ElasticSearch第九篇:match和term查询的区别,match_phrase短语查询,bool联合查询
本博客以51job数据作为数据支持
1.match查询
match查询会先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配,因此相比于term的精确搜索,match是分词匹配搜索,match搜索还有两个相似功能的变种,一个是match_phrase,一个是multi_match。对于最基本的match搜索来说,只要搜索词的分词集合中的一个或多个存在于文档中即可。
基本的match查询:
GET 51job/_doc/_search
{
"query": {
"match": {
"company":"鹏开物讯"
}
}
}结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 8.13081,
"hits" : [
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "8Ueg-3MBrm2PQExGCb_A",
"_score" : 8.13081,
"_source" : {
"id" : 1,
"job" : "中级java工程师(南山科技园,双休)",
"company" : "深圳物讯科技有限公司",
"place" : "深圳-南山区",
"salar" : "1-1.5万/月",
"data" : "12-13"
}
},
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "9Ueg-3MBrm2PQExGCb_A",
"_score" : 7.407011,
"_source" : {
"id" : 5,
"job" : "Java开发工程师",
"company" : "深圳鹏开信息技术有限公司",
"place" : "深圳-罗湖区",
"salar" : "1.3-1.6万/月",
"data" : "12-13"
}
}
]
}
}因为company字段我映射了ik分词器,所以搜索词“鹏开物讯”被分成了鹏开和物讯,然后文档里根据ik分词器将鹏开和物讯两个词形成了倒排索引,所以结果只会出现包含鹏开和物讯的文档(注意:mapping里字段要映射分词器哦,光给搜索词分词没用的呀)。
match_phrase查询:
match_phrase为按短语搜索,用英文来解释(中文分词后其实已经是一个一个有具体意思的词语)。英文中以空格分词,因此分词后是一个个的单词,当想搜索类似hope so这样的短语时,你或许并不想将一些只含有hope的文档搜索出来,也不想将一些类似I hope ×××. So ××这样的搜索出来,此时,就可以用match_phrase。
match_phrase的搜索方式和match类似,先对搜索词建立索引,并要求所有分词必须在文档中出现(像不像operator为and的match查询),除此之外,还必须满足分词在文档中出现的顺序和搜索词中一致且各搜索词之间必须紧邻,因此match_phrase也可以叫做紧邻搜索。
现在搜索"鹏开信息技术"
GET 51job/_doc/_search
{
"query": {
"match_phrase": {
"company":"鹏开信息技术"
}
}
}结果如下:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 11.7788315,
"hits" : [
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "9Ueg-3MBrm2PQExGCb_A",
"_score" : 11.7788315,
"_source" : {
"id" : 5,
"job" : "Java开发工程师",
"company" : "深圳鹏开信息技术有限公司",
"place" : "深圳-罗湖区",
"salar" : "1.3-1.6万/月",
"data" : "12-13"
}
}
]
}
}如果我改变他们呢的位置,搜索"鹏开信息"或者"鹏开技术信息",结果如下:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}可以看到,对搜索词的位置进行变换之后,则查询不到,为什么会这样呢?
这里说明一下匹配原理:
文档"深圳鹏开信息技术有限公司"会被分词建立倒排索引,索引如下:
深圳[0] , 鹏开[1] , 信息技术[2] , 信息[3] , 技术[4] , 有限公司[5] , 有限[6] , 公司[7]
1.es会先过滤掉不符合的query条件的doc:
在搜索"鹏开技术信息"时,被分词成 鹏开[0] , 技术信息[1] , 技术[2] , 信息[3]
很明显,技术信息这个分词在文档的倒排索引中不存在,所以被过滤掉了
2.es会根据分词的position对分词进行过滤和评分,这个是就slop参数,默认是0,意思是查询分词只需要经过距离为0的转换就可以变成跟doc一样的文档数据
在搜索"鹏开信息"时,如果不加上slop参数,那么在原文档的索引中,"鹏开"和"信息"这两个分词的索引分别为1和3,并不是紧邻的,中间还存在一个"信息技术"分词,很显然还需要经过1的距离,才能与搜索词相同。所以会被过滤。
那么我们加上slop参数就好了,再来看看:
GET 51job/_doc/_search
{
"query": {
"match_phrase": {
"company":{
"query":"鹏开信息",
"slop":1
}
}
}
}结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 5.8996553,
"hits" : [
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "9Ueg-3MBrm2PQExGCb_A",
"_score" : 5.8996553,
"_source" : {
"id" : 5,
"job" : "Java开发工程师",
"company" : "深圳鹏开信息技术有限公司",
"place" : "深圳-罗湖区",
"salar" : "1.3-1.6万/月",
"data" : "12-13"
}
}
]
}
}这样是不是可以查到想要的结果了!
2.term查询
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个。比如说我们要找公司名为深圳鹏开信息技术有限公司的所有文档:
GET 51job/_doc/_search
{
"query": {
"term": {
"company":"深圳鹏开信息技术有限公司"
}
}
}以下是搜索结果:
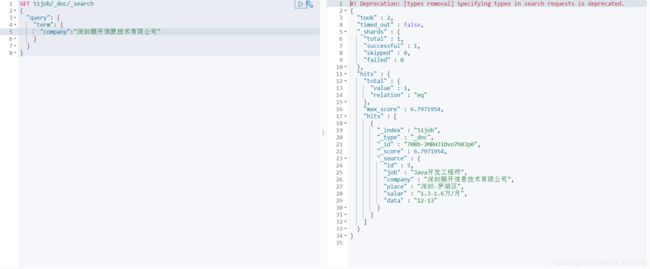
假如只搜索鹏开这个词,是搜索不到的,如下:
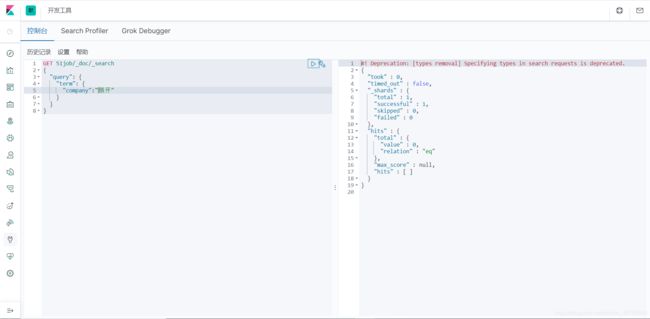
3.bool查询
参数1:must 必须匹配
参数2:must_not 必须不匹配
参数3:should 默认情况下,should语句一个都不要求匹配,只有一个特例:如果查询中没有must语句,那么至少要匹配一个should语句
例子如下(查询company包含亿磐,且job为Senior Automation Testing Engineer ID43515的文档):
GET 51job/_doc/_search
{
"query": {
"bool":{
"must":[
{"match":{"company":"亿磐"}},
{"term":{"job":"Senior Automation Testing Engineer ID43515"}}
]
}
}
}结果如下:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 19.589294,
"hits" : [
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "xEeg-3MBrm2PQExGCcPD",
"_score" : 19.589294,
"_source" : {
"id" : 982,
"job" : "Senior Automation Testing Engineer ID43515",
"company" : "亿磐",
"place" : "深圳",
"salar" : "",
"data" : "12-13"
}
}
]
}
}
再来一个,查询job为Senior Automation Testing Engineer ID43515或Senior Software Engineer (Java) ID36192的文档:
GET 51job/_doc/_search
{
"query": {
"bool":{
"should":[
{"term":{"job":"Senior Software Engineer (Java) ID36192"}},
{"term":{"job":"Senior Automation Testing Engineer ID43515"}}
]
}
}
}结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 6.7971954,
"hits" : [
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "9Eeg-3MBrm2PQExGCb_A",
"_score" : 6.7971954,
"_source" : {
"id" : 4,
"job" : "Senior Software Engineer (Java) ID36192",
"company" : "亿磐",
"place" : "深圳",
"salar" : "",
"data" : "12-13"
}
},
{
"_index" : "51job",
"_type" : "_doc",
"_id" : "xEeg-3MBrm2PQExGCcPD",
"_score" : 6.7971954,
"_source" : {
"id" : 982,
"job" : "Senior Automation Testing Engineer ID43515",
"company" : "亿磐",
"place" : "深圳",
"salar" : "",
"data" : "12-13"
}
}
]
}
}完事儿!!!!弄清楚各种查询的匹配原理,还是很简单的吧。