2020-08-18 跟着重新学习泰坦尼克号 数据加载
虽然之前已经做过这套题了,不过很久没碰了
现在再按照datawhale的计划重新学习一下吧
如下是第一、二天的任务
第一章(PART 1):数据加载
1.1 载入数据
1.1.1 任务一:导入numpy和pandas
1.1.2 任务二:载入数据
用相对路径、绝对路径载入数据
#相对路径:
df = pd.read_csv('train.csv')
#绝对路径
df = pd.read_csv('/Users/xxx/Documents/train.csv')
提示:相对路径载入报错时,尝试使用os.getcwd()查看当前工作目录。os.getcwd()作用就是获取当前路径
思考:知道数据加载的方法后,试试pd.read_csv()和pd.read_table()的不同
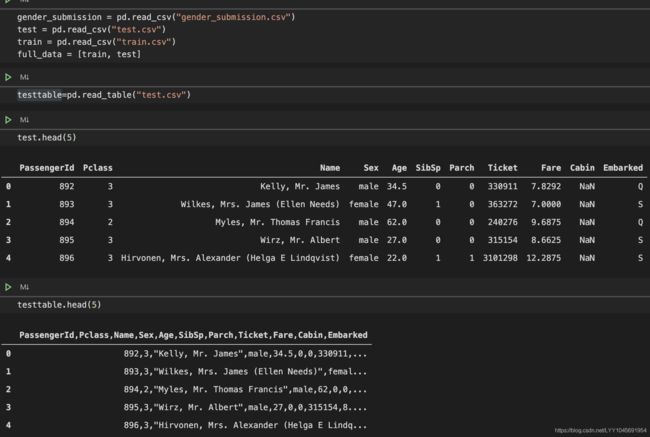
如果想让他们效果一样,需要怎么做?
我的办法是修改delimiter
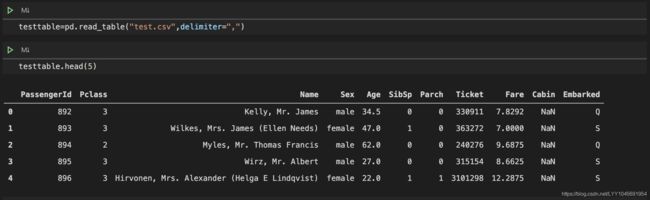
read_csv和read_table差异和相同之处:
相同之处:
都是是加载带分隔符的数据,每一个分隔符作为一个数据的标志
差异:
读出来的数据格式还是不一样的:
read_table是以制表符 \t 作为数据的标志,也就是以行为单位进行存储。
read_csv是以分隔符号逗号作为数据的标志。
参考:https://blog.csdn.net/qq_43243022/article/details/82978898
了解一下’.tsv’和’.csv’的不同,如何加载这两个数据集?
delimiter参数值默认为半角逗号,即默认将被处理文件视为CSV。
当delimiter=’\t’时,被处理文件就是TSV。
参考:https://blog.csdn.net/wf592523813/article/details/89165015
总结:加载的数据是所有工作的第一步,我们的工作会接触到不同的数据格式(eg:.csv;.tsv;.xlsx),但是加载的方 法和思路都是一样的,在以后工作和做项目的过程中,遇到之前没有碰到的问题,要多多查资料吗,使用google,了解业务逻辑,明白输入和输出是什么。
1.1.3 任务三:每1000行为一个数据模块,逐块读取
思考:什么是逐块读取?为什么要逐块读取呢?
更快读文件,看看文件长什么样子。
尽量避免直接对过大的dataframe直接操作(当然有时候没有办法,必须对整体的dataframe进行操作,这时就需要从其他方面优化,比如尽量较少不必要的列,以降低内存消耗),以从csv文件读取数据为例,可以通过read_csv方法的chunksize参数,设定读取的行数,返回一个固定行数的迭代器,每次读取只消耗相应行数对应的dataframe的内存,从而可以有效的解决内存消耗过多的问题,参考如下demo。
参考:https://blog.csdn.net/S_o_l_o_n/article/details/99761021
1.1.4 任务四:将表头改成中文,索引改为乘客ID
df = pd.read_csv('train.csv', names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐 妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID',header=0) df.head()
思考:所谓将表头改为中文其中一个思路是:将英文额度表头替换成中文。还有其他的方法吗?
还可以用rename、dict的形式
1.2 初步观察
1.2.1 任务一:查看数据的基本信息
df.info()
1.2.2 任务二:观察表格前10行的数据和后15行的数据
df.head(10)
df.tail(15)
1.2.3 任务三:判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull().head()
也可以查看每一个属性有多少空值
test.isnull().sum()

1.3 保存数据
df.to_csv('train_chinese.csv')
2 第一章(PART2):pandas基础
2.1 知道你的数据叫什么
2.1.1 任务一:pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们
简单的来说pandas只有两种数据类型,Series和DataFrame,Series你可以简单的理解为Excel中的行或者列,DataFrame可以理解为整个Excel表格,当然这只是形象的理解,实际上他们的功能要比Excel灵活的多。
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
参考:https://blog.csdn.net/weixin_42398658/article/details/82925145?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.channel_param
2.1.2 任务二:根据上节课的方法载入"train.csv"文件
2.1.3 任务三:查看DataFrame数据的每列的项
df.columns
2.1.4 任务四:查看"cabin"这列的所有项 [有多种方法]
df['Cabin'].head(3)
df.Cabin.head(3)
#拓展一下:
#查看唯一值
train.Cabin.unique()
#查看唯一值的数目
train.Cabin.nunique()
#查看每个值对应的出现的次数
train.Cabin.value_counts()
2.1.5 任务五:加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除
考察删除列
del test_1['a']
2.1.6 任务六: 将[‘PassengerId’,‘Name’,‘Age’,‘Ticket’]这几个列元素隐藏,只观察其他几个列元素
df.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
思考回答:
如果想要完全的删除你的数据结构,使用inplace=True,因为使用inplace就将原数据覆盖了,所以这里没有用
我之前还以为用df.drop 的话会直接drop掉
2.2 筛选的逻辑
2.2.1 任务一: 我们以"Age"为筛选条件,显示年龄在10岁以下的乘客信息。
2.2.2 任务二: 以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来
2.2.3 任务三:将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
2.2.4 任务四:使用loc方法将midage的数据中第100,105,108行的"Pclass",“Name"和"Sex"的数据显示出来
2.2.5 任务五:使用iloc方法将midage的数据中第100,105,108行的"Pclass”,"Name"和"Sex"的数据显示出来
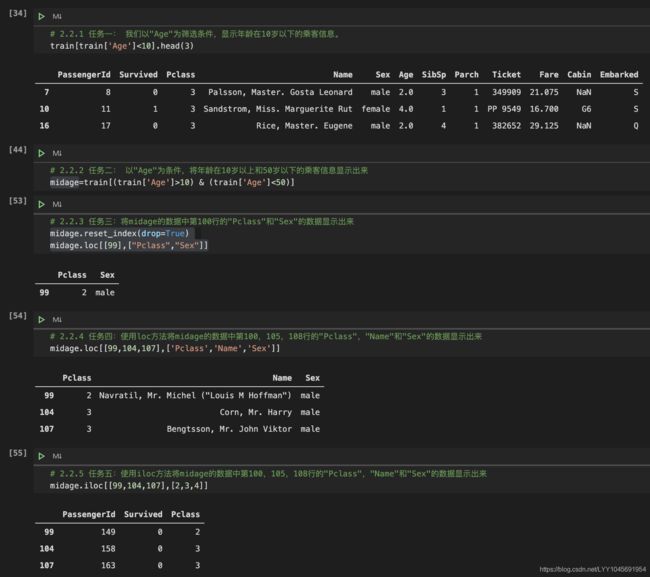
iloc和loc的区别
3 第一章(PART
3):探索性数据分析
3.1 开始之前,导入numpy、pandas包和数据
3.2 了解你的数据吗?
3.2.1 任务一:利用Pandas对示例数据进行排序,要求升序
# 大多数时候我们都是想根据列的值来排序,所以,将你构建的DataFrame中的数据根据某一列,升序排列
frame.sort_values(by='c', ascending=False)
# 让行索引升序排序
frame.sort_index()
# 让列索引升序排序
frame.sort_index(axis=1)
# 让列索引降序排序
frame.sort_index(axis=1, ascending=False)
# 让任选两列数据同时降序排序
frame.sort_values(by=['a', 'c'])
3.2.2 任务二:对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列)
text.sort_values(by=['票价', '年龄'], ascending=False).head(3)
发现票价高、存活率比较高
**3.2.3 任务三:利用Pandas进行算术计算,计算两个DataFrame数据相加结果
frame1_a + frame1_b
两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN。
3.2.4 任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?
3.2.5 任务五:学会使用Pandas describe()函数查看数据基本统计信息
3.2.6 任务六:分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么?**