RNN 教程-part4,用python实现LSTM/GRU
本文翻译自
代码在Github上
这是Part4 ,RNN教程的最后一部分;
在这一部分,主要学习LSTM神经网络和GRU。LSTM在1997年首次提出,几乎是最流行的用于自然语言处理的深度学习模型。GRUs在2014年首次提出,是LSTMs的简单变体。让我们关注LSTMs,再看看GRUs有什么不同。
LSTM NETWORKS
前面提到,梯度消失问题能够阻止标准RNNs学习长距离的依赖关系。LSTMs通过门控机制来克服梯度消失。为了理解其中的含义,让我们看看LSTM是如何计算隐含层状态St.
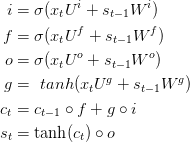
这些等式看起来相当的复杂,但是比更不像想象中的那么难。首先,注意LSTM层仅仅是计算隐含层状态的另一种方法;之前我们使用![]() 来计算隐含层状态;模块的输入为xt,当前的输入处于第t步,s(t-1)是上一步的状态。输出是新的隐含层状态;
来计算隐含层状态;模块的输入为xt,当前的输入处于第t步,s(t-1)是上一步的状态。输出是新的隐含层状态;
LSTM单元做了同样的事情,只是方式不同。理解下面的图是关键;你可以把LSTM单元当作黑箱来对待,根据当前的输入和之前的隐含层状态,计算下一个隐含层状态;

让我们有个直觉的感受:LSTM 是如何计算隐含层状态的;相关博客
这里做简单的解释,读上述博客能够更深入的理解和好的可视化。但是,总结如下:
尤其是,在基本的LSTM框架下存在一些变体。一个通常的做法是构建窥视孔链接,它允许门不仅仅依赖于之前的隐含层状态St-1,而且依赖于先前的内部状态Ct-1,在门等式上添加一个新项;这里有很多变体,https://arxiv.org/pdf/1503.04069.pdf“>这篇文章评价了不同的LASTM架构;
GRUS
GRU层背后的思想和LSTM层背后的思想相似,等式如下:
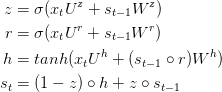
GRU有两个门,一个重置门r和一个更新门,直观的,重置门决定了如何把新的输入与之前的记忆相结合,更新门决定多少先前的记忆起作用。如果我们把所有reset设置为全1,更新门设置为全0,又达到了普通RNN的形式;使用一个门机制学习长距离依赖的基本思想与LSTM相同,但是有如下不同点:
GRU有两个门 ,LSTM有三个门;
GRU不能处理
输入和遗忘门能够被更新门z耦合,重置门r能够直接应用于之前的隐含状态。因此,重置门的职责在LSTM中被拆分为r和z;
计算输出时不应用第二非线性函数;
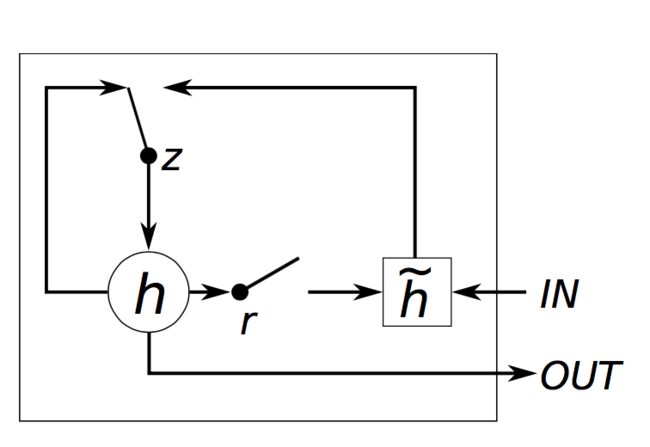
GRU VS LSTM
现在,有两个模型来解决梯度消失的问题,哪个更有效呢?GRUs相当的新,对它的评价没有被完全的探索;根据经验进行评价,相关文章http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf“>part1,part2没有明确的胜利者。在许多任务中,两个模型能产生相当的表现,看起来选择像层数这样的超参数相比与选择框架更重要。GRUs拥有更少的参数,可能训练的更快些或需要更少的数据来训练;如果你有足够多的数据,具有更强的表达能力的LASTs可能导致更好的结果
IMPLEMENTATION
让我们转向part2所述语言模型的实现,让我们在RNN中使用GRU单元,没有原则性的原因为什么使用GRUs而不是用LSTMs.
他们的实现几乎是完全相同的,所以可以把GRU中的代码很容易的转化为LSTM中的代码,仅仅需要改变几个等式;
以前面的Theano实现为代码基础,记得GRU(LSTM)层仅仅计算隐含层状态的另一种方式。因此,所有需要做的就是改变在我们的前向传播方法中隐含层状态的计算
def forward_prop_step(x_t, s_t1_prev):
# This is how we calculated the hidden state in a simple RNN. No longer!
# s_t = T.tanh(U[:,x_t] + W.dot(s_t1_prev))
# Get the word vector
x_e = E[:,x_t]
# GRU Layer
z_t1 = T.nnet.hard_sigmoid(U[0].dot(x_e) + W[0].dot(s_t1_prev) + b[0])
r_t1 = T.nnet.hard_sigmoid(U[1].dot(x_e) + W[1].dot(s_t1_prev) + b[1])
c_t1 = T.tanh(U[2].dot(x_e) + W[2].dot(s_t1_prev * r_t1) + b[2])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev
# Final output calculation
# Theano's softmax returns a matrix with one row, we only need the row
o_t = T.nnet.softmax(V.dot(s_t1) + c)[0]
return [o_t, s_t1]在我们的实现中,我们加入了偏置单元b,c;这相当的典型以至于没在等式中展现。当然,我们需要改变我们的参数U和W的初始化,因为他们现在有不同的size.
初始化代码没有展示,但是在Github中,我还加入字嵌入层E,
这是相当的简单。但是梯度怎么样?我们能够通过链式法则得到E,W,U,b,和c的梯度,就像之前做的一样,但是在实际中,大多人使用像支持表达式自动分划的theano这样的库。如果出于某种原因,自己计算梯度,你跟可能是因为想模快化不同的单元,生成运用链式规则进行自动分化的不同版本;下面是theano计算梯度:
# Gradients using Theano
dE = T.grad(cost, E)
dU = T.grad(cost, U)
dW = T.grad(cost, W)
db = T.grad(cost, b)
dV = T.grad(cost, V)
dc = T.grad(cost, c)为了得到更好的结果,在我们的实现中,我们使用了额外的技巧
使用RMSPROP进行参数更新(USING RMSPROP FOR PARAMETER UPDATES)
在part2我们使用了随机梯度下降法的基础版本进行参数更新。这证明不是个好的方案,如果设置学习率足够低的话,SGD能够保证向一个好的解决方案取得进展,但是在实际中会花费很长时间。存在很多通用的SGD变体。包括:http://101.96.8.164/www.cs.toronto.edu/~fritz/absps/momentum.pdf“> (Nesterov) Momentum Methodhttp://www.magicbroom.info/Papers/DuchiHaSi10.pdf“>AdaGrad等等;
这个博客介绍了许多这些函数的概述,
在我们的教程中,选择rmsprop,rmsprop背后的基本思想是根据先前梯度的和来调整学习率per-parameter。直观的 ,它意味着频繁出现的特征得到更小的学习率(因为它的梯度的和将会更大),稀有的特征得到更大的学习率;
rmsprop的实现相当的简单;对于每个参数,有一个缓存变量。
在梯度下降时,我们更新参数和此变量;
cacheW = decay * cacheW + (1 - decay) * dW ** 2
W = W - learning_rate * dW / np.sqrt(cacheW + 1e-6)衰退典型的被设置为0.9或0.95,1e-6 是为了避免0的出现;
加入嵌入层(ADDING AN EMBEDDING LAYER)
使用例如word2vect和GloVe单词嵌入是一个流行的方法提高我们精度。代替使用one-hot vector来表达单词,使用word2vec或GloVe学习得到的携带语义的低维向量(形似的单词具有相似的向量),使用这些向量是训练前预处理的一种方式,直观的,能够告诉神经网络那些单词是相似的,以至于需要更少的学习语言;在你没有大量数据的时候,使用预训练向量很有效,因为它允许神经网络推广到没有见过的单词。我没有使用过预处理单词向量,但是加入一个嵌入层使它们更容易的插入进来;嵌入矩阵(E)就是一个查找表。第i列向量对应于我们的单词表中的第i个单词;
通过更新E进行单词的向量表示的学习更新;但是,这与我们的特殊任务相关,并不是可以下载使用大量文档寻训练的模型进行通用;
添加第二个GRU层(ADDING A SECOND GRU LAYER)
在神经网络中,加入第二层能够使我们的模型捕捉到更高水平相互作用;你能够加入额外的层;你将会发现在2-3层之后,结果会衰退,除非你拥有大量的数据,更多的层次不太可能造成大的差异,可能导致过拟合;

向我们的神经网络中添加第二层是简单的,我们仅仅需要修改前向传播计算和初始化函数;
# GRU Layer 1
z_t1 = T.nnet.hard_sigmoid(U[0].dot(x_e) + W[0].dot(s_t1_prev) + b[0])
r_t1 = T.nnet.hard_sigmoid(U[1].dot(x_e) + W[1].dot(s_t1_prev) + b[1])
c_t1 = T.tanh(U[2].dot(x_e) + W[2].dot(s_t1_prev * r_t1) + b[2])
s_t1 = (T.ones_like(z_t1) - z_t1) * c_t1 + z_t1 * s_t1_prev
# GRU Layer 2
z_t2 = T.nnet.hard_sigmoid(U[3].dot(s_t1) + W[3].dot(s_t2_prev) + b[3])
r_t2 = T.nnet.hard_sigmoid(U[4].dot(s_t1) + W[4].dot(s_t2_prev) + b[4])
c_t2 = T.tanh(U[5].dot(s_t1) + W[5].dot(s_t2_prev * r_t2) + b[5])
s_t2 = (T.ones_like(z_t2) - z_t2) * c_t2 + z_t2 * s_t2_prev有关性能
有很多技巧来优化RNN性能,但是最重要的一个可能是批量处理你的更新。一次不仅仅学习一句话,可以把同等长度的句子聚集在一起,然后执行大的矩阵相乘,把整个集合的梯度相加;这是因为大的矩阵相乘在GRU中很高效处理。如果不这样,使用GPU只能获得少量的性能优化,训练将会非常慢;
所以,如果你想训练大的模型,我建议使用现存的深度学习库深度学习库链接,它们进行了性能优化;上面的代码要花费数天训练的模型,使用这些库只需要花费几个小时;
个人喜欢Keras,它使用简单,而且带有好的例子;
结果(RESULTS)
为了避免花费数天训练一个模型的痛苦经历,我训练了一个和Part2中相似的模型。我使用了大小为8000的单词表。把单词映射到48维的向量,使用两层128维的GRU层。
源码中包括加载模型的代码,可以修改模型,使用模型来生成文本;
这里有神经网络生成的文本的示例:
I am a bot , and this action was performed automatically .
I enforce myself ridiculously well enough to just youtube.
I’ve got a good rhythm going !
There is no problem here, but at least still wave !
It depends on how plausible my judgement is .
( with the constitution which makes it impossible )
很兴奋能够看出这些句子中跨越多个单词之间的语义相关;例如,