python 常用模块
collections
-
namedtuple
# 使用可以用名字来访问元素内容的tuple
from collections import namedtuple
Point = namedtuple("Point", ['x', 'y'])
p = Point(1, 2)
print(p.x, p.y) # 坐标使用比较多-
deque
# 由于列表是线性结构导致插入和删除元素很慢,deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
q.popleft()
print(q) # deque([ 'a', 'b', 'c', 'x'])-
Orderedict
# python3.6 之前字典无序 使用OrderedDict保证有序
from collections import OrderedDict
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od) # OrderedDict的Key是有序的-
defaultdic
# 当字典中key不存在时,默认返回一个默认值
from collections import defaultdict
dic1 = defaultdict(lambda: '不存在')
dic1['key1'] = 1
print(dic1['key2']) # key2不存在,返回默认值
dic2 = {"key1": 1}
print(dic2.get("key2")) # 返回None-
Counter
# 统计出现次数,无序的容器,使用字典形式存储
from collections import Counter
b = Counter("-3.1415926abcd3.1415926")
print(b)
random
import random
random.random() # 生成大于0小于1之间的小数
random.uniform(1, 3) # 生成大于1小于3之间的小数
random.randint(1, 5) # 生成大于1小于5之间的整数
random.randrang(1, 10, 2) # 生成大于1小于10之间的奇数
random.choice([1, 'b', [4,5]]) # 随机选择一个返回
random.sample([1, 'b', [4,5]], 2) # 选择2个组合 [1, [4,5]]
item = [1, 3, 5, 7]
random.shuffle(item) # 打乱顺序
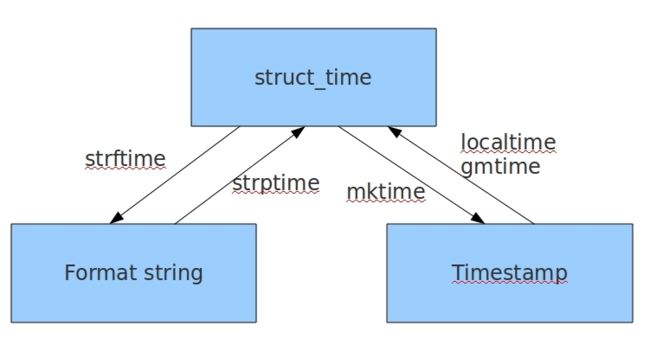
time
# 时间可以转行为三种形式
# 1.时间戳 1592536668.0
# 2.格式化时间 2020-06-19 11:17:48
# 3.元组 time.struct_time(tm_year=2020, tm_mon=6, tm_mday=19, tm_hour=11, tm_min=17, tm_sec=48, tm_wday=4, tm_yday=171, tm_isdst=0)
import time
print(time.time()) # 显示当前时间-时间戳
print(time.strftime("%Y-%m-%d %H:%M:%S")) # 显示当前时间-格式化时间
print(time.localtime()) # 显示当前时间-元组
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # 将元组时间转行为格式化时间
print(time.gmtime(time.time())) # 将时间戳转换为元组
print(time.localtime(time.time())) # 将时间戳转换为元组
print(time.mktime(time.localtime())) # 将元祖转换为时间戳
print(time.strptime("2020-06-19", "%Y-%m-%d")) # 将特定格式时间转行为元组
# 计算时间差
import time
true_time = time.mktime(time.strptime('2018-03-19 08:30:00', '%Y-%m-%d %H:%M:%S'))
time_now = time.mktime(time.strptime('2020-06-19 11:27:00', '%Y-%m-%d %H:%M:%S'))
dif_time = time_now - true_time
struct_time = time.gmtime(dif_time)
print('过去了%d年%d月%d天%d小时%d分钟%d秒' % (struct_time.tm_year - 1970, struct_time.tm_mon - 1,
struct_time.tm_mday - 1, struct_time.tm_hour,
struct_time.tm_min, struct_time.tm_sec))- 转换图解
datetime
# 一般做时间计算比较多
# datetime模块时间默认都是转换为 %Y-%m-%d %H:%M:%S 这种格式
print(datetime.datetime.now()) # 当前时间
print(datetime.date(2020, 6, 19)) # 参数为年月日
print(datetime.time(15, 16, 17)) # 参数为时分秒
print(datetime.datetime(2020, 6, 19, 15, 16, 17)) # 参数为年月日时分秒
# timetimedelta 做时间计算使用
# 常用的参数是days、seconds、minutes、hours、weeks
print(datetime.datetime.now() + datetime.timedelta(weeks=3)) # 三周后
print(datetime.datetime.now() + datetime.timedelta(days=-3)) # 三天前
# fromtimestamp 将时间戳转换为时间
print(datetime.date.fromtimestamp(1592551677.2628834)) # 2020-06-19os
#当前执行这个python文件的工作目录相关的工作路径
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')#和文件夹相关
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
# 和文件相关os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息# 和操作系统差异相关
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'# 和执行系统命令相关
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command").read()) 运行shell命令,获取执行结果
os.environ 获取系统环境变量#path系列,和路径相关
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回Falseos.path.isabs(path) 如果path是绝对路径,返回Trueos.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回Falseos.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回Falseos.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
sys
# sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
json
- json.dumps(obj) :将obj转换成json字符串保存到内存中
- json.dump(obj, fp) :将obj转换成json字符串保存在fp执行的文件中
- json.loads(s) :将内存中的json字符串转换成对应的数据类型对象
- json.load(f) :从文件中读取json字符串,并转换成原来的数据类型
- 在序列化对象时候,可以添加参数default=lambda obj:obj.__dict__
注意:
- json并不能序列化所有数据类型,如set
- 元组数据类型json序列化后,变为列表数据类型
- json文件通常是一次性写入和读取。但可以用文件本身存储方式实现:一行存储一个序列化json,在反序列化是可以按行反序列化
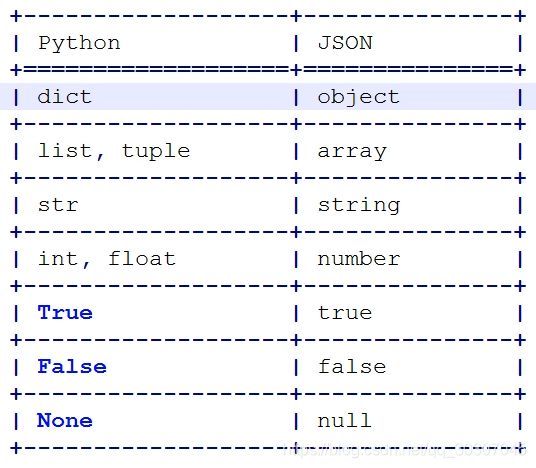
- json数据类型和python数据类型的对比
# 对含有日期格式数据的json数据进行转换
import json
from datetime import datetime
from datetime import date
class JsonCustomEncoder(json.JSONEncoder):
def default(self, field):
if isinstance(field,datetime):
return field.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(field,date):
return field.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self,field)
d1 = datetime.now()
dd = json.dumps(d1,cls=JsonCustomEncoder)
print(dd)pickle
- 和json一样提供了dumps、dump、load、loads方法
- 能将python所有数量类型序列化
- 但是只有python能解析,无法跨语言解析。
- 但是对于将数据以二进制形式存储很方便。
# 逐行读取pickle存储数据
import pickle
with open("admin", mode="rb") as f1:
while True:
try:
obj = pickle.load(f1)
print(obj, end="")
except EOFError:
break
hashlib
# 加密模块
import hashlib
m = hashlib.md5()
# m = hashlib.md5("salt".encode("utf-8")) # 将密码加盐,防止简单密码可通过撞库得到
# m = hashlib.sha1()
# m = hashlib.sha512()
m.update(b'abcdef')
m.update(b'demo') # update可以多次调用,在上一次基础上再次加密
print(m.hexdigest()) # 421fc0f2703c0576ca391abf4dfe0b1c
# print(m.hexdigest()) # 加盐版本:622ee8086368aa7acd237506f5842779
hmac模块
import hmac
import os
h = hmac.new(b'hello', os.urandom(16))
ret = h.digest()
print(ret)
# hmac 做一些网络连接验证,替代hashlib模块
# os.urandom(16) 随机生成16位byte类型字符
re模块
- findall()
- 取所有符合条件的,优先显示分组中的(过滤数据),如果要取消某个分组优先显示(?:)
- search()
- 只取第一个符合条件的,没有优先显示这个问题
- 得到的结果需要group()取值 变量.group()的结果和变量.group(0)结果一致
- 默认获取完整的匹配结果 变量.group(n)的形式来指定获取第n个分组中匹配到的内容
- split()
- 根据规则进行切割,如果进行分组,会保留分组内容(可以分析切分的数据部分是否正确)
ret = re.split("\d+", "abc123def")
print(ret) # [abc, def]
ret = re.split("\d(\d)\d", "abc123def")
print(ret) # [abc, 2, def]- sub()
- 替换内容,第四个参数可选,表示替换几个符合正则规则的字符
ret = re.sub("\d", "-", "abc123def", 2)
print(ret) # abc--3def- subn()
- 返回元组(替换后的结果,替换次数)
ret = re.subn("\d", "-", "abc123def")
print(ret) # ('abc---def', 3)- match()
- 匹配以规定正则规则开头的字符串 相当于search("^正则规则", "字符")
- 与search区别是,思想不同:match()为必须是某种规定的字符;search()为在字符中查找属于某种规则的字符
ret = re.match("\d+", "123abc123def")
print(ret) # <_sre.SRE_Match object; span=(0, 3), match='123'>
print(ret.group()) # 123- compile()
- 将正则解析,节省了多次解析同一个正则表达式的时间,提升效率
ret = re.compile("\d+")
res = ret.search("123abc") # res = ret.findall("123abc")
print(res)
- finditer()
- 返回迭代器,节省空间
ret = re.finditer("\d+", "123abc...")
for i in ret:
print(i.group())- compile()和finditer()结合使用,节省时间和空间
ret = re.compile("\d+")
res = ret.finditer("abc123...")
for i in res:
print(i.group())- 分组命名(?P<名称>正则)
ret = re.search('\d(\d)\d(\w+?)(\d)(\w)\d(\d)\d(?P\w+?)(\d)(\w)\d(\d)\d(?P\w+?)(\d)(\w)',
'123abc45678agsf_123abc45678agsf123abc45678agsf')
print(ret.group('name1'))
print(ret.group('name2')) - 分组命名的引用
- 引用之前标签的内容(必须和之前标签内容一模一样)
exp = '我是一段文字,希望匹配上
乱码文字和乱码标签不希望匹配到的地方'
ret = re.search('<(?P\w+)>.*?', exp) # 这样就匹配不到
print(ret)
shutil
- 类似os模块,不过更多的是针对文件做操作
import shutil
# 拷贝文件
shutil.copy2('原文件', '现文件')
# 拷贝整个目录文件,ignore参数为不需要拷贝的文件类型
shutil.copytree("原目录", "新目录", ignore=shutil.ignore_patterns("*.pyc", ".mp4"))
# 删除目录,ignore_errors为是否忽略错误
shutil.rmtree("temp", ignore_errors=True)
# 移动文件/目录
shutil.move("temp", "/core/temp_bak", copy_function=shutil.copy2)
# 获取磁盘使用空间 如果传.则表示当前磁盘
total, used, free = shutil.disk_usage("c:")
print("当前磁盘共: %iGB, 已使用: %iGB, 剩余: %iGB"%(total / 1073741824, used / 1073741824, free / 1073741824))
# 当前磁盘共: 233GB, 已使用: 90GB, 剩余: 143GB
# 压缩文件
shutil.make_archive('压缩文件夹的名字', 'zip','待压缩的文件夹路径')
shutil.make_archive('logging2', 'zip','/Users/jingliyang/PycharmProjects/面试题/常用模块/随机数')
# 解压文件 如果不写目录默认解压到当前目录
shutil.unpack_archive('zip文件的路径.zip','解压到目的文件夹路径')
shutil.unpack_archive('/Users/jingliyang/PycharmProjects/面试题/常用模块/shutil模块/logging2.zip','/Users/jingliyang/PycharmProjects/面试题/常用模块/shutil模块/tmp')
logging
- 日志级别
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
# CRITICAL > ERROR > WARNING > INFO > DEBUG- 常用的输出模式 文件+屏幕
import logging
# 同时向文件和屏幕上输出
fh = logging.FileHandler('tmp.log', encoding='utf-8') # 文件操作符
sh = logging.StreamHandler() # 屏幕输出操作符
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s[line :%(lineno)d]-%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=logging.DEBUG,
handlers=[fh, sh] # 操作符
)
logging.debug('debug 信息错误 test2')
logging.info('warning 信息错误 test2')
logging.warning('warning message test2')
logging.error('error message test2')
logging.critical('critical message test2')- 日志切割
# 做日志的切分
import logging
from logging import handlers
sh = logging.StreamHandler()
rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,
backupCount=5) # 按照大小做切割 backupCount表示切几次文件,当达到最大值再次切割文件时候会将第一次产生的文件删除
fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5,
encoding='utf-8') # 按照时间做切割 when参数接收时间单位 interval参数接收时间间隔大小 每次切割后面以时间做结尾区分 x2.log.2020-06-23-33
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s[line :%(lineno)d]-%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=logging.DEBUG,
# handlers=[fh,sh,fh2]
handlers=[fh, rh, sh]
)