BeautifulSoup_嵩天老师慕课学习笔记
导入 from bs4 import BeautifulSoup 对大小写敏感(还有DataFrame)
初始化(第一个参数是string形式的标签树,第二个参数是所用的解析器)
soup=BeautifulSoup("data","html.parser")
soup2=BeautifulSoup(open("D://demo.html"),"html.parser")
soup是Tag类型,name为[document]
解析器:bs4(安装bs4库)、lxml的HTML解析器(pip install lxml)、lxml的XML解析器(pip install xml)、html5lib解析器(pip install html5lib)
BeautifulSoup类的数据类型
Tag:标签,最基本的单位
Name:标签名,格式.name为tag
Attributes:标签属性,字典形式,格式.attrs
NavigableString:标签内非属性字符串,格式
Comment:标签内字符串的注释部分,特殊的Comment类型
import requests
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
demo = requests.get(url).text
soup = BeautifulSoup(demo,"html.parser")
#这里的soup即初始化一个BeautifulSoup里的document标签
print(soup.title)BeautifulSoup的属性和方法
初始化soup后,利用soup.tag即可获得soup里的tag标签,获取之后可以再利用tag.获取tag里的名字属性等。
Tag类型的属性
tag.a 获取tag内第一个a标签,又返回bs4.element.Tag类型
tag.attrs 获取soup里面第一个a标签的所有属性,返回一个字典。可以取字典里的内容!!(tag.attrs['href'])
tag.name 标签的名字 ,返回字符串
tag.parent 获取父级元素,返回Tag类型
tag.string 获取tag里的字符串,返回NavigableString类型。也可以获取注释的内容,返回Comment类型
tag.contents/.children/.descendants(具体看下行遍历) /.parents/.parent(上行遍历)/
tag = soup.a
tag.attrs #获取soup里面第一个a标签的所有属性,返回一个字典
#{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': link1'}
tag.name #返回'a'标签名
tag.parent #返回a的父级标签
tag.string #返回a中的文字
type(tag.string) #返回
tag.attrs['href'] #获取上一条代码返回字典里的具体属性值
#'http://www.icourse163.org/course/BIT-268001' Tag类型的方法
tag.prettify() 美化输出tag的html代码
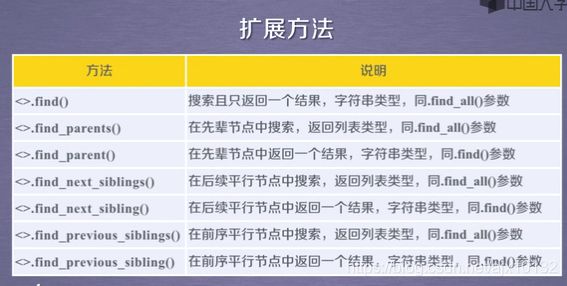
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个list类型,存储查找结果
name:字符串类型,对标签名进行限制。可以使用list进行多个标签的查找
attrs:对标签属性值进行限制
recursive:是否对子孙全部检索,默认为True。False为只搜索儿子
string:标签内的文字的检索字符串
由于find_all()太常用,可以有简写形式,tag()等价于tag.find_all()
soup.find_all('a') #获取所有a标签,返回一个存储所有a标签的列表
#[Basic Python, Advanced Python]
soup.find_all(['a','b']) #获取所有a,b标签,返回值为一个list,顺序按照原文档形式,即此式等同于find_all(['b','a'])
soup.find_all('p','course') #获取class为course的p标签,返回值为List
soup.find_all(id='link1') #获取id=link1的标签,返回值为List
soup.find_all(string="Basic Python") #获取标签内容文字,返回列表字符串
import re
for tag in soup.find_all(re.compile('b')):
print(tag.name)
#返回所有标签名含b的标签,例如body也会被返回
soup.find_all(id=re.compile('link'))
#返回id包含link的标签
soup.find_all(string=re.compile('python')) #获取标签内容含python的文字,返回listBeautifulSoup遍历的方法
下行遍历
.contents 返回子节点的列表,将tag所有儿子结点存入列表
.children 返回子节点的迭代类型,与.contents类似
.descendants 返回子孙结点的迭代类型,包含所有的子孙结点
#遍历儿子结点
for child in soup.body.children:
print(child)
#遍历子孙结点
for child in soup.body.descendants:
print(child)上行遍历
.parent 结点的父亲标签
.parents 结点的父辈标签,返回迭代类型
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)平行遍历(亲兄弟,不包括堂兄弟,必须在同一个父亲节点下)
.next_sibling 返回下个平行结点
.previous_sibling 返回上个平行节点
.next_siblings 迭代类型,返回所有后续平行节点
.previous_siblings 迭代类型,返回所有前序平行节点
#后续结点遍历
for sibling in soup.a.next_siblings:
print(sibling)
#前续结点遍历
for sibling in soup.a.previous_siblings:
print(sibling)信息存储形式
xml最早的标记形式,可扩展性好。 注释
Tian
Song
中关村南大街5号
北京市
100001
Computer System Security
json信息有类型,适合程序处理
{
"firstName" : "Tian",
"lastName" : "Song",
"address" : {
"streetAddr" : "中关村南大街5号",
"city" : "北京市",
"zipcode" : "100001"
} ,
"prof" : ["Computer System" , "Security"]
}
//键值对形式组织信息,无论是键还是值,都需要添加双引号来表示
yaml信息无类型,文本信息比例高,可读性好。用于各种配置文件
用缩进表达所属关系,-表达并列关系,|表达整块数据,#表示注释
firstName : Tian
lastName : Song
address :
streetAddr :中关村南大街5号
city :北京市
zipcode :100001
prof :
-Computer System
-Security