AlexNet-Pytorch-Kaggle猫狗大战
前言
前一段时间基于LeNet-5实现了MNIST手写数字识别,由于torchvision.datasets模块集成了MNIST数据集,所以在加载数据时使用的是torchvision.datasets自带的方法,缺失了如何对一般数据集的处理部分,不能将其作为一个模板来适用于新的网络。通常,我们需要为待处理的数据集定义一个单独的数据处理类,在本文中,将基于AlexNet来实现猫狗分类,并详细总结各个部分。对于我自己来说,在后面适用新的网络时,希望能够以此次的代码作为一个模块,增加效率,这也是写这篇博客的目的所在。
相关数据下载地址
AlexNet论文地址:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)
项目地址:https://github.com/myCigar/cat_vs_dog-AlexNet
数据下载地址:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data
AlexNet网络构建
AlexNet由Hinton和他的学生Alex Krizhevsky在2012年所提出,并在当年的ImageNet竞赛中获得了冠军,在论文中还提出了ReLu,Dropout,LRN等用于优化网络的功能,ReLu激活函数加快了训练的速度,Dropout可以有效的防止过拟合,LRN对数据进行了归一化处理。
AlexNet网络结构如下:
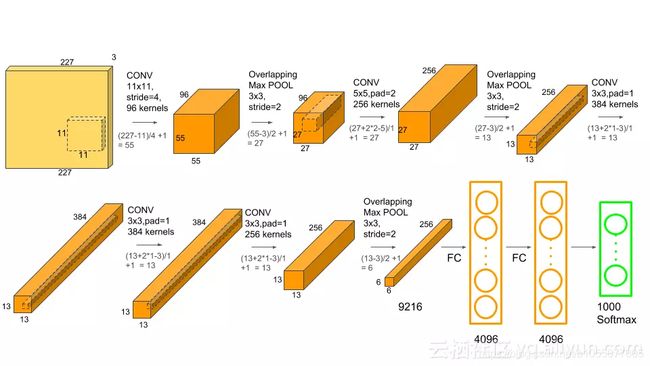
| input_size | out_size | kernel | stride | padding | |
|---|---|---|---|---|---|
| 卷积层1 | [3, 227, 227] | [96, 55, 55] | (11, 11) | 4 | 0 |
| 池化层1 | [96, 55, 55] | [96, 27, 27] | (3, 3) | 2 | 0 |
| 卷积层2 | [96, 27, 27] | [256, 27, 27] | (5, 5) | 1 | 2 |
| 池化层2 | [256, 27, 27] | [256, 13, 13] | (3, 3) | 2 | 0 |
| 卷积层3 | [256, 13, 13] | [384, 13, 13] | (3, 3) | 1 | 1 |
| 卷积层4 | [384, 13, 13] | [384, 13, 13] | (3, 3) | 1 | 1 |
| 卷积层5 | [384, 13, 13] | [256, 13, 13] | (3, 3) | 1 | 1 |
| 池化层3 | [256, 13, 13] | [256, 6, 6] | (3, 3) | 2 | 0 |
| 全连接层1 | 256 * 6 * 6 | 4096 | — | — | — |
| input_size | out_size | kernel | stripe | padding | |
|---|---|---|---|---|---|
| 全连接层2 | 4096 | 4096 | — | — | — |
| 全连接层3 | 4096 | 1000 | — | — | — |
计算输出时,有一个非常重要的公式:
y = x − k + 2 p s + 1 y= \frac{x-k+2p}{s} + 1 y=sx−k+2p+1
- y:输出尺寸大小
- x:输入尺寸大小
- k:卷积核大小
- p:填充数
- s:步长
构建网络模型
import torch.nn as nn
import torch.nn.functional as F
# 局部响应归一化
class LRN(nn.Module):
def __init__(self, local_size=1, alpha=1.0, beta=0.75, ACROSS_CHANNELS=True):
super(LRN, self).__init__()
self.ACROSS_CHANNELS = ACROSS_CHANNELS
if ACROSS_CHANNELS:
self.average=nn.AvgPool3d(kernel_size=(local_size, 1, 1),
stride=1,
padding=(int((local_size-1.0)/2), 0, 0))
else:
self.average=nn.AvgPool2d(kernel_size=local_size,
stride=1,
padding=int((local_size-1.0)/2))
self.alpha = alpha
self.beta = beta
def forward(self, x):
if self.ACROSS_CHANNELS:
div = x.pow(2).unsqueeze(1)
div = self.average(div).squeeze(1)
div = div.mul(self.alpha).add(1.0).pow(self.beta)
else:
div = x.pow(2)
div = self.average(div)
div = div.mul(self.alpha).add(1.0).pow(self.beta)
x = x.div(div)
return x
# conv
# out_size = (in_size - kernel_size + 2 * padding) / stride
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
# conv
self.conv1 = nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0)
self.conv2 = nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2)
self.conv3 = nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1)
self.conv5 = nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1)
# LRN
self.LRN = LRN(local_size=5, alpha=0.0001, beta=0.75)
# FC
self.fc1 = nn.Linear(256*6*6, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 2)
# Dropout
self.Dropout = nn.Dropout()
def forward(self, x):
# conv1 -> relu -> maxpool1
# conv1: [n, 3, 227, 227] --> [n, 96, 55, 55]
# maxpool1: [n, 96, 55, 55] --> [n, 96, 27, 27]
x = F.relu(self.conv1(x))
x = self.LRN(x)
x = F.max_pool2d(x, (3, 3), 2)
# conv2 -> relu -> maxpool2
# conv2: [n, 96, 27, 27] --> [n, 256, 27, 27]
# maxpool2: [n, 256, 27, 27] --> [n, 256, 13, 13]
x = F.relu(self.conv2(x))
x = self.LRN(x)
x = F.max_pool2d(x, (3, 3), 2)
# conv3 -> relu -> conv4 -> relu
# oonv3: [n, 256, 13, 13] --> [n, 384, 13, 13]
# conv4: [n, 384, 13, 13] --> [n, 384, 13, 13]
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
# conv5 -> relu -> maxpool3
# conv5: [n. 384, 13, 13] --> [n, 256, 13, 13]
# maxpool3: [n, 256, 13, 13] --> [n, 256, 6, 6]
x = F.relu(self.conv5(x))
x = F.max_pool2d(x, (3, 3), 2)
# need view first for conv --> FC
x = x.view(x.size()[0], -1)
# fc1 -> fc2 -> fc3 -> softmax
# fc1: 256*6*6 --> 4096
# fc2: 4096 --> 4096
# fc3: 1000 --> 2
x = F.relu(self.fc1(x))
x = self.Dropout(x)
x = F.relu(self.fc2(x))
x = self.Dropout(x)
x = self.fc3(x)
x = F.softmax(x)
return x
由于本次实验是一个二分类问题,所以将最后一个全连接层的输出个数由1000改成2即可。
Transforms数据预处理
transforms定义了对数据进行怎样的预处理,但数据的预处理并不在这里实现,通常将transforms作为一个参数传入自定义的数据集类,并在__ getitem __方法中实现数据的预处理。
pre_transforms = transforms.Compose([
transforms.Resize((227, 227)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
自定义数据集类
代码如下:
class CatDogDataset(data.Dataset):
def __init__(self, args, mode='train', transform=None):
self.args = args
self.transform = transform
self.mode = mode
self.names = self.__dataset_info()
def __getitem__(self, index):
x = imread(self.args.data_path + "/" + self.names[index], mode='RGB') # numpy
x = Image.fromarray(x) # PIL
x_label = 0 if 'cat' in self.names[index] else 1
if self.transform is not None:
x = self.transform(x)
return x, x_label
def __len__(self):
return len(self.names)
# 取train中前500张的猫和狗图片为测试集,所以一共有1000张测试集,24000张训练集
def __dataset_info(self):
img_path = self.args.data_path
imgs = [f for f in os.listdir(img_path) if
os.path.isfile(os.path.join(img_path, f)) and f.endswith('.jpg')]
names = []
for name in imgs:
index = int(name.split('.')[1])
# train dataset
if self.mode == 'train':
if index >= 500:
names.append(name)
# test dataset: 1000 imgs
elif self.mode == 'test':
if index < 500:
names.append(name)
return names
在类中,必须实现**__ init __ ** ,__ getitem __ ,__ len __ 三个方法。
在定义好了我们的数据集类之后,需要对该类进行实例化:
# get datasets
train_dataset = CatDogDataset(args, 'train', pre_transforms)
test_dataset = CatDogDataset(args, 'test', pre_transforms)
# print the length of train_dataset
print('train:{} imgs'.format(len(train_dataset)))
DataLoader
接下来要通过Pytorch自带的DataLoader来得到一个Loader对象,该对象可以通过for … in …进行迭代,每一次迭代的结果就是数据集类__ getitem __ 方法返回的值。
# generate DataLoader
train_loader = DataLoader(train_dataset, args.batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, 1, shuffle=False)
使用GPU加速
个人推荐使用device的方式对Tensor进行GPU处理,因为这样无论电脑是否安装了CUDA+CuDNN都能不改任何代码成功运行,同时如果需要在另一张显卡上运行,只需要修改一个数字即可,很方便。
# GPU,如需指定显卡,只需要将0改成要指定的显卡的对应序号即可。
if args.without_gpu:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("use CPU !")
else:
if torch.cuda.is_available():
device = torch.device("cuda")
print("use GPU !")
else:
print("No GPU is available !")
alexnet = AlexNet()
base_epoch = 0
if args.load:
model_path = './checkpoints/99_loss_0.523277.pth'
alexnet.load_state_dict(torch.load(model_path)['alexnet'])
base_epoch = torch.load(model_path)['epoch']
# 转换到GPU环境
alexnet.to(device)
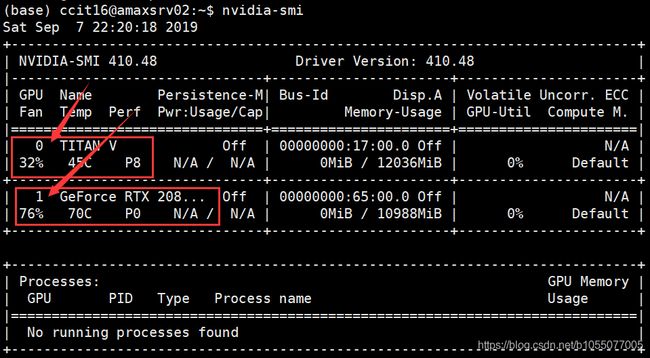
下图显示了一台服务器上的显卡信息,可以看到图中有两张显卡,其序号分别是0和1,如需使用第二张显卡,只需要将"cuda:0"改成"cuda:1"就可以了。
损失函数与优化方法
本次实验,使用了交叉熵作为损失函数,随机梯度下降法SGD作为优化方法
# loss and optim function
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(alexnet.parameters(),
lr=args.lr, momentum=0.9, weight_decay=5e-4)
迭代,对数据进行处理
首先我们需要将每次迭代生成的信息to到相应的GPU设备上,然后进行常规化处理:预测得到标签,梯度清0,计算损失值,将损失值反向传播并进行优化,代码如下:
for epoch in range(args.epochs):
alexnet.train()
epoch += base_epoch
epoch_loss = 0
for idx, (imgs, labels) in enumerate(train_loader):
imgs, labels = imgs.to(device), labels.to(device)
pre_labels = alexnet(imgs)
optimizer.zero_grad()
loss = criterion(pre_labels, labels.long())
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print('[{}/{}][{}/{}] loss:{:.4f}'
.format(epoch+1, args.epochs, idx+1, int(len(train_dataset) / args.batch_size), loss.item()))
# save model
aver_loss = epoch_loss * args.batch_size / len(train_dataset)
state = {
'epoch': epoch,
'alexnet': alexnet.state_dict()
}
acc = eval(alexnet, test_loader, test_dataset, device)
save_model(state, './checkpoints', '{}_{:.6f}_{:.3f}.pth'.format(epoch, aver_loss, acc))
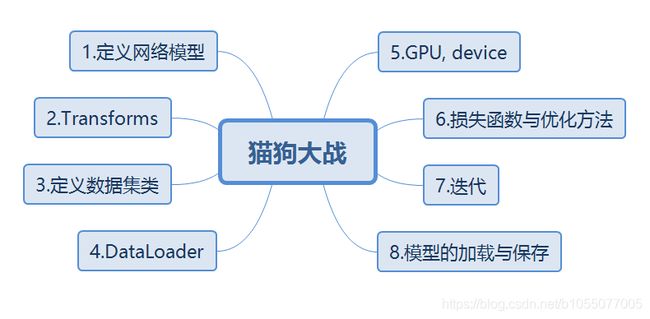
以上就是训练一个神经网络的基本流程,下面通过一张图对这几部分进行整理。
THE END
