linux环境下ES5.6集群安装心得
记录安装es5.6注意事项和遇到的问题。
1.安装准备
需要准备es5.6安装包,node包,grunt-cli包,head包(或者head chrome插件需要和es大版本对应),es5.6 和1.4不同es5.6head是分离出来的 1.1. ES5.6需要JDK1.8版本,这里安装省略。
java -version 查看jdk安装情况
1.2. 关闭防火墙和selinux (linux6.X和linux7.X命令不同) ,我这边的环境是Linux7.3 (linux6.X 命令 service iptables status(stop))
--查看防火墙状态
systemctl status firewalld.service
--永久关闭防火墙
systemctl disable firewalld.service (开启 enable)
--查看selinux是否关闭
getenforce
--显示permissive即为开启状态 Enforcing 为关闭状态
--临时关闭selinux
setenforce 1 --对应Enforcing 开启状态
setenforce 0 --对应permissive 关闭状态
--永久关闭 需要重启服务器
vi /etc/selinux/config/
selinux=disable
2.检查并设置系统环境
a、检查系统版本
## 支撑系统版本信息:https://www.elastic.co/cn/subscriptions#request-info
> uname -a
b、检查并设置文件数设置
> vi/etc/security/limits.conf
添加:
* soft nofile65536
* hard nofile 131072
* soft nproc 65536
* hard nproc 65536
c、调整用户打开最大进程数
> vi/etc/security/limits.d/90-nproc.conf
* soft nproc 1024 改为 * soft nproc 2048
d、修改单个进程最大线程数据
> vi /etc/sysctl.conf
添加:
vm.max_map_count=655360
保存之后执行:
> sysctl –p
e、配置etc/hosts文件
将集群中的所有节点名称和IP加到hosts文件(修改集群所有机器)。 /etc/hosts/
示例:
192.168.86.1 jq01
192.168.86.2 jq02
192.168.86.3 jq03
3.安装ES (我配置的是1台master 4台node)
1.es启动不可使用root用户,必须要为es新建用户启动。
useradd elasticsearch -g elasticsearch -p elasticsearch
2.解压软件包
tar -zxvf elasticsearch-5.6.3.tar.gz
3.修改解压的目录所属用户和组
chown -R elasticsearch:elasticsearch elasticsearch-5.6.3
4.修改elasticsearch配置文件 (配置文件后冒号后必须加空格)
4.1 master elasticsearch.yml配置信息
vi /es目录/config/elasticsearch.yml
cluster.name: my-application ## 集群名称 根据自身需求填写
node.name: node1 ## 节点名称
#node.attr.rack: r1 ## 机架名称
node.master: true ## master节点(为node节点时需要改为false)
node.data: true ## 数据节点(为master节点时需要改为true)
http.port: 9200 ## 当一个服务器需要搭建多个实例时,需要修改其端口
path.data: /path/to/data ## 数据地址 建议不要放在es地址相同 当你没有备份,不小心删除ES安装目录,所有数据都被删除
path.logs: /path/to/logs ## 日志地址
bootstrap.memory_lock: false ## 锁定内存
bootstrap.system_call_filter: false #防止报错 bootstrap checks failed
network.host: 192.168.0.1 ## 绑定本机名称 机器名称
discovery.zen.ping.unicast.hosts: ["192.168.0.1"] ## master的地址,多实例的情况下,需要配置端口
discovery.zen.minimum_master_nodes: 1 ## 最少的master数量
gateway.recover_after_nodes: 3 ## 多少个节点启动之后,数据开始恢复。通常配置节点的node总数的一半以上
indices.fielddata.cache.size: 20% #防止es集群使用时间过久导致缓存过高影响es查询,之前的集群es1.4出现过该问题,已经解决,es5.6版本未验证,可不加该参数 如果是node 该配置建议为40%
http.cors.enabled: true
http.cors.allow-origin: “*”
node.max_local_storage_nodes:1 ## 当单机需要配置多实例时,将数据修改为需要配置的实例数值
修改内存参数配置文件
vi /es安装目录/config/jvm.options
-Xms1g ### 当服务器内存》64G时,修改成服务器32G,否则修改成服务器的一半内存。
-Xmx1g ### 和-Xms1g设置成一样。
free -g (查看内存情况,我的服务器是128g配置信息如下)
-Xms32g
-Xmx32g
4.1 node elasticsearch.yml配置信息
vi /es目录/config/elasticsearch.yml
cluster.name: my-application ## 集群名称 根据自身需求填写
node.name: node2 ## 节点名称
#node.attr.rack: r1 ## 机架名称
node.master: false ## master节点(为node节点时需要改为false)
node.data: true ## 数据节点(为master节点时需要改为true)
http.port: 9200 ## 当一个服务器需要搭建多个实例时,需要修改其端口
path.data: /path/to/data ## 数据地址 建议不要放在es地址相同 当你没有备份,不小心删除ES安装目录,所有数据都被删除
path.logs: /path/to/logs ## 日志地址
bootstrap.memory_lock: false ## 锁定内存
bootstrap.system_call_filter: false #防止报错 bootstrap checks failed
network.host: 192.168.0.2 ## 绑定本机名称 机器名称
discovery.zen.ping.unicast.hosts: ["192.168.0.1"] ## master的地址,多实例的情况下,需要配置端口
discovery.zen.minimum_master_nodes: 1 ## 最少的master数量
gateway.recover_after_nodes: 3 ## 多少个节点启动之后,数据开始恢复。通常配置节点的node总数的一半以上
indices.fielddata.cache.size: 20% #防止es集群使用时间过久导致缓存过高影响es查询,之前的集群es1.4出现过该问题,已经解决,es5.6版本未验证,可不加该参数 如果是node 该配置建议为40%
http.cors.enabled: true
http.cors.allow-origin: “*”
node.max_local_storage_nodes:1 ## 当单机需要配置多实例时,将数据修改为需要配置的实例数值
5.安装ik分词器(提供分词查询,所有机器必须安装)
unzip elasticsearch-analysis-ik-5.6.3-releases.zip -d/home/elasticsearch/pulgins
## 解压路径是es的安装路径下的pulgins
6.启动es实例
./bin/elasticsearch/ -d
查看logs日志 确认启动无问题
常见问题处理(转载,基本上常见问题在准备环境中已经做了处理):
https://blog.csdn.net/liangzhao_jay/article/details/56840941
浏览器检查验证 ip:9200 当你看到:说明安装成功
{
"name":"node1",
"cluster_name":"ES_CLUSTER"
.....
.....
}
7.安装head chrome浏览器插件或者安装head插件
此插件需要安装才可以访问head管理界面。
谷歌浏览器--添加扩展程序--将解压后的crx插件拖动到chrome中--安装head chrome插件
右上角es search 在小窗口栏输入es master地址点击连接
安装head插件
1、安装node包(仅master机器)
tar -xvf node-v0.10.26.tar.gz
cd node-v0.10.26
make &&makeinstall (编译安装需要一些时间)
node –v
2、安装grunt包(仅master机器)
unzip grunt-cli.zip
cd /data/grunt-cli/node_modules/grunt-cli/bin/
chmod 777 grunt
cp bin/* /usr/local/bin/
cp lib/* /usr/local/lib
cd /data/grunt-cli
cp grunt /usr/local/bin
cp -r node_modules/ /usr/local/bin
3、安装head包(仅master机器)
unzip elasticsearch-head-master.zip
cd elasticsearch-head-master
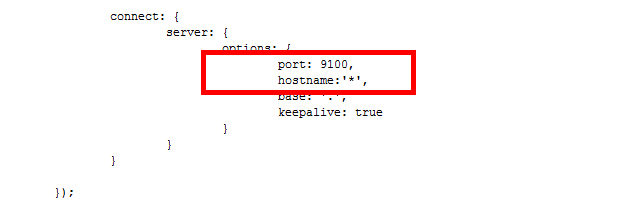
vi Gruntfile.js
(修改端口,新增一行hostname:’*’(存在不用新增))
cd _site
vi app.js (修改为es master地址)

运行命令(按照实际安装目录运行,我安装在data目录下)
cd /data/elasticsearch-head-master
grunt server &
验证:
ip:9100 至此安装成功:
验证ik分词器使用: 在node或者master启动时能看到 日志:
[node] loaded plugin [analysis-ik]
es集群中验证: 新增索引(iktest) 符合查询
http://ip:9200/iktest
_analyze post
{
"analyzer":"ik_max_word",
"text":"我们是好朋友"
}
提交请求:
可以查到多个组合分词
附:
1.ik分词器 主要用来做分词,例如 es数据中有一条"我们是好朋友"的数据,如果没有安装分词,输入"我们"将无法查到该数据
2.chrome head 浏览器插件和安装head插件到服务器的功能是一样的,相比较来说安装浏览器插件访问会简单一些,但是其他人访问需要安装浏览器插件,安装head插件到服务器就不会存在这个问题
3.建议安装kibana插件方便管理,还有x-pack插件可以随时观察集群的性能,IO/cpu等等情况,es2.X以前可以使用bigdesk和kopf插件来管理,目前了解到的bigdesk和kopf已经对es5.X不支持。但是x-pack插件有1个月的试用期,需要反编译jar包。
4.安装node,grunt,head需要安装gcc等编译包,需要配置相关的yum源
5.启动es时注意观察es的日志,大部分的启动异常可以通过日志查看到
本文属于原创,转载请注明出处。