学习笔记 快速过一遍C语言(2)数组/函数/指针/结构体/冒泡排序/枚举/反码/链表/位运算符
文章类型:C语言学习笔记
课程:《郝斌C语言自学教程》
视频时长:38h30min
观看时间:2020.3.28-2020.4.11
感想:啊啊啊,老子终于学完了!!!
评价:超棒的老师,转战郝斌老师的sql和数据结构
目录:
八、数组
九、函数
十、指针
十一、结构体
十二、冒泡排序
十三、枚举
十四、原码、补码、反码、移码
十五、链表
十六、位运算符
首先先补充一下之前的内容:
char
char ch = a; //error
char ch = ‘b’; //定义单个字符串要用单引号括起来
char ch = “abadf”
//定义多个字符串要用双引号括起来,且默认最后一个字符为 \0
//即 char ch = “A” 里面的内容有两个字符 “A"和”\0"
八、数组(不是学习重点)
1.为什么需要数组?
为了解决大量同类型数据的存储和使用问题;
为了模拟现实世界。
2.数组的分类
(1)一维数组:
怎样定义一维数组?
为n个变量连续分配存储空间;
所有变量的数据类型必须相同;
所有变量所占的字节大小必须相同。
eg:
int a[5];
一维数组名不代表数组中的所有的元素,
一维数组名代表数组第一个元素的地址。
有关一维数组的操作
a.初始化:
完全初始化:
int a[5] = {1,2,3,4,5};
不完全初始化:未被初始化的元素自动为零
int a[5] = {1,2,3};
不初始化:所有元素是垃圾值
int a[5];
清零:
int a[5] = {0};
b.错误写法:
int a[5];
a[5] = {1,2,3,4,5}; //错误
只有在定义数组的同时才可以整体赋值,
其他情况下整体赋值是错误的
int a[5] = {1,2,3,4,5};
a[5] = 100; //错误,因为没有a[5]这个元素
int a[5] = {1,2,3,4,5};
int b[5];
把数组a的值全部赋给数组b
错误的写法: b = a; //错误
正确的写法:
for (i=0; i<5; ++i)
b[i] = a[i];
c.赋值:
scanf("%d",&a[0]);
(2)二维数组:
int a[3][4];
总共12 个元素,可以当做3行4列看待,这12个元素的名字依次是:
a[0][0] a[0][1] a[0][2] a[0][3]
a[1][0] a[1][1] a[1][2] a[1][3]
a[2][0] a[2][1] a[2][2] a[2][3]
初始化:
int a[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12};
int a[3][4] = { //建议使用
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10,11,12}
}
输出二位数组的内容:使用双层循环
(3)多维数组
是否存在多维数组?
不存在多维数组,因为内存是线性的,
n维数组可以当做每个元素是n-1维数组的数组。
如:int a[3][4];
该数组是含有3个元素的一维数组,
只不过每个元素都可以再分成4个小元素。
int a[3][4][5];
该数组是含有3个元素的一维数组,
只不过每个元素都是含有4行5列的二维数组。
九、函数
1.为什么需要函数?
避免了重复性操作;
有利于程序的模块化;
2.什么叫做函数?
逻辑上:能够完成特定功能的独立的代码块
物理上:能够接收数据(当然也可以不接收数据)、能够对接收的数据进行处理、能够将处理数据的结果返回(当然也可以不返回任何数据)
总结:函数是个工具,它是为了解决大量类似的问题而设计的
函数可以当做一个黑匣子
3.如何定义函数?
格式:
函数的返回值的类型 函数的名字(函数的形参列表)
{
函数的执行体
}
(1)函数定义的本质是详细描述函数之所以能够实现某个特定功能的具体的方法。
(2)return表达式的含义:
a.终止被调函数,向主调函数返回表达的值;
b.如果表达式为空,则只终止函数,不向主调函数返回任何值。(return;)
(3)break是用来终止循环和switch的,return是用来终止函数的。
eg:
void f()
{
return; //只用来终止函数,不向主调函数返回任何值
}
int f()
{
return 10; //第一:终止函数;第二:向主调函数返回10
}
(3)函数返回值的类型也称为函数的类型,因为如果函数名前的返回值类型和函数执行体中的return表达式中的表达式类型不同的话,则最终函数返回值的类型以函数名前的返回值类型为准。
eg:
int f()
{
return 10.5;
}
//因为函数的返回值类型是int,
//所以最终f返回的是10而不是10.5
4.函数的分类
有参函数 和 无参函数
有返回值 和 无返回值
库函数 和 用户自定义函数
值传递函数 和 地址传递函数
普通函数 和 主函数(main函数)
一个程序必须有且只有一个主函数
主函数可以调用普通函数 普通函数不能调用主函数
普通函数之间可以相互调用
主函数是程序的入口,也是程序的出口
注意:
函数调用与函数定义的顺序:
如果函数调用写在了函数定义的前面,则必须加函数前置声明;
函数前置声明:
(1)告诉编译器即将可能出现的若干个字母代表的是一个函数;
(2)告诉编译器即将可能出现的若干个字母所代表的的函数的形参和返回值的具体情况;
(3)函数声明是一个语句,末尾必须加分号;
(4)对库函数的声明是通过#include<库函数所在的文件的名字.h>来实现的;
形参和实参:
个数相同、位置一一对应、数据类型必须相互兼容
如何在软件开发中合理设计函数来解决实际问题:
一个函数的功能尽量独立,单一;
多学习、模仿牛人写的代码。
函数是C语言的基本单位,类是Java,C#,C++的基本单位.
5.变量的作用域和存储方式:
按作用域分:
(1)全局变量:
在所有函数外部定义的变量叫做全局变量。
全局变量的使用范围:从定义位置开始到整个程序结束。
(2)局部变量:
在一个函数内部定义的变量或函数的形参都统称为局部变量。
局部变量的使用范围:只能在本函数内部使用。
(3)全局变量和局部变量命名冲突的问题:
在一个函数内部如果定义的局部变量的名字和全局变量的名字一样时,局部变量会屏蔽全局变量。
按变量的存储方式分:
静态变量
动态变量
寄存器变量
十、指针
1.指针的重要性:
表示一些复杂的数据结构
快速的传递数据,较少了内存的耗用【重点】
使函数返回一个以上的值(及时函数中有多个return也只能执行其中一个,即只能返回一个,因为return有结束该函数的功能。)【重点】
能直接访问硬件
能够方便的处理字符串
是理解面向对象语言中引用的基础
总结:指针是C语言的灵魂
2.指针的定义:
地址
内存单元的编号
从零开始的非负整数
指针
指针就是地址,地址就是指针
指针变量就是存放内存单元编号的变量,或者说指针变量就是存放地址的变量
指针和指针变量是两个不同的概念,但是要注意:通常我们叙述时会把指针变量简称为指针,实际上它们含义并不一样
指针的本质就是一个操作受限的非负整数
3.指针的分类:
(1)基本类型指针
例子:
#include
int main(void)
{
int * p; //p是变量的名字,int * 表示p变量存放的是int类型变量的地址
//int * p;应该这样理解:p是变量名,p变量的数据类型是int *类型;所谓int *类型实际就是存放int变量地址的类型
int i =3;
p = &i; //OK
/*
1.p保存了i的地址,因此p指向i;
2.p不是i,i也不是p,更准确的说:修改p的值不影响i的值,修改i的值也不会影响p的值;
3.如果一个指针变量指向了某个普通变量,则 *指针变量 就完全等同于 普通变量
例子:
如果p是个指针变量,并且p存放了普通变量i的地址,则p指向了普通变量i
*p 就完全等同于 i
或者说:
在所有出现*p的地方都可以替换成i;
在所有出现i的地方都可以替换成*p
*p 就是以p的内容为地址的变量
*/
//p = i; //error,因为类型不一致,p只能存放int类型变量的地址,不能存放int类型变量的值
//p = 55; //error,原因同上
j = *p; //等价于 j = i;
printf("i = %d, j = %d\n",i,j); //输出结果是3 3
}
常见错误例子:
#include
int main(void)
{
int * p;
int i = 5;
*p = i;
printf("%d\n",*p);
return 0;
}
常见错误例子:
#include
int main(void)
{
int i = 5;
int * p;
int * q;
p = &i;
//*q = p; //error 语法编译会出错
//*q = *p; //error
p = q; //q是垃圾值,q赋给p,p也是垃圾直
printf("%d\n", *q); //13行
/*
q的空间是属于本程序的,所以本程序可以读写q的内容,
但是如果q的内部是垃圾值,则本程序不能读写*q的内容
因为此时*q所代表的的内存单元的控制权限并没有分配给本程序
所以本程序运行到13行时就会立即报错
*/
return 0;
}
用指针实现两个数互换的例子:
#include
void huhuan(int * p, int * q)//void huhuan(int *, int *) 可以这样写,不需要形参名字
{
int t; //如果要互换*p和*q的值,则t必须定义成int,不能定义成int *,否则语法会出错
t = *p; //p是int *, *p是int
*p = *q;
*q = t;
}
int main(void)
{
int a = 3;
int b = 5;
huhuan(&a, &b);
printf("a = %d, b = %d\n",a, b);
return 0;
}
-------------------
a = 5, b = 3
-------------------
附注:
*的含义:
(1)乘法
(2)定义指针变量
int * p;
定义了一个名字叫做p的指针变量,int *表示p只能存放int型变量的地址
(3)指针运算符
该运算符放在已经定义好的指针变量的前面
如果p是一个已经定义好的指针变量
则 *p 表示以p的内容位地址的变量
如何通过被调函数修改主调函数普通变量的值:
1.实参必须为该普通变量的地址;
2.形参必须为指针变量;
3.在被调函数中通过
*形参名 = …
的方式就可以修改主调函数相关变量的值。
(2)指针和数组
指针和一维数组
一维数组名:
一维数组名是个指针常量,
它存放的是一维数组第一个元素的地址
printf("%#X\n",&a[0]);
等价于
printf("%#X\n",a);
即a == &a[0]
下标和指针的关系
如果p是个指针变量,则 p[i] 永远等价于 *(p+i)
(解释:p[i]和*(p+i)意思一样,表示同一“变量”。 或许你已经听说过,数组名本身就是指针。如: int a[5]; 那么,a就是一个指针,它指向数组的第一个元素。反过来,每一个指针都可以当做一个数组来用。如: char p=“0123”; 那么,编译器会分配5字节存储字符串“0123”,而p则指向第一个字符’0’。所以,p==‘0’,(p+3)==‘3’。其实完全可以不用运算符,由“等价”可知:p[0]‘0’,p[3]‘3’)
确定一个一维数组需要几个参数(如果一个函数要处理一个一维数组,则需要接收该数组的哪些信息):
需要两个参数:
数组第一个元素的地址
数组的长度
例子:
#include
void f(int * pArr, int len)
{
pArr[3] = 88; // pArr[3] 相当于 *(pArr + 3)
}
int main(void)
{
int a[6] = {1,2,3,4,5,6};
printf("%d\n",a[3]); //输出为4
f(a, 6);
printf("%d\n",a[3]); //输出为88
return 0;
}
例子:
#include
void f(int * pArr, int len)
{
int i;
for(i=0; i 指针变量的运算
指针变量不能相加、不能相乘、也不能相除。
如果两个指针变量指向的是同一块连续空间中的不同存储单元则这两个变量才可以相减。
一个指针变量到底占几个字节:
预备知识:sizeof(数据类型/变量名)
功能:返回值就是该数据类型/变量名所占的字节数
假设p指向char类型变量(1个字节)sizeof(char)=1
假设q指向int类型变量(4个字节)sizeof(int)=4
假设r指向double类型变量(8个字节)sizeof(double)=8
p、q、r本身所占的字节数是否一样?
答案:一样的。
总结:
一个指针变量,无论它指向的变量占几个字节
该指针变量本身只占4个字节。
一个变量的地址是使用该变量首字节的地址来表示。
指针和二维数组
(3)指针和函数
(4)指针和结构体
(5)多级指针
专题:(重要)
动态内存的分配:
(1)传统数组的缺点:
a.数组长度必须事先制定;
b.传统形式定义的数组,该数组的内存程序员无法手动释放;
在一个函数运行期间,系统为该函数中的数组所分配的空间会一
直存在,直到该函数运行完毕时,数组的空间才会被系统释放。
c.数组的长度一旦定义,其长度就不能更改。
数组的长度不能在函数运行的过程中动态的扩充或缩小。
d.A函数定义的数组,在A函数运行期间可以被其他函数使用,
但A函数运行完毕之后,A函数中的数组将无法再被其他函数
使用。
传统方式定义的数组不能跨函数使用。
(2)为什么需要动态分配内存?
动态数组很好的解决了传统数组的这4个缺陷。
传统数组也叫静态数组。
(3)动态内存分配举例__动态数组的构造
a. malloc函数的使用:(malloc是memory(内存)allocate(分配)的缩写)
例子1:
#include
#include //不能省
int main(void)
{
int i = 5; //11行//分配了4个字节,静态分配
int * p = (int *)malloc(4); //12行
/*
1.要是用malloc函数,必须添加malloc.h这个头文件;
2.malloc函数只有一个形参,并且形参是整型;
3. 4表示请求系统为本程序分配4个字节;
4.malloc函数只能返回第一个字节的地址;
5.12行分配了8个字节,p变量占4个字节,p所指向的内存
也占4个字节;
6.p本身所占的内存是静态分配的,p所指向的内存是动态分
配的
*/
*p = 5;//*p代表的是一个int变量,只不过*p这个整型变量的内存分配方式和11行的i变量的分配方式不同
free(p);
/*
free(p)表示把p所指向的内存释放掉,p本身的内存是静态的,不能由程序员手动释放,p本身的内存只能在p变量所在的函数运行终止时由系统自动释放。
*/
return 0;
}
例子2:
#include
#include
int main(void)
{
int a[5];
int len;
int * pArr;
int i;
//动态的构造一维数组
printf("请输入你要存放的元素的个数:");
sacnf("%d",&len);
pArr = (int *)malloc(4 * len); //动态的构造了一个一维数组,这个一维数组的长度为len,该数组的类型为int类型
//对一位数组进行操作:赋值
printf("请对一维数组的所有元素进行赋值:\n");
for(i=0;i (4)静态内存和动态内存的比较:
静态内存是由系统自动分配的,由系统释放。
动态内存是由程序员手动分配的,手动释放(忘记释放可能会导致内存泄漏的问题的出现);
动态内存是在堆分配的。
多级指针:
#include
int main(void)
{
int i = 10;
int * p = &i;
int ** q = &p;
int *** r = &q;
//r = &p; //error,因为r是int *** 类型,r只能存放int **类型变量的地址
return 0;
}
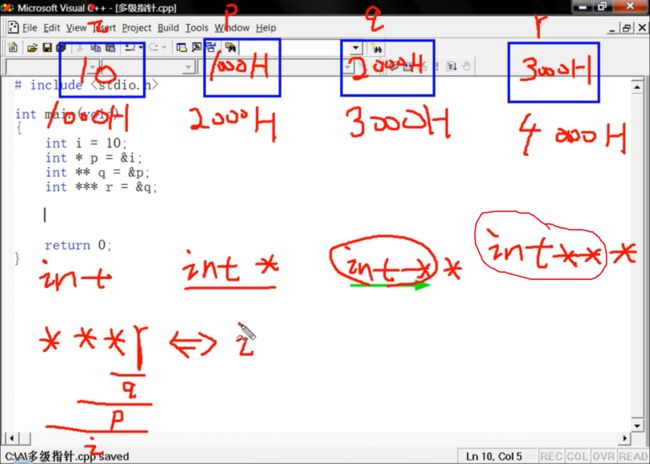
图片内容总结:
里面想表达的就是
int i;
int * p; //这里的p只能存放int类型的地址
int ** q; //这里的q只能存放int*类型的地址
int *** r; //这里的r只能存放int**类型的地址
例子:
#include
void f(int ** q) //这里必须两个*,q是个指针变量,无论q是什么类型的指针变量,都只占4个字节
{
//*q就是p
}
void g()
{
int i = 10;
int * p = &i;
f(&p); //p是int *类型,&p是int **类型
}
int main(void)
{
g();
return 0;
}
(5)跨函数使用内存的问题
静态内存不能跨函数使用,虽然可以进行赋值,语法上不会出错,但是由于在一个函数中执行结束后它的内存已经被函数释放掉。
动态内存可以跨函数使用
例子:
#include
#include
void f(int ** q)
{
*q = (int *)malloc(sizeof(int)); //等价于p = (int *)malloc(sizeof(int));
**q = 5; //*p=5;实现了把p指向的地址的值改成5
//q = 5; //error
//*q = 5; //error
}
int main(void)
{
int * p;
f(&p);
printf("%d\n",*p); //这里可以使用*p,因为上面的f()函数终止,动态内存空间没有被释放
return 0;
}
十一、结构体
(1)为什么需要结构体?
为了表示一些复杂的事物,而普通的基本类型无法满足实际要求。
(2)什么叫结构体?
把一些基本类型数据组合在一起形成的一个新的复合数据类型,这就叫结构体。
(3)如何定义结构体?
#include
//第一种方式,用这个
struct Student
{
int age;
float score;
char sex;
};
//第二种方式,别用
struct Student2
{
int age;
float score;
char sex;
}st2;
//第三种方式,别用
struct
{
int age;
float score;
char sex;
}st3;
int main(void)
{
struct Student st = {80, 66.6, 'F'}; //第一种方式
return 0;
}
(4)怎样使用结构体变量?
a.赋值和初始化:
#include
struct Student
{
int age;
float score;
char sex;
};
int main(void)
{
struct Student st = {80, 66.6, 'F'}; //初始化 定义的同时赋初值才能直接整体赋初值,如果定义完之后,则只能单个的赋初值
struct Student st2;
st2.age = 10;
st2.score = 88;
st2.sex = 'F';
printf("%d %f %c\n",st.age,st.score,st.sex);
printf("%d %f %c\n",st2.age,st2.score,st2.sex);
return 0;
}
b.如何取出结构体变量中的每一个成员?
第一种:结构体变量名.成员名
第二种:指针变量名->成员名 (第二种方式更常用)
指针变量名->成员名 在计算机内部会被转化成 (*指针变量名).成员名 的方式来执行,所以这两种方式是等价的。
#include
struct Student
{
int age;
float score;
char sex;
};
int main(void)
{
struct Student st = {80, 66.6F, 'F'};
struct Student * pst = &st; //&st不能改成st
pst->age = 88; //第二种方式
st.score = 66.6f; //第一种方式
//66.6在C语言中默认是double类型,如果希望一个实数是float类型,则必须在末尾加f或F,因此66.6是double类型,66.6f或66.6F是float类型
//float和double这些浮点数类型都不保证每个数字都能准确存储
printf("%d %f \n",st.age,st.age,pst->score);
return 0;
}
解析:
1.pst->age 在计算机内部会被转化成 (*pst).age,这是一种硬性规定。
2.所以pst->age等价于(*pst).age也等价于st.age
3.pst->age的含义:
pst所指向的那个结构体变量中的age这个成员
c.结构体变量和结构体指针变量作为函数参数传递的问题:
推荐使用结构体指针变量作为函数参数来传递
举例1:
动态构造存放学生信息的结构体数组
#include
#include
struct Student
{
int age;
char sex;
char name[100];
};
void InputStudent(struct Student *);
void OutputStudent(struct Student *);
int main(void)
{
struct Student st;
InputStudent(&st); //对结构体变量输入必须发送st的地址
OutputStudent(&st); //可以发送st的地址也可以直接发送st的内容,但为了减少内存的耗费,也为了提高执行速度,推荐发送地址
return 0;
}
void InputStudent(struct Student * pstu)
{
(*pstu).age=10;
strcpy(pstu->name, "张三");
pstu->name = 'F';
}
void OutputStudent(struct Student * pst)
{
printf("%d %c %s\n",pst->age,pst->sex,pst->name);
}
发送地址还是发送内存?
目的:
指针的优点之一:
快速的传递数据
耗用内存小
执行速度快
举例2:
动态构造存放学生信息的结构体数组
#include
#include
struct Student
{
int age;
float score;
char name[100];
};
int main(void)
{
int len;
struct Student * pArr;
int i, j;
struct Student t;
printf("请输入学生个数: \n");
printf("len = ");
scanf("%d",&len);
pArr = (struct Student *)malloc(sizeof(struct Student) * len);
for(i=0; i pArr[j+1].score)
{
t = pArr[j];
pArr[j]= pArr[j+1];
pArr[j+1]= t;
}
}
}
//输出
for (i=0; i 该程序缺点代码过于杂乱,建议写三个函数。
d.结构体变量的运算:
结构体变量不能相加,不能相减,也不能相互乘除,但结构体变量可以相互赋值。
例子:
struct Student
{
int age;
char sex;
char name[100];
};
struct Student st1, st2;
st1+st2 st1*st2 st1/st2 都是错误的
st1 = st2 或者 st2 = st1;才是正确的
十二、冒泡排序
例子:
#include
void sort(int * a, int len)
{
int i, j, t;
for (i=0; i a[j+1]) //这里用 > 表示升序,用 < 表示降序
{
t = a[j];
a[j] = a[j+1];
a[j+1] = t;
}
}
}
}
int main(void)
{
int a[6] = {10, 2, 8, -8, 11, 0};
int i = 0;
sort(a, 6);
for(i=0; i<6; ++i)
{
printf("%d ", a[i]);
}
return 0;
}
十三、枚举
(1)什么是枚举
把一个事物所有可能的取值一一例举出来
(2)怎样使用枚举
# include
//只定义了一个数据类型,并没有定义变量,该数据类型的名字是enum WeekDay
enum WeekDay
{
Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday
};
int main(void)
{
enum WeekDay day = Wednesday; //这里赋值只能是定义的7个,不能是其他,限制了范围
return 0;
}
(3)枚举的优缺点
代码更安全
书写麻烦
十四、原码、补码、反码、移码
原码:
也叫 符号-绝对值 码
最高位 0 表示正, 1 表示负,其余二进制位是该数字的绝对值的二进制位
原码简单易懂
加减运算复杂
存在加减乘除四种运算,增加了CPU的复杂度
零的表示不唯一
反码:
反码运算不便,也没有在计算机应用
移码:
移码表示数值平移n位,n称为移码量
移码主要用于浮点数的阶码的存储
补码:
已知十进制转求二进制:
求正整数的二进制:
除2取余,直至商为零,余数倒叙排序
求负整数的二进制:
先求与该负数相对应的正整数的二进制代码,然后将所有位取反,末尾加1,不够位数时,左边补1
求零的二进制:
全是零
已知二进制求十进制:
如果首位是0,则表明是正整数:
按普通方法来求。
如果首位是1,则表明是负整数:
将所有位取反,末尾加1,所得数字就是该负数的绝对值
如果全是零,则对应的十进制数字就是零。
8位二进制所代表的十进制示意图:
二进制 十进制
0000 0000 -- 0
0000 0001 -- 1
.... ....
0111 1111 -- 127
1000 0000 -- -128
1000 0001 -- -127
1000 0010 -- -126
.... ....
1111 1111 -- -1
在Vc++6.0宗一个int类型的变量所能存储的数字的范围是多少:
int类型变量所能存储的最大正数用十六进制表示是:7FFFFFFF
int类型变量所能存储的绝对值最大的负整数用十六进制表示是:80000000
具体参见上面的8位二进制所代表的十进制示意图
绝对值最小负数的二进制代码是多少?
前面一个1,后面全是0
最大正数的二进制代码是多少?
前面一个0,后面全是1
数字超过最大正数会怎样?
会溢出,把前面的丢弃掉,后面的保留下来
二进制全部为零的含义: 000000000000的含义
1.数值零
2.字符串结束标记 ‘\0’
3.空指针NULL
NULL本质也是零,而这个零不代表数字零,而代表的是内存单元的编号零。
我们计算机规定了,以零为编号的存储单元的内容不可读,不可写。
十五、链表
算法:
通俗定义:
解题的方法和步骤
狭义定义:
对存储数据的操作
对不同的存储结构,要完成某一个功能的操作是不一样的。
比如:
要输出数组中所有元素的操作和要输出链表中所有元素的操作肯定是不一样的
这说明:
算法是依附于存储结构的
不同的存储结构,所执行的算法是不一样的
广义定义:
广义的算法也叫泛型
无论数据是如何存储的,对数据的操作都是一样的。
我们至少可以通过两种结构来存储数据:
数组:
优点:
存取速度快
缺点:
需要一个连续的很大的内存
插入和删除元素的效率很低
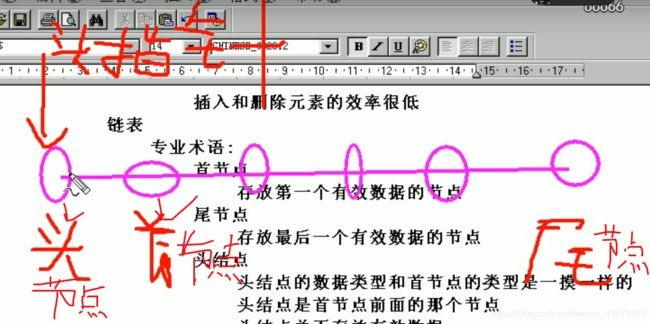
链表:
专业术语:
头结点:
头结点的数据类型和首节点的类型是一摸一样的。
头结点是首节点前面的那个节点。
头结点并不存放有效数据。
设置头结点的目的是为了方便对链表的操作。
头指针:
存放头结点地址的指针变量。
首节点:
存放第一个有效数据的节点
尾结点:
存放最后一个有效数据的节点
确定一个链表需要一个参数:头指针
优点:
插入删除元素效率高
不需要一个连续的很大的内存
缺点:
查找某个位置的元素效率低
链表例子:
# include
# include
# include
struct Node
{
int data; //数据域
struct Node * pNext; //指针域
};
//函数声明
struct Node * create_list(void);
void traverse_list(struct Node *);
int main(void)
{
struct Node * pHead = NULL; //等价于 struct Node * pHead = NULL;
pHead = create_list(); //create_list()功能:创建一个非循环单链表,并将该链表的头结点的地址付给pHead
traverse_list(pHead);
return 0;
}
struct Node * create_list(void)
{
int len; //用来存放有效节点的个数
int i;
int val; //用来临时存放用户输入的结点的值
//分配了一个不存放有效数据的头结点
struct Node * pHead = (struct Node *)malloc(sizeof(struct Node));
if (NULL == pHead)
{
printf("分配失败, 程序终止!\n");
exit(-1);
}
struct Node * pTail = pHead;
pTail->pNext = NULL;
printf("请输入您需要生成的链表节点的个数: len = ");
scanf("%d", &len);
for (i=0; idata = val;
pTail->pNext = pNew;
pNew->pNext = NULL;
pTail = pNew;
}
return pHead;
}
void traverse_list(struct Node * pHead)
{
struct Node * p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
return;
}
十六、位运算符
(1)
& 按位与(把每一位二进制代码按位相与)
&& 逻辑与 也叫并且(逻辑运算符的结构只能是真或假,在C中,真用1表示,假用0表示)
1&1=1
1&0=0
0&1=0
0&0=0
&&与&的含义完全不同:
5&7 结果是 5(0101与01111按位相与得到0101即5)
5&&7 结果是 1
(2)
| 按位或
|| 逻辑或
1|1=1
1|0=1
0|1=1
0|0=0
- (3)
-
按位取反
~i就是把i变量所有的二进制位取反
~3 = -4(int占4个字节一共有32位,先换成原码取反后加一编程补码,来计算它的值)
(4)
^ 按位异或
相同为0
不同为1
1^0=1
1^1=0
0^1=1
0^0=0
(5)
<< 按位左移
i=3;
i<<1; //i的结果为6
表示把i的所有二进制位左移一位,右边补0。
左移一位相当于乘以2的n次方(重要)
面试题:
A) i=i*8;
B) i=i<<3;
请问上述两个语句,那个语句的执行速度快?
B的速度快
(6)
>> 按位右移
>>
>> i=3;
>> i>>3; //i的结果为6
>> 表示把i的所有二进制位右移三位,左边一般补0,当然也可能补1。
>> 右移一位相当于除以2的n次方,前提是数据不能够丢失
>> 面试题:
>> A) i=i/8;
>> B) i=i>>3;
>> 请问上述两个语句,那个语句的执行速度快?
>> B的速度快
位运算符的显示意义:
通过位运算符我们可以对数据的操作精确到每一位。
结束语:很开心终于看完了,加油,各位!!!