前言
继续昨天的话题,使用Python实现机器学习算法对安卓APP进行检测。准备工作已经差不多了,那么这篇文章就来详细记录如何将机器学习算法应用到安卓恶意软件检测上以及如何实现常见机器学习算法。
准备工作
- Anaconda:Anaconda下载
- Anaconda是一款Python科学计算的环境包,包含了众多的科学计算库和原生Python环境。这里我使用的是Python2的64位的Windows版。将安装包下载后,仅需要进行安装即可。相应的包和库都会自动集成,很方便。
- 利用上一篇文章对恶意软件和正常软件进行处理后生成的包含权限信息的txt文件各500条。
- 这里正常软件样本采用之前文章中介绍的爬虫下载即可,恶意软件为了安全起见不提供下载方式,但在文章最后提供处理过后的txt实验数据。需要注意的是正常的样本收集过后要经过几次查杀筛选,排除潜藏在正常软件中的恶意软件。
下载Anaconda.png
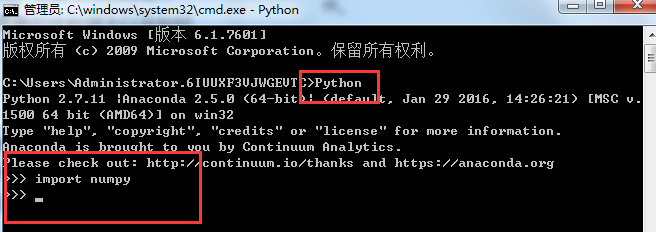
- 验证环境:首先确保将安装后的Anaconda中的python加入到环境变量中。接着cmd下调用Python并执行
import numpy,如下图没有报错即可:
验证环境.png
基本思路
- 首先我们这次试用朴素贝叶斯作为分类核心算法。
- 采取先训练分类器,再使用分类器对位置样本进行分类。
朴素贝叶斯
朴素贝叶斯是机器学习中最常见不过的一种算法,它简单实用且在数据量较少的情况下依然有着出色的表现。这里不再赘诉朴素贝叶斯的原理,提供几个链接供参考。
- 条件概率:条件概率学习
- 朴素贝叶斯:朴素贝叶斯原理
实现算法
话不多说,接下来开始用Python实现朴素贝叶斯算法。
- 我们使用权限(permission)作为特征,所以首先构建一个包含所有权限项的无重复列表。如:【权限1,权限2,……,权限n】
- 这里我是用了一个简单直接的方法,读遍所有的txt文件中的每个项,只要有之前不存在的项就追加到list中。其实可以去安卓官网查看安卓开发者可以申请到的全部权限,直接构建出list。
构建list.png
- 接着需要将每个txt文件处理成向量的形式。举个例子,如果样本1对应的权限项为【权限1,权限3,权限5,权限7】,则他的对应向量就是【1,0,1,0,1,0,1,0,0,0】——》假设全部权限的list长度为10项。
处理每条txt.png
- 接着就是训练函数,其基本思想总结为如下伪代码:
计算每个类别中文档数目
对于每个txt文档:
对于每个类别:
如果权限项出现在文档中则增加该词条计数值
增加所有权限项计数值
对于每个类别:
将该权限项数目除以总数得到条件概率
返回条件概率```
举个例子,首先初始化一个全为0的list,长度等于所有不重复权限项的数量和(假设为5)。【0,0,0,0,0】,接着针对正常的样本,逐条输入。假设第一条样本为【1,1,0,0,1,】,第二条样本为【1,1,1,1,1】,第三条为【0,0,0,0,0】则经过两次输入,我们的list变成【2,2,1,1,2】,除以总数3得到P=【0.67 ,0.67 ,0.33 ,0.33 ,0.67】。那么根据朴素贝叶斯算法,认为每个权限项都是独立的,则假设待测样本为【1,0,0,1,0】,那么他属于正常样本的概率为P=1*0.67*1*0.33=0.2211
* 上面的例子针对正常样本和恶意样本都要做。分类算法较简单,只需要计算出P正常和P恶意,然后比较哪个概率大。我们就将待测样本分类到概率大的一类中。
* 测试指标:我们使用检测率,就是分类正确的概率。在500条正常样本和500条恶意样本中,随机选出400个正常样本和400个恶意样本作为训练集,训练出分类器。然后用剩下的200个样本作为未知待测样本,对其进行检测。输出分类错误的情况以及准确率。
#实现中注意事项
1. 由于要计算多个概率的乘积以获得待测样本属于某个类别的概率,一旦其中一个概率为0,则最后的结果必然为0.为了降低这种影响,可以将所有权限项出现的次数初始化为1,分母初始化为2.
2. 计算很多比较小的数相乘,很容易造成下溢出,影响检测的结果。所以我们利用对乘积取熙然对数的方式:ln(a * b) = ln(a) + ln(b),这样不会有任何损失。
# 执行结果截图
* 这里执行10次取平均值,可以看到效果还是很不错的,大概准确率有9成。并且误报当中大部分是把好的APP判断成了恶意的。

#完整代码
```code
__author__ = 'Captainxero'
from numpy import *
import numpy as np
global p1
global p0
global numBad2Good
global numGood2Bad
global rateBad2Good
global rateGood2Bad
global Accuracy_Rate
Accuracy_Rate = 0
numBad2Good = 0
numGood2Bad = 0
def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
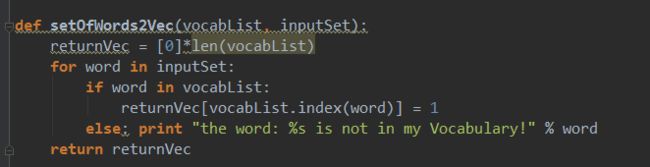
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print "the word: %s is not in my Vocabulary!" % word
return returnVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords); p1Num = ones(numWords) #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Denom) #change to log()
p0Vect = np.log(p0Num/p0Denom) #change to log()
return p0Vect, p1Vect, pAbusive
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
global p1
global p0
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
def textParse(bigString): #input is big string, #output is word list5
import re
listOfTokens = re.split(r'\W*', bigString)
# return [tok.lower() for tok in listOfTokens if len(tok) > 2]
return [tok for tok in listOfTokens if len(tok) > 2]
def spamTest():
global numBad2Good
global numGood2Bad
global Accuracy_Rate
docList=[]; classList = []; fullText =[]
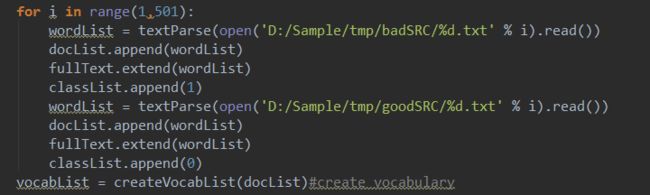
for i in range(1,501):
wordList = textParse(open('D:/Sample/tmp/badSRC/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('D:/Sample/tmp/goodSRC/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#create vocabulary
trainingSet = range(500); testSet=[] #create test set
for i in range(100):#random for testSet
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[]; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0; GoodToBad = 0;BadToGood = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
# if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
if classifyNB(array(wordVector),p0V,p1V,pSpam) != 1:
GoodToBad += 1
numGood2Bad += 1
# print 'GoodToBad:', docList[docIndex]
# print 'GoodToBad: NO.',docIndex
# print 'P-Good:', p0
# print 'P-Bad :', p1
# print 'Miss :', p0-p1
# print ''
else:
BadToGood += 1
numBad2Good += 1
# print 'BadToGood', docList[docIndex]
# print 'P-Good:', p0
# print 'P-Bad: ', p1
# print 'Miss :', p0-p1
# print 'BadToGood: NO.',docIndex
# print ''
errorCount += 1
# print "classification error",docList[docIndex]
# print 'the error rate is: ',float(errorCount)/len(testSet)
Accuracy_Rate = Accuracy_Rate+((1-float(errorCount)/len(testSet))*100)
print 'Accuracy Rate:%d%% '%((1-float(errorCount)/len(testSet))*100)
# print 'GoodToBad:', GoodToBad
# print 'BadToGood:', BadToGood
#return vocabList,fullText
if __name__ == "__main__":
for i in range(0,10):
spamTest()
print 'Accuracy_Rate',(Accuracy_Rate/10)
print 'BadToGood: ', (numBad2Good/10)
print 'GoodToBad: ', (numGood2Bad/10)
总结
- 对于手机恶意软件的检测,90%左右的概率离具体实用还差很多。这篇文章主要就是记录与分享下学习中经历。
- 写的时候侧重了实现,更多的是给出了代码。有兴趣的朋友不妨亲自体验,至于恶意软件没有这个问题,在这里附上我除了过得样本数据。
实验数据下载 - 推荐一本书《机器学习实战》Petet Harrington著,我的代码是学习了这本书后改进利用到安卓APP检测的。
- 系列文章到此还没结束,后面还会结合朴素贝叶斯和其他机器学习算法,提高检测精确度。
- 实在是表达能力不行,讲得不清楚见谅。还是那句话,有兴趣的话不妨实际运行下程序,再结合朴素贝叶斯算法就能理解了。