Datawhale数据分析-Task2-part1-数据清洗和特征处理
Datawhale数据分析-Task2-part1-数据清洗和特征处理
数据清洗
缺失值观察与处理
我们拿到的数据经常会有很多缺失值,比如我们可以看到Cabin列存在NaN,那其他列还有没有缺失值,这些缺失值要怎么处理呢
方法1:使用isnull().sum()
train_df.isnull().sum()
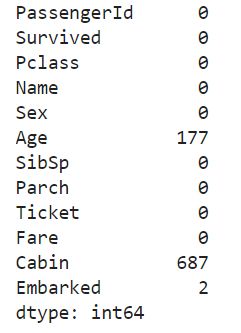
- 'Age’有177个缺失值
- 'Cabin’有687个缺失值
- 'Embared’ 有2个缺失值
方法2:info()函数
train_df.info()

缺失值处理
(1) 处理缺失值一般有几种思路:
- 可以丢弃带有缺失值的项,但是会减少sample数,信息损失
- 用统计特征值,比如平均数,中位数,方差等填充
- 用贝叶斯方法
(2) 请尝试对Age列的数据的缺失值进行处理
# 以下任意个方法都可以
train_df[train_df['Age'].isnull()] = 0
train_df[train_df['Age']==np.nan] = 0
None在缺失值特征为float64类型时检索不到,所以用np.nan
(3) 请尝试使用不同的方法直接对整张表的缺失值进行处理
train_df.dropna()
重复值观察与处理
查看重复值
train_df[train_df.duplicated()]
去除有重复值的记录
train_df.drop_duplicates()
特征观察与处理
对Age进行分箱操作
将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
train_df['AgeBin'] = pd.cut(train_df['Age'], 5,\
labels = ['1','2','3','4','5'])
__将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
__
train_df['AgeBand'] = pd.cut(train_df['Age'],[0,5,15,30,50,80],、
labels = ['1','2','3','4','5'])
任务三:从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
train_df['title'] = train_df['Name'].str.extract(r'([a-zA-Z]+)\.', expand=False)
注意括号内是要提取的内容