关于 tensorflow 中的卷积&反卷积(以stargan-vc-tf代码为例)
在stargan-vc模型中,有比较经典的(卷积 & 反卷积)组合,综合参考了github上的implement代码https://github.com/hujinsen/StarGAN-Voice-Conversion
其中,编码者,在Generator部分,采用手动padding,之后采用
def conv2d_layer(inputs, filters, kernel_size, strides, padding: list = None, activation=None, kernel_initializer=None, name=None):
p = tf.constant([[0, 0], [padding[0], padding[0]], [padding[1], padding[1]], [0, 0]])
out = tf.pad(inputs, p, name=name + 'conv2d_pad')
"""关于tf.pad 的用法:
# https://blog.csdn.net/yy_diego/article/details/81563160"""
conv_layer = tf.layers.conv2d(
inputs=out,
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding='valid',
activation=activation,
kernel_initializer=kernel_initializer,
name=name)
return conv_layer来作为下采样卷积的函数;
仔细想来,其实也可以直接用 (‘SAME’模式)代替(‘VALID’+手动padding) 的方法,总的目标都是改变卷积尺寸,数据是一样的;
在查阅相关资料的时候(关于卷积&反卷积 尺寸计算的公式),做了一些笔记和整理:


卷积尺寸公式:https://blog.csdn.net/weixin_37697191/article/details/89527315
反卷积公式 2 :keras:
tf.keras.layers.Conv2DTranspose
tf.keras.layers.Conv2DTranspose(
filters, kernel_size, strides=(1, 1), padding='valid', output_padding=None,
data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs
)https://blog.csdn.net/coolsunxu/article/details/106317157?utm_medium=distribute.pc_relevant.none-task-blog-baidujs-8
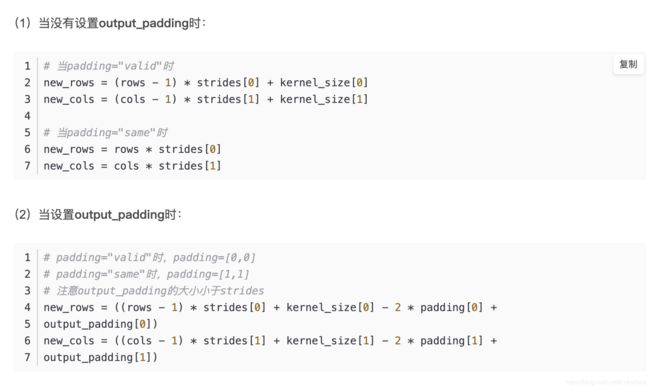
Ps.有一个小细节:我的tensorflow 是1.12,然后keras.layers.Conv2DTranspose()函数点进去,找不到 output_padding 这个参数:
def __init__(self,
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):可能是在超参数里面。不过这个没有影响使用,就默认当作是 None ,即padding规则由 tf 自己去推断即可;我们只要提供 padding模式、stride、kernels 几个重要参数即可,正如stargan-vc论文结构图中所示;
Ps. stargan-vc代码中,经过我自己验算,反卷积时,用‘VALID‘ 和 ’SAME’ 效果是一样的;
反卷积公式 1 :
tf.layers.conv2d_transpose
conv2d_transpose(
inputs,
filters,
kernel_size,
strides=(1, 1),
padding=’valid’,
data_format=’channels_last’,
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=tf.zeros_initializer(),
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None,
reuse=None
)几个供参考的文章:(排名分先后,重要性从高到低)
https://blog.csdn.net/sinat_29957455/article/details/85558870
https://blog.csdn.net/qq_42192910/article/details/89791539
https://blog.csdn.net/weiwei9363/article/details/78954063
这个函数是在查阅“反卷积“概念时遇到的,他和keras的接口不同的是,有一个 ‘output_shape‘参数,即,你要自己算一下想要的反卷积结果尺寸;这点在上面的一篇文章中有说到。实际原理就是,正向卷积的过程的尺寸计算公式:往上面查看;是一个向上取整的规则,所以就有了小数的概念,所以就有了多种反卷积可能;
而这个尺寸设定问题,在keras函数中,并不是特别需要:因为你看一下上面的keras反卷积函数尺寸计算公式,他用的是stride、kernels、padding参数,以及原始输入的 rows、cols参数。
应该说,是两套计算体系;其中必然有原理的相似性,但是公式验算上,咱们先知道两个的区别比较重要;
反卷积其实不用想太多,也不用管 tf 内部具体是怎么做的padding,只要记住,反卷积 是 卷积的逆过程,(虽然数据不能完全恢复);所以,验算时 / 设置具体时,可以先根据卷积之前的数据作为输入,再代入卷积公式计算一下反卷积需要的相关参数,就ok了;
值得一提的是,有博客文章作者提到,卷积和反卷积是成对完成任务:即,不应该让卷积两次后的高维抽象,只经过一次反卷积就试图代表最原始维度数据(此时还是第一层维度的数据表示);先理解这个理念,不过分钻牛角尖了(钻了也没确切答案可以搜到);
下面这段是 stargan-vc中的上采样环节的(反卷积 + InstantNoem + GLU(gated_linear_unit) );
def upsample2d_block(inputs, filters, kernel_size, strides, name_prefix='upsample2d_block_'):
# u2 = upsample2d_block(u1_concat, 128, [3, 5], [1, 1], name_prefix='gen_up_u2')
# tf.layers.batch_normalization()
# t1=tf.layers.Conv2DTranspose(filters,kernel_size,strides, padding='same',name=name_prefix+'conv1')(inputs)
# t1 = tf.layers.batch_normalization()
t1 = tf.keras.layers.Conv2DTranspose(filters, kernel_size, strides, padding='same')(inputs)
# t2 = tf.keras.layers.BatchNormalization()(t1)
t2 = tf.contrib.layers.instance_norm(t1, scope=name_prefix + 'instance1')
x1_gates = tf.keras.layers.Conv2DTranspose(filters, kernel_size, strides, padding='same')(inputs)
# x1_norm_gates = tf.keras.layers.BatchNormalization()(x1_gates)
x1_norm_gates = tf.contrib.layers.instance_norm(x1_gates, scope=name_prefix + 'instance2')
x1_glu = gated_linear_layer(t2, x1_norm_gates)
return x1_glu
谈到这里,就还有一些其他要笔记的:TF中的 BatchNorm(查到有四个可用接口),以及 InstantNorm();然后看到很多博客中谈到了 BN 中的“坑”:
1.TensorFlow 中 Batch Normalization API 的一些坑
https://blog.csdn.net/u014061630/article/details/85104491
2.tensorflow batch_normalization的正确使用姿势
https://blog.csdn.net/computerme/article/details/80836060
3.BN(Batch Normalization) 原理与使用过程详解
https://blog.csdn.net/donkey_1993/article/details/81871132?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
4.tensorflow的batch_normlization踩坑记录
https://blog.csdn.net/Jum_Summer/article/details/103315480
5.解决TensorFlow中Batch Normalization参数没有保存的问题
https://www.jianshu.com/p/cb8ebcee1b15
6.【PyTorch】详解pytorch中nn模块的BatchNorm2d()函数
https://blog.csdn.net/bigFatCat_Tom/article/details/91619977
stargan-vc是做的风格转移,所以一般在做Norm的时候,采用IN(或Adaptive_IN,在图像中用的);
在tf中的IN貌似没有过程参数训练的问题,没有相关的“踩坑文章”,Github上看别人的代码中,也没有BN的这些操作;
反倒是在看github上别人写的BN代码,有挺多并没有调用Updata_ops(来自https://blog.csdn.net/u014061630/article/details/85104491)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = tf.train.AdamOptimizer(lrn_rate).minimize(cost)
记住这个潜在的坑,上手写写代码试试
以上,是这两天整理代码遇到的问题小结;
To do list:
把VCC2020的训练过程做一个小结;