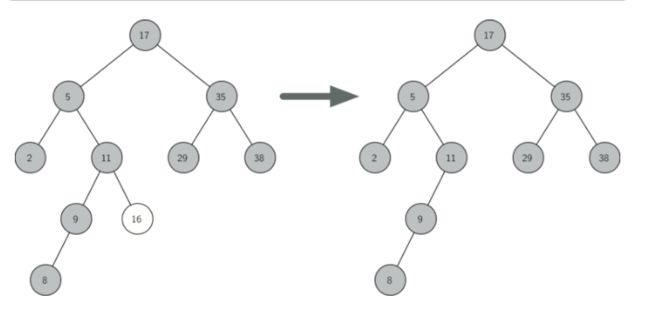
二叉搜索树是通过引用来实现的,所以删除一个节点,不能只是单纯的删除数据就行了,还要对引用做出修改。
代码解释,若当前节是叶节点,如果是父节点的左子节点,那么就把父节点的左子节点引用改为None。同理于右子节点。
第二种情况:要删除的节点只有左子树(或只有右子树)

else: # this node has one child
if currentNode.hasLeftChild():
if currentNode.isLeftChild():
currentNode.leftChild.parent = currentNode.parent
currentNode.parent.leftChild = currentNode.leftChild
elif currentNode.isRightChild():
currentNode.leftChild.parent = currentNode.parent
currentNode.parent.rightChild = currentNode.leftChild
else:
currentNode.replaceNodeData(currentNode.leftChild.key,
currentNode.leftChild.payload,
currentNode.leftChild.leftChild,
currentNode.leftChild.rightChild)
else:
if currentNode.isLeftChild():
currentNode.rightChild.parent = currentNode.parent
currentNode.parent.leftChild = currentNode.rightChild
elif currentNode.isRightChild():
currentNode.rightChild.parent = currentNode.parent
currentNode.parent.rightChild = currentNode.rightChild
else:
currentNode.replaceNodeData(currentNode.rightChild.key,
currentNode.rightChild.payload,
currentNode.rightChild.leftChild,
currentNode.rightChild.rightChild)
例子(当前节点是右节点,并且只有右子树的情况下):
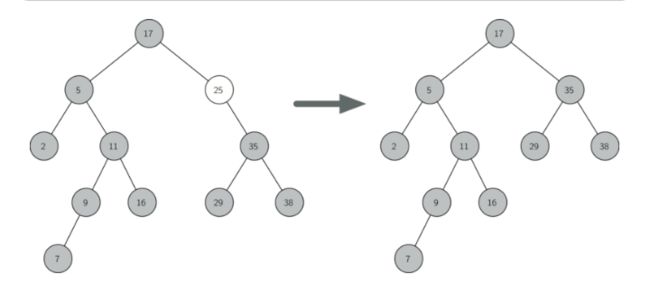
第三种情况:要删除的节点有左、右两个节点
如果一个节点有两个子节点,我们不可能简单地其中一个作为提升至父节点的位置,这就需要寻找一个节点,用来代替一个计划删除的节点,我们需要的这个节点,需要保存现有的左、右子树以及二叉搜索树关系。我们称这个节点为继任者。
如何找到这个继任者呢?
按照上面所说,有一个原则:需要保存现有的左、右子树以及二叉搜索树关系。
那么怎样能保证上述原则呢?
我们要找到,与当前节点相比,key值只是稍微大一点点的节点。再具体些,就是,比如一共有10个key,当前节点的key第5大,那么删除掉第5大的节点以后,只有用第4大的节点代替当前节点,才能保证二叉搜索树的各节点关系不变。
比如例子中的5:
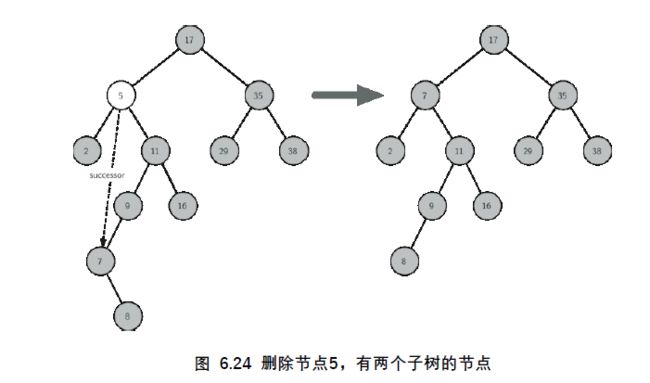
上面说的有些笼统,具体的怎么去确定这个继任者呢?
有三种情况需要考虑:
-
- 如果节点有右子节点,那么继任者是在右子树中最小的键。
-
- 如果节点没有右子节点,是其父节点的左子节点,那么父节点是继任者。
-
- 如果节点是其父节点的右子节点,而本身无右子节点,那么该节点的继任者是其父节点的继任者,不包括这个节点。
其中比较常用的是第三种情况中的第一种情况。
删除第三种情况的节点(有两个子节点)的代码分为两步:
- 1、找到继任者(findSuccessor和findMin)
- 2、根据找到点以后,确认继任者的几种情况(继任者节点是否具有子节点,有几个子节点等)再进行相应的操作。spliceOut
elif currentNode.hasBothChildren(): #interior
succ = currentNode.findSuccessor()
succ.spliceOut()
currentNode.key = succ.key
currentNode.payload = succ.payload
上述代码中用到的方法的代码:
def findSuccessor(self):
succ = None
if self.hasRightChild():
succ = self.rightChild.findMin()
else:
if self.parent:
if self.isLeftChild():
succ = self.parent
else:
self.parent.rightChild = None
succ = self.parent.findSuccessor()
self.parent.rightChild = self
return succ
def findMin(self):
current = self
while current.hasLeftChild():
current = current.leftChild
return current
def spliceOut(self):
if self.isLeaf():
if self.isLeftChild():
self.parent.leftChild = None
else:
self.parent.rightChild = None
elif self.hasAnyChildren():
if self.hasLeftChild():
if self.isLeftChild():
self.parent.leftChild = self.leftChild
else:
self.parent.rightChild = self.leftChild
self.leftChild.parent = self.parent
else:
if self.isLeftChild():
self.parent.leftChild = self.rightChild
else:
self.parent.rightChild = self.rightChild
self.rightChild.parent = self.parent
4.4 、iter:按顺序简单地遍历树上所有的键值。
最后的一个接口方法,就是按顺序简单的遍历书上所有的键值。
这是我们用字典所做能的事,为什么不在树也实现呢?我们已经知道如何使用中序遍历二叉树,然而,写一个迭代器需要更多一点的工作,因为每次调用迭代器时,一个迭代器只返回一个节点。
Python提供了一个非常强大的函数yield,使用时创建一个迭代器。yield和return相似,它也返回一个值给调用者。yield也有额外的步骤来记住函数运行目前的状态,以便下次调用函数时,继续从当前状态执行。创建可迭代对象的函数被成为生成器。
二叉树的中序迭代器代码如下所示。仔细看看这个代码:乍一看,你可能会认为代码是非递归的。但是请记住,iter重写for x in的操作符来实现迭代,所以它确实是递归!因为它是对TreeNode进行递归,iter_在TreeNode类中定义。
def __iter__(self):
if self:
if self.hasLeftChild():
for elem in self.leftChiLd:
yield elem
yield self.key
if self.hasRightChild():
for elem in self.rightChild:
yield elem
至此,基本的二叉搜索树的结构与性质已经实现了。