机器学习——隐马尔科夫(HHM)原理
机器学习——隐马尔科夫(HHM)模型原理
1 从马尔科夫模型到隐马尔科夫模型
1.1 马尔科夫过程引入
首先,我们先给出一张图:

在上面的图里,给出的是一个链式的结构,结构中的每一个节点称之为一个状态。每一个状态 Q i Q_i Qi的取值是一个范围 [ S 0 , S n ] [S_0,S_n] [S0,Sn],我们称之为状态空间。并且,每一个状态 Q i Q_i Qi的取值与之前状态的取值有关。也就是说 Q i Q_i Qi在状态空间的和 Q 1 , Q 2 , . . Q i − 1 Q_1,Q_2,..Q_{i-1} Q1,Q2,..Qi−1的取值有关。我们将这种状态随着时间向前推进,状态的取值与之前状态的取值有关的过程称为马尔科夫随机过程。我们用概率来表示一下这个过程就是:
P ( Q i = S i ) = P ( Q i = S j ∣ Q 1 = S i ∈ [ S 0 , S n ] , Q 2 = S i ∈ [ S 0 , S n ] , . . . , Q i − 1 = S i ∈ [ S 0 , S n ] ) P(Q_i=S_i)=P(Q_i=S_j|Q_1=S_i∈[S_0,S_n],Q_2=S_i∈[S_0,S_n],...,Q_{i-1}=S_i∈[S_0,S_n]) P(Qi=Si)=P(Qi=Sj∣Q1=Si∈[S0,Sn],Q2=Si∈[S0,Sn],...,Qi−1=Si∈[S0,Sn])
其中 Q i − 1 = S i ∈ [ S 0 , S n ] Q_{i-1}=S_i∈[S_0,S_n] Qi−1=Si∈[S0,Sn]表示状态 Q i Q_i Qi的取值 S i S_i Si属于样本空间的某一个。现在我们做出一个强假设,假设当前状态的取值仅仅和前一个状态的取值有关。用公式表示就是:
P ( Q i = S i ) = P ( Q i = S j ∣ Q i − 1 = S i ∈ [ S 0 , S n ] ) P(Q_i=S_i)=P(Q_i=S_j|Q_{i-1}=S_i∈[S_0,S_n]) P(Qi=Si)=P(Qi=Sj∣Qi−1=Si∈[S0,Sn])
我们将其称为一阶马尔科夫过程。如果状态空间 S i S_i Si是离散的值,我们就称其为离散的一阶马尔科夫过程。
或许上面的描述过于抽象化,下面我们举一个例子来解释这个过程,假设有如下三个状态和状态转移矩阵:
首先,我们假设状态空间为 [ S 1 , S 2 , S 3 ] [S_1,S_2,S_3] [S1,S2,S3]
状态S1:名词(N)
状态S2:动词(V)
状态S3:形容词(adj)
假设状态 Q 1 Q_1 Q1的取值为 S 1 S_1 S1,状态 Q 2 Q_2 Q2的取值为 S 2 S_2 S2,状态 Q 3 Q_3 Q3的取值为 S 3 S_3 S3,状态 Q 4 Q_4 Q4的取值为 S 3 S_3 S3,那么我们现在要确定 Q 5 Q_5 Q5为状态的 S 1 S_1 S1的概率就是:
P ( Q 5 = S 1 ) = P ( Q 5 = S j ∣ Q 1 = S 1 , Q 2 = S 2 , Q 3 = S 3 , Q 4 = S 3 ) P(Q_5=S_1)=P(Q_5=S_j|Q_1=S_1,Q_2=S_2,Q_{3}=S_3,Q_4=S_3) P(Q5=S1)=P(Q5=Sj∣Q1=S1,Q2=S2,Q3=S3,Q4=S3)
下面,我们在具有给出一个状态转移的矩阵
[ S 1 S 2 S 3 S 1 0.3 0.5 0.2 S 2 0.5 0.3 0.2 S 3 0.4 0.2 0.4 ] \left[ \begin{matrix} &S_1&S_2&S_3\\ S_1&0.3 & 0.5 & 0.2 \\ S_2&0.5 & 0.3 & 0.2\\ S_3&0.4 & 0.2 & 0.4 \\ \end{matrix} \right] ⎣⎢⎢⎡S1S2S3S10.30.50.4S20.50.30.2S30.20.20.4⎦⎥⎥⎤
转移矩阵的概念是,从某一个状态 S i S_i Si转移到另外一个状态 S j S_j Sj的概率。在我们上面的式子中:
P ( Q 5 = S j ) = P ( Q 5 = S j ∣ Q 1 = S 1 , Q 2 = S 2 , Q 3 = S 3 , Q 4 = S 3 ) P(Q_5=S_j)=P(Q_5=S_j|Q_1=S_1,Q_2=S_2,Q_{3}=S_3,Q_4=S_3) P(Q5=Sj)=P(Q5=Sj∣Q1=S1,Q2=S2,Q3=S3,Q4=S3)
假设 Q 1 Q_1 Q1状态的是确定的 S 1 S_1 S1,那么从状态值 S 1 S_1 S1转移的到 Q 2 Q_2 Q2对应的状态值 S 2 S_2 S2的概率为0.5,同理从 S 2 S_2 S2转移到 Q 3 Q_3 Q3状态的状态值 S 3 S_3 S3的概率为0.2,从 S 3 S_3 S3转移到 Q 4 Q_4 Q4状态的状态值 S 3 S_3 S3的概率为0.4,则
P ( Q 5 = S 1 ) = P ( Q 5 = S j ∣ Q 1 = S 1 , Q 2 = S 2 , Q 3 = S 3 , Q 4 = S 3 ) = 0.5 ∗ 0.2 ∗ 0.4 P(Q_5=S_1)=P(Q_5=S_j|Q_1=S_1,Q_2=S_2,Q_{3}=S_3,Q_4=S_3)\\ =0.5*0.2*0.4 P(Q5=S1)=P(Q5=Sj∣Q1=S1,Q2=S2,Q3=S3,Q4=S3)=0.5∗0.2∗0.4
如果是一阶马尔科夫过程,并且已经确定了 Q 4 = S 3 Q_4=S_3 Q4=S3,则可以确定概率为:
P ( Q 5 = S j ) = P ( Q 5 = S j ∣ Q 4 = S 3 ) = 0.4 P(Q_5=S_j)=P(Q_5=S_j|Q_4=S_3)=0.4 P(Q5=Sj)=P(Q5=Sj∣Q4=S3)=0.4
1.2、 隐马尔科夫模型
在上述马尔科夫模型中,每一个状态的代表的是一个可以直接观察的事件(比如,上面的每个状态对应的是一个的词性)。在隐马尔科夫模型中,我们不能知道模型所经过的状态序列,只知道状态转移的概率函数。同时,对于这个状态所产生的事件也是一个随机的函数。还是上面的例子。现在已知的是状态S1,S2,S3转移的概率。但是对于每一个状态的Si,其可以产生多个多种词性。即
状态S1:名词(N)、动词(V)、形容词(A)
状态S2:名词(N)、动词(V)、形容词(A)
状态S3:名词(N)、动词(V)、形容词(A)
HMM的转移过程如图所示:

在这里,我们把由各个状态产生的实际O称为可观测序列。
在HMM模型中,当计算到某一个事件序列产生的概率的时候,我们至少需要到三个部分,第一个部分是初始状态的概率,第二个是状态之间转移的概率,第三个是有状态产生事件的概率。对于以上三个部分,我们分别使用 π , A , B π,A,B π,A,B三个矩阵来表示。那么也就是说,一个常规的隐马尔科夫练可以表示为:
{ π , A , B } \{π,A,B\} {π,A,B}
2 HMM模型推导过程
对于HMM模型的求解过程,通常是从三个问题开始的,我们下面分别对这三个问题进行一一的推导和求解。
2.1 估计问题
2.1.1 问题描述
给定一个观察序列 O = { O 1 , O 2 , . . . O T } O=\{O_1,O_2,...O_T\} O={O1,O2,...OT}和HMM模型 μ = { π , A , B } μ=\{π,A,B\} μ={π,A,B},如何计算观察序列O的概率?
对于这个问题,首先我们要明确的是对于每一个可以观测的数据而言,其可以用任何一个状态Si来生成。
2.1.2 问题推导
对于第一个可以观测的数据 O 1 O_1 O1而言,整个模型生成 O 1 O_1 O1的概率是各个状态生成 O 1 O_1 O1的概率之和。也就是 ∑ Q 1 = S 1 S p b Q 1 ( j ) ∑_{Q_1=S_1}^{S_{p}}b_{Q_1}(j) ∑Q1=S1SpbQ1(j),同时由于模型是以一定的概率来生成初始状态 Q 1 Q_1 Q1的,那么也就是说,整个模型生成第一个可观测元素的概率为:
P ( O 1 ∣ μ ) = ∑ Q 1 = S 1 S p π ( Q 1 ) ∗ B Q 1 ( O 1 ) P(O_1|μ)=∑_{Q_1=S_1}^{S_{p}}π(Q_1)*B_{Q_1}(O_1) P(O1∣μ)=Q1=S1∑Spπ(Q1)∗BQ1(O1)
对于可观测序列的第二个元素 O 2 O_2 O2而言,首先是由第一个状态 Q 1 Q_1 Q1转移到第二个状态 Q 2 Q_2 Q2,在有状态 Q 2 Q_2 Q2来生成的。由于状态 Q 2 Q_2 Q2的取值范围是 { S 0 , S 1 , . . . S p − 1 } \{S_0,S_1,...S_{p-1}\} {S0,S1,...Sp−1},那么,有状态 Q 2 Q_2 Q2生成可以观测的元素 O 2 O_2 O2的概率就是各个状态生成 O 2 O_2 O2的概率和,用数学表达式表示就是:
∑ Q 2 = S 1 S p b Q 2 ( j ) ∑_{Q_2=S_1}^{S_{p}}b_{Q_2}(j) Q2=S1∑SpbQ2(j)。
同时,我们还需要考虑到的时, Q 2 Q_2 Q2是由 Q 1 Q_1 Q1转移过来的。那么,我们就必须要考虑到状态转移的概率。对于 Q 2 Q_2 Q2状态的任意一个取值 S i S_i Si而言,产生这个状态的概率是由 Q 1 Q_1 Q1的任意一个取值产生的,那么模型产生 S i S_i Si的概率,就为:
∑ Q 1 = S 1 S p π ( Q 1 ) A Q 1 S i ∑_{Q_1=S_1}^{S_{p}}π(Q_1)A_{Q_1S_i} Q1=S1∑Spπ(Q1)AQ1Si
则,由状态 Q 1 Q_1 Q1转移到状态 Q 2 Q_2 Q2的概率为:
∑ Q 1 = S 1 S p π ( Q 1 ) ∑ Q 2 = S 1 S p A Q 1 Q 2 ∑_{Q_1=S_1}^{S_{p}}π(Q_1)∑_{Q_2=S_1}^{S_{p}}A_{Q_1Q_2} Q1=S1∑Spπ(Q1)Q2=S1∑SpAQ1Q2
则,由μ生成可观测元素 O 1 , O 2 O_1,O_2 O1,O2的概率为:
∑ Q 1 = S 1 S p π ( Q 1 ) B Q 1 ( O 1 ) ∑ Q 2 = S 1 S p A Q 1 Q 2 B Q 2 ( O 2 ) ∑_{Q_1=S_1}^{S_{p}}π(Q_1)B_{Q_1}(O_1)∑_{Q_2=S_1}^{S_{p}}A_{Q_1Q_2}B_{Q_2}(O_2) Q1=S1∑Spπ(Q1)BQ1(O1)Q2=S1∑SpAQ1Q2BQ2(O2)
依次类推,可观测序列的第三个元素 O 3 O_3 O3产生的概率也是首先状态 Q 3 Q_3 Q3的所有的取值 S i S_i Si生成 O 3 O_3 O3的概率和,同时考虑从状态 Q 1 , Q 2 Q_1,Q_2 Q1,Q2转移到 Q 3 Q_3 Q3的概率,就可以推导出产生 O 1 , O 2 , O 3 O_1,O_2,O_3 O1,O2,O3的概率为:
∑ Q 1 = S 1 S p π ( Q 1 ) B Q 1 ( O 1 ) ∑ Q 2 = S 1 S p A Q 1 Q 2 B Q 2 ( O 2 ) ∑ Q 3 = S 1 S p A Q 2 Q 3 B Q 3 ( O 3 ) ∑_{Q_1=S_1}^{S_{p}}π(Q_1)B_{Q_1}(O_1)∑_{Q_2=S_1}^{S_{p}}A_{Q_1Q_2}B_{Q_2}(O_2)∑_{Q_3=S_1}^{S_{p}}A_{Q_2Q_3}B_{Q_3}(O_3) Q1=S1∑Spπ(Q1)BQ1(O1)Q2=S1∑SpAQ1Q2BQ2(O2)Q3=S1∑SpAQ2Q3BQ3(O3)
不断递推之后,我们可以知道生成整个序列的概率为:
∑ Q 1 = S 1 S p π ( Q 1 ) B Q 1 ( O 1 ) ∑ Q 2 = S 1 S p A Q 1 Q 2 B Q 2 ( O 2 ) . . . . . ∑ Q T = S 1 S p A Q T − 1 Q T B Q T ( O T ) ∑_{Q_1=S_1}^{S_{p}}π(Q_1)B_{Q_1}(O_1)∑_{Q_2=S_1}^{S_{p}}A_{Q_1Q_2}B_{Q_2}(O_2).....∑_{Q_T=S_1}^{S_{p}}A_{Q_{T-1}Q_T}B_{Q_T}(O_T) Q1=S1∑Spπ(Q1)BQ1(O1)Q2=S1∑SpAQ1Q2BQ2(O2).....QT=S1∑SpAQT−1QTBQT(OT)
上面的递推公式我们可以很容易的就确定。但是,这里存在的问题在于,如果我们想要获得观测序列的概率值,我们就必须穷尽所有的状态序列。也就是 ( p ) T (p)^T (p)T。为了更好的解决这个问题,提出了前向算法,过程描述如下:
首先定义:
α t ( i ) = P ( O 1 , O 2 , . . . O t , Q t = S i ∣ μ ) α_t(i)=P(O_1,O_2,...O_t,Q_t=S_i|μ) αt(i)=P(O1,O2,...Ot,Qt=Si∣μ)
该公式主要描述的是假设已经通过μ生成了{ O 1 , O 2 , . . . O t − 1 O_1,O_2,...O_{t-1} O1,O2,...Ot−1}的观测序列,同时在t时刻转移到 S i S_i Si状态,并由 S i S_i Si状态生成 O t O_t Ot的概率值。
当第一个时刻的时候有:
α 1 ( i ) = P ( O 1 , Q 1 = S i ∣ μ ) = π ( S i ) B i ( O 1 ) α_1(i)=P(O_1,Q_1=S_i|μ)=π(S_i)B_i(O_1) α1(i)=P(O1,Q1=Si∣μ)=π(Si)Bi(O1)
同理我们可以定义出t+1时刻:
α t + 1 ( j ) = P ( O 1 , O 2 , . . . O t , O t , Q t + 1 = S j ∣ μ ) α_{t+1}(j)=P(O_1,O_2,...O_t,O_t,Q_{t+1}=S_j|μ) αt+1(j)=P(O1,O2,...Ot,Ot,Qt+1=Sj∣μ)
进一步,我们可以推导出
α t + 1 ( j ) = P ( O 1 , O 2 , . . . O t , O t + 1 , Q t + 1 = S j ∣ μ ) = ∑ i = 1 p α t ( i ) A i j B j ( O t + 1 ) α_{t+1}(j)=P(O_1,O_2,...O_t,O_{t+1},Q_{t+1}=S_j|μ)=∑_{i=1}^pα_t(i)A_{ij}B_j(O_{t+1}) αt+1(j)=P(O1,O2,...Ot,Ot+1,Qt+1=Sj∣μ)=i=1∑pαt(i)AijBj(Ot+1)
根据递推公式,我们可以确定最后一个时刻T的时候,有:
α T ( j ) = P ( O 1 , O 2 , . . . O T , Q T = S j ∣ μ ) = ∑ i = 1 p α T − 1 ( i ) A i j B j ( O T ) α_{T}(j)=P(O_1,O_2,...O_T,Q_{T}=S_j|μ)=∑_{i=1}^pα_{T-1}(i)A_{ij}B_j(O_{T}) αT(j)=P(O1,O2,...OT,QT=Sj∣μ)=i=1∑pαT−1(i)AijBj(OT)
最后,对与整可观测序列的概率,就是对于各个 α T ( j ) α_{T}(j) αT(j)求和,用公式表达就是:
P ( O ∣ μ ) = ∑ j = 1 p P ( O 1 , O 2 , . . . O T , Q T = S j ∣ μ ) = ∑ j = 1 P α T ( j ) P(O|μ)=∑_{j=1}^pP(O_1,O_2,...O_T,Q_{T}=S_j|μ)=∑_{j=1}^Pα_{T}(j) P(O∣μ)=j=1∑pP(O1,O2,...OT,QT=Sj∣μ)=j=1∑PαT(j)
我们用一个图来描述一下上面的过程:
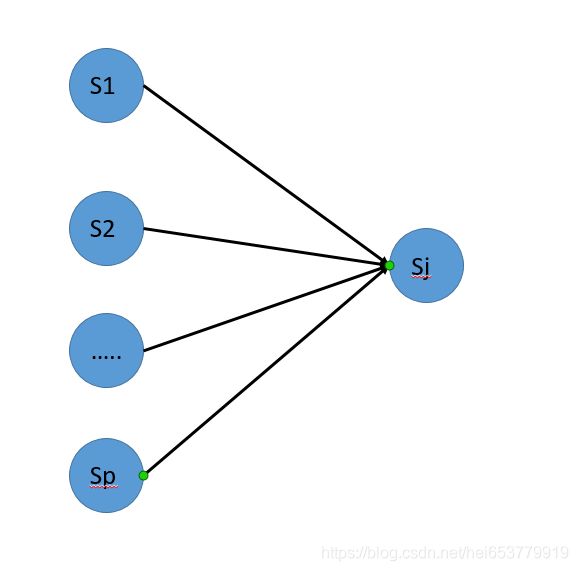
前一列是t时刻所有可能的状态 S i S_i Si,后一列是t+1时刻的 S j S_j Sj状态。也就是我们在计算t+1时刻的 S j S_j Sj状态的时候,已经考虑到了t时刻的所有状态。
2.1.3 算法过程
- 初始化第一个时刻的α,也就是:
α 1 ( i ) = P ( O 1 , Q 1 = S i ∣ μ ) = π ( S i ) B i ( O 1 ) α_1(i)=P(O_1,Q_1=S_i|μ)=π(S_i)B_i(O_1) α1(i)=P(O1,Q1=Si∣μ)=π(Si)Bi(O1) - 归纳计算
α t + 1 ( j ) = P ( O 1 , O 2 , . . . O t , O t + 1 , Q t + 1 = S j ∣ μ ) = ∑ i = 1 p α t ( i ) A i j B j ( O t + 1 ) α_{t+1}(j)=P(O_1,O_2,...O_t,O_{t+1},Q_{t+1}=S_j|μ)=∑_{i=1}^pα_t(i)A_{ij}B_j(O_{t+1}) αt+1(j)=P(O1,O2,...Ot,Ot+1,Qt+1=Sj∣μ)=i=1∑pαt(i)AijBj(Ot+1) - 最后求和
P ( O ∣ μ ) = ∑ j = 1 p P ( O 1 , O 2 , . . . O T , Q T = S j ∣ μ ) = ∑ j = 1 P α T ( j ) P(O|μ)=∑_{j=1}^pP(O_1,O_2,...O_T,Q_{T}=S_j|μ)=∑_{j=1}^Pα_{T}(j) P(O∣μ)=j=1∑pP(O1,O2,...OT,QT=Sj∣μ)=j=1∑PαT(j)
2.2 最优序列
2.2.1 问题描述
我们知道,每一个可以观测的元素是由一个状态生成的,在已知观测序列和HMM模型的条件下,我们应该如何选择一个最优的状态序列,使得由该状态序列生成的可观测序列的概率最大?用数学的形式描述就是:
m a x E ( Q ) = m a x ( π ( S Q 1 ) B S Q 1 ( O 1 ) A Q 1 Q 2 B S Q 2 ( O 2 ) A Q 2 Q 3 ) . . . . . A Q T − 1 Q T B S Q T ( O T ) ) max E(Q)=max(π(S_{Q1})B_{S_{Q1}}(O_1)A_{Q_1Q_2}B_{S_{Q2}}(O_2)A_{Q_2Q_3}).....A_{Q_{T-1}Q_T}B_{S_{Q_T}}(O_T)) maxE(Q)=max(π(SQ1)BSQ1(O1)AQ1Q2BSQ2(O2)AQ2Q3).....AQT−1QTBSQT(OT))
对于每一个 Q i Q_i Qi可以取状态空间S中的某一个状态。
2.2.2 问题推导
对于求解这个问题,我们采用的是维特比算法,其数学推导过程如下:
首先,我们给出如下的递推公式:
δ t ( i ) = m a x ( P ( Q 1 , Q 2 , . . . . Q t − 1 , Q t = S i , O 1 , O 2 , . . . O t ) ) δ_t(i)=max(P(Q_1,Q_2,....Q_{t-1},Q_t=S_i,O_1,O_2,...O_t)) δt(i)=max(P(Q1,Q2,....Qt−1,Qt=Si,O1,O2,...Ot))
我们来简单的解释以下这个公式,这个公式的意义在于在t时刻的时候,当该时刻取状态 S i S_i Si的时候能够获取到的关于可观测的序列的最大概率。如下图所示:

如上图所示,前面的一列是t-1时刻的可能取的所有状态,后一列是t时刻的j状态,对于j状态而言,可以由前一个时刻的可以取的任意一个状态转移过来,上述的公式的作用就是用来寻找概率最大的状态。图中所示的就是 S 2 S_2 S2。
在了解了上述公式的意义之后,我们开始逐步的递推,在这里,我们新增加一个函数用来回溯:
首先是第一步:
δ 1 ( i ) = π ( S i ) B S i ( O 1 ) δ_1(i)=π(S_i)B_{S_i}(O_1) δ1(i)=π(Si)BSi(O1)
Ψ 1 ( i ) = 0 , i ∈ [ 1 , p ] Ψ_1(i)=0,i∈[1,p] Ψ1(i)=0,i∈[1,p]
然后是第二步:
δ 2 ( j ) = m a x ( δ 1 ( i ) A S i S j B S j ( O 2 ) ) , i ∈ [ 1 , p ] δ_2(j)=max(δ_1(i)A_{S_iS_j}B_{S_j}(O_2)),i∈[1,p] δ2(j)=max(δ1(i)ASiSjBSj(O2)),i∈[1,p]
Ψ 2 ( j ) = m a x ( δ 1 ( i ) A S i S j ) , i ∈ [ 1 , p ] Ψ_2(j)=max(δ_1(i)A_{S_iS_j}),i∈[1,p] Ψ2(j)=max(δ1(i)ASiSj),i∈[1,p]
依次类推到第t+1步为:
δ t + 1 ( j ) = m a x ( δ t ( i ) A S i S j B S j ( O t + 1 ) ) , i ∈ [ 1 , p ] δ_{t+1}(j)=max(δ_t(i)A_{S_iS_j}B_{S_j}(O_{t+1})),i∈[1,p] δt+1(j)=max(δt(i)ASiSjBSj(Ot+1)),i∈[1,p]
Ψ t + 1 ( j ) = m a x ( δ t ( i ) A S i S j ) , i ∈ [ 1 , p ] Ψ_{t+1}(j)=max(δ_t(i)A_{S_iS_j}),i∈[1,p] Ψt+1(j)=max(δt(i)ASiSj),i∈[1,p]
到最后一步的时候:
δ T ( j ) = m a x ( δ t − 1 ( i ) A S i S j B S j ( O T ) ) , i ∈ [ 1 , p ] δ_{T}(j)=max(δ_{t-1}(i)A_{S_iS_j}B_{S_j}(O_{T})),i∈[1,p] δT(j)=max(δt−1(i)ASiSjBSj(OT)),i∈[1,p]
Ψ T ( j ) = m a x ( δ t − 1 ( i ) A S i S j ) , i ∈ [ 1 , p ] Ψ_{T}(j)=max(δ_{t-1}(i)A_{S_iS_j}),i∈[1,p] ΨT(j)=max(δt−1(i)ASiSj),i∈[1,p]
最后,我们找到概率最大的一条状态链为:
m a x E ( Q ) = m a x ( δ T ( j ) ) , j ∈ [ 1 , p ] max E(Q)=max(δ_{T}(j)),j∈[1,p] maxE(Q)=max(δT(j)),j∈[1,p]
2.2.3 算法描述
- 初始化:
δ 1 ( i ) = π ( S i ) B S i ( O 1 ) δ_1(i)=π(S_i)B_{S_i}(O_1) δ1(i)=π(Si)BSi(O1)
Ψ 1 ( i ) = 0 , i ∈ [ 1 , p ] Ψ_1(i)=0,i∈[1,p] Ψ1(i)=0,i∈[1,p] - 归纳计算:
δ t + 1 ( j ) = m a x ( δ t ( i ) A S i S j B S j ( O t + 1 ) ) , i ∈ [ 1 , p ] δ_{t+1}(j)=max(δ_t(i)A_{S_iS_j}B_{S_j}(O_{t+1})),i∈[1,p] δt+1(j)=max(δt(i)ASiSjBSj(Ot+1)),i∈[1,p]
Ψ t + 1 ( j ) = m a x ( δ t ( i ) A S i S j ) , i ∈ [ 1 , p ] Ψ_{t+1}(j)=max(δ_t(i)A_{S_iS_j}),i∈[1,p] Ψt+1(j)=max(δt(i)ASiSj),i∈[1,p] - 获取最大路径:
δ T ( j ) = m a x ( δ t − 1 ( i ) A S i S j B S j ( O T ) ) , i ∈ [ 1 , p ] δ_{T}(j)=max(δ_{t-1}(i)A_{S_iS_j}B_{S_j}(O_{T})),i∈[1,p] δT(j)=max(δt−1(i)ASiSjBSj(OT)),i∈[1,p]
Ψ T ( j ) = m a x ( δ t − 1 ( i ) A S i S j ) , i ∈ [ 1 , p ] Ψ_{T}(j)=max(δ_{t-1}(i)A_{S_iS_j}),i∈[1,p] ΨT(j)=max(δt−1(i)ASiSj),i∈[1,p]
m a x E ( Q ) = m a x ( δ T ( j ) ) , j ∈ [ 1 , p ] max E(Q)=max(δ_{T}(j)),j∈[1,p] maxE(Q)=max(δT(j)),j∈[1,p] - 路径回溯
Q t = Ψ t + 1 ( Q t + 1 ) Q_t=Ψ_{t+1}(Q_{t+1}) Qt=Ψt+1(Qt+1)
2.3 参数估计问题
2.3.1 问题描述
给定可观测序列 O 1 , O 2 , . . . O T O_1,O_2,...O_T O1,O2,...OT,如何确定HMM模型中的参数π,A,B来使得产生可观测序列的概率最大?
2.3.2 问题推导
我们首先给出两个定义:
θ t ( i ) = P ( O 1 , O 2 , . . . O t , Q t = S i ∣ μ ) θ_t(i)=P(O_1,O_2,...O_t,Q_t=S_i|μ) θt(i)=P(O1,O2,...Ot,Qt=Si∣μ)
β t ( i ) = P ( O t + 1 , O t + 1 , . . . O T ∣ Q t = S i , μ ) β_t(i)=P(O_{t+1},O_{t+1},...O_T|Q_t=S_i,μ) βt(i)=P(Ot+1,Ot+1,...OT∣Qt=Si,μ)
根据上面的定义,我们可以确定的是:
β T ( i ) = 1 , i ∈ [ 1 , p ] β_T(i)=1, i∈[1,p] βT(i)=1,i∈[1,p]
β t ( i ) = ∑ j = 1 p A i j β t + 1 ( j ) B j ( O t + 1 ) , t ∈ [ 1 , T − 1 ] β_t(i)=∑_{j=1}^pA_{ij}β_{t+1}(j)B_j(O_{t+1}),t∈[1,T-1] βt(i)=j=1∑pAijβt+1(j)Bj(Ot+1),t∈[1,T−1]
- 首先,我们随机化HMM的参数π,A
- 然后我们计算:
ξ t ( i , j ) = P ( Q t = S i , Q t + 1 = S j ∣ O , μ ) = θ t ( i ) A i j β t + 1 ( j ) B j ( O t + 1 ) ξ_t(i,j)=P(Q_t=S_i,Q_{t+1}=S_j|O,μ)=θ_t(i)A_{ij}β_{t+1}(j)B_j(O_{t+1}) ξt(i,j)=P(Qt=Si,Qt+1=Sj∣O,μ)=θt(i)Aijβt+1(j)Bj(Ot+1)
进一步推导之后有:
ξ t ( i , j ) = P ( Q t = S i , Q t + 1 = S j , O ∣ μ ) P ( O ∣ μ ) = θ t ( i ) A i j β t + 1 ( j ) B j ( O t + 1 ) P ( O ∣ μ ) = θ t ( i ) A i j β t + 1 ( j ) B j ( O t + 1 ) ∑ i = 1 p ∑ j = 1 p θ t ( i ) A i j B j ( O t + 1 ) β t + 1 ( j ) ξ_t(i,j)=\frac{P(Q_t=S_i,Q_{t+1}=S_j,O|μ)}{P(O|μ)}=\frac{θ_t(i)A_{ij}β_{t+1}(j)B_j(O_{t+1})}{P(O|μ)}\\ =\frac{θ_t(i)A_{ij}β_{t+1}(j)B_j(O_{t+1})}{∑_{i=1}^p∑_{j=1}^pθ_t(i)A_{ij}B_j(O_{t+1})β_{t+1}(j)} ξt(i,j)=P(O∣μ)P(Qt=Si,Qt+1=Sj,O∣μ)=P(O∣μ)θt(i)Aijβt+1(j)Bj(Ot+1)=∑i=1p∑j=1pθt(i)AijBj(Ot+1)βt+1(j)θt(i)Aijβt+1(j)Bj(Ot+1)
则定义:
γ t ( i ) = P ( Q t = S i , O ∣ μ ) = ∑ j = 1 p ξ t ( i , j ) γ_t(i)=P(Q_t=S_i,O|μ)=∑_{j=1}^pξ_t(i,j) γt(i)=P(Qt=Si,O∣μ)=j=1∑pξt(i,j)
3. 根据上面的计算,我们可以计算出:
π ( S i ) = γ 1 ( i ) π(S_i)=γ_1(i) π(Si)=γ1(i)
A i j = ∑ t = 1 T − 1 ξ t ( i , j ) ∑ t = 1 T − 1 γ t ( i ) A_{ij}=\frac{∑_{t=1}^{T-1}ξ_t(i,j)}{∑_{t=1}^{T-1}γ_t(i)} Aij=∑t=1T−1γt(i)∑t=1T−1ξt(i,j)
4. 对于B矩阵的计算可以采用的是
B j ( O k ) = ∑ t = 1 T γ t ( j ) ∗ δ t ( O k ) ∑ t = 1 T γ t ( j ) B_j(O_k)=\frac{∑_{t=1}^Tγ_t(j)*δ_t(O_k)}{∑_{t=1}^Tγ_t(j)} Bj(Ok)=∑t=1Tγt(j)∑t=1Tγt(j)∗δt(Ok)
3、总结
在明确了HMM模型的三个问题之后,我们就可以根训练数据来训练HMM的相关参数π,A,B。对于测试数据而言,根据维特比算法,可以确定最优的状态转移序列和整个序列的概率值。
3.1 参考文献
- 浙江大学《机器学习》
- 宗成庆 《统计自然语言处理》