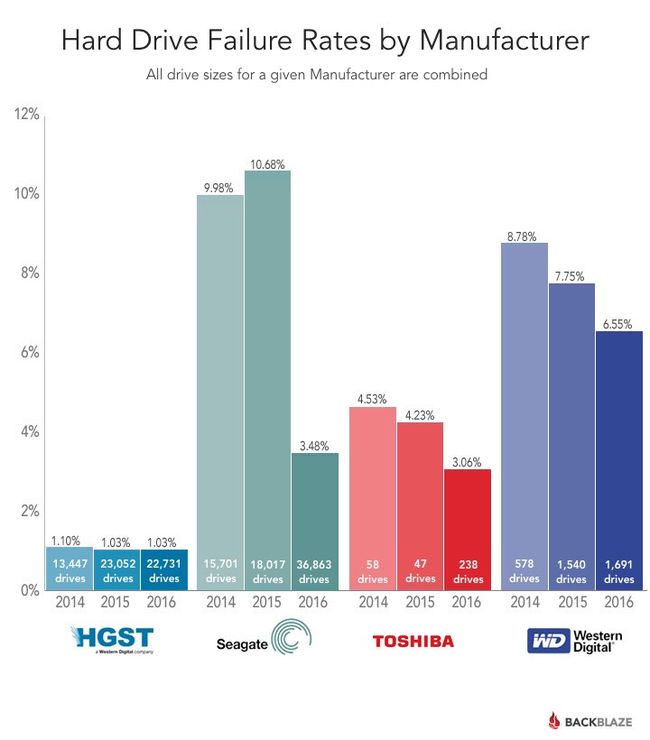
分布式系统下的纠删码技术之Erasure Code
Erasure Code(简称EC,也称擦除码或纠删码)是1组数据冗余和恢复算法的统称。本教程以Vandermonde矩阵的Reed-Solomon来解释EC原理。
术语定义:
- dj-数据块;
- yi-通过数据块计算得来,作为数据冗余的校验块;
- uj-丢失的、需要恢复的数据块;
- k-数据块数量;
- m-校验块数量。
本教程包括:
- 分布式系统的可靠性问题: 冗余与多副本——提出EC需要解决的问题;
- EC的基本原理——用到中学数学知识, 举“栗子”的方式直观解释EC算法,希望对分布式存储领域增加了解的同学,可只阅读该部分;
- EC编码矩阵的几何解释——解释EC编码矩阵的原理和含义,希望深入了解EC数学原理的读者, 可从此部分开始;
- EC解码过程: 求解n元一次方程组;
- 新世界: 伽罗华域 [Galois-Field] GF(7)
- EC使用的新世界 [Galois-Field] GF(256)
(以上两节介绍EC在计算机上的应用方法) - 实现——对工程实践方面感兴趣的同学可参考;
- 分析——需要规划存储策略的架构师可参考。
本文将对1-4章节进行介绍,5-8章节将在白山微信公众号(baishancloud)持续推送。
分布式系统的可靠性问题: 冗余与多副本
在分布式系统中,可靠性问题是首要问题。2000多年前古埃及人在罗塞塔石碑上重复三次记录同一信息,为后世破译托勒密五世登基诏书提供了高可靠性;同样,服务器宕机、光纤挖断、洪水淹没机房也会发生,数据要达到工业可用的可靠性需要对数据进行多副本存储,且多个副本应分布在不同服务器、机架、机房才能真正实现高可靠。
副本数一般为3:
3副本结合当前经验磁盘损坏率(年损坏率7%),大约可达到11个9以上的工业可接受的可靠性。
例如:有2块数据d1和d2,为了达到高可靠性,需每个数据复制3份,并存放在不同服务器以保证足够分散。保存位置如下:
(d1 ,d1 ,d1 )
(d2,d2,d2)
...第n列的d1,d2存储在第n个服务器上(n=1,2,3)
在3副本策略下, 总存储冗余度为300%;空间浪费为200%
有时为降低成本, 只存储2副本, 此时冗余度为200%,浪费1倍空间。
能否用较少冗余,实现同样较高的可靠性,成为分布式存储一个重要研发方向。这就是本文介绍的EC需要解决的问题。
EC的基本原理
例子1: 实现k+1的冗余策略(大概需要小学3年级的数学知识)
Q:有3个自然数,能否通过记录第4个数字,使任意一个数字丢失时都可被找回?
很简单,只需记录这3个数字的和。
假设3个数字是:d1,d2,d3
再存储一个数:y1=d1+d2+d3
存储过程:存储这4个数字:d1,d2,d3,y1数据丢失找回时:
如果 d1,d2,d3 中任意一个丢失, 如 d1丢失, 可通过 d1=y1−d2−d3 找回;
如果 y1丢失,可通过 y1=d1+d2+d3找回;在上述简单的系统中,共存储4份数据,有效数据3份、冗余133%;可靠性与2副本存储策相近:最多允许丢失1份数据;

可靠性目前还只是差不多,并不完全一样,“第八节:分析”中将详细讨论可靠性的计算。讨论可靠性时,一般数据丢失风险没有量级差异, 就可认为是较为接近的。
上述例子原理与RAID-5基本相同。RAID-5对k个(一般11个左右)数据块求1份校验和的数据块并存储,允许1块(数据块或校验块)丢失后可找回。(当然在工程上,RAID-5的计算与自然数求和略有差异,后面将继续说明。)
以上这种求和冗余策略,就是EC的核心思路。
后续章节将继续深入,逐步把上述求和冗余推广成生产环境下可用的存储策略,同时也会逐步引入更多数学知识来完善。
例子2: 实现k+m的冗余策略
(1)再增加1个校验块,变成k+2
栗子1中,我们通过增加1份冗余,实现了与2副本相近的可靠性(允许丢失1块数据)。那与3副本差不多的可靠性如何实现呢(允许丢失2块数据)?
Q:有3块数据:d1,d2,d3,可否再存储2个冗余的校验块(共5块),使整个系统丢失任意2份数据时都能找回?
k+1求和策略,实际是给所有数据块和校验块建立方程d1+d2+d3=y1, 来描述整体关系。
现在,如果增加可丢失的数据块数,简单将y1存储2次并不够。
假设计算2个校验块:
d1+d2+d3=y1
d1+d2+d3=y2
(y1=y2)存储过程:存储 d1,d2,d3,y1,y2
恢复数据:如果 d1,d2 都丢失(用u1,u2表示),下面关于u1,u2的线性方程有无穷多解:
u1+u2+d3=y1
u1+u2+d3=y2所以需要设计计算第2个校验块y2的方法,使d1,d2丢失时方程组有解。
相对简单直接的思路是:计算y2时,为每个数据dj增加1个不同的系数,如:
计算y1时,对每个数字乘以1, 1, 1, 1 …
计算y2时,对每个数字乘以1, 2, 4, 8 …
d1+d2+d3=y1
d1+2d2+4d3=y2存储过程:存储 d1,d2,d3,y1,y2
数据恢复:如果d1,d2丢失(用 u1,u2表示),可使用d3,y1,y2建立关于u1,u2的二元一次方程组:
u1+u2=y1−d3
u1+2u=y2−4d3这种添加系数计算校验块的方式,就是RAID-6的基本工作方式:
RAID-6在k个数据块之外再多存储2个校验数据,当系统丢失2块数据时,就可以找回丢失数据。
k+2冗余策略通过166%的冗余,实现了与三副本300%冗余几乎相同的可靠性。(具体可靠性计算参见“第8节:分析”。)
(2)实现k+m 的冗余
要实现与4副本差不多的可靠性,我们需要更多冗余(再增加一个校验块y3):
y3的计算需要再为所有dj选择1组不同的系数,如1,3,9,27…保证数据丢失时,得到的三元一次方程组可解:
d1+d2+d3=y1
d1+2d2+4d3=y2
d1+3d2+9d3=y2通过不断增加不同系数,可实现任意k+m的EC冗余存储策略。
以上是有理数下EC算法介绍,接下来将讨论系数选择的依据。
EC是更具通用性的算法,RAID-5和RAID-6都是EC的子集,因实现成本(主要为计算的开销)较高,RAID-5和RAID-6在单机的可靠性实现中占主流地位。
但随着存储量不断增大,百PB级存储已不能称之为很极端的场景了。RAID-6数据丢失的风险在大数据量级的场景中越来越明显,于是在云存储(大规模存储)领域,能支持更多冗余校验块的EC成为主流。
EC编码矩阵的几何解释
EC 可这样理解:为恢复丢失的数据,需预先计算出几个数值(校验块),校验块和数据块构成1个整体,并具备所有数据块的特征,可配合其他数据找回丢失的数据块。
(1)k=2,为2个数据块生成冗余校验块
假设有2个数据块 d1,d2,需要计算2个校验块y1,y2,。
我们可通过1个直线方程,实现数据的冗余备份和恢复:
y=d1+d2x这条直线包含所有数据块dj的信息:
任何一组 d1,d2的值确定唯一一条直线;任意一条直线也对应唯一一组d1,d2。
数据可靠性问题转化成:保存足够多直线信息,需要时找回这条直线,然后再提取直线方程的系数来找回最初存储的数据块 d1,d2。
而保存足够多的信息,最直接的方法是记录这条直线上几个点的坐标。两点确定一条直线,只要拿到直线上2个点的坐标,就能确定直线方程,从而确定系数d1,d2。
按照这样的思路,我们重新用直线方程描述数据冗余生成和数据恢复的过程:
- 生成冗余:在直线上取2个点, 记录点的坐标。(取x=[1, 2, 3…],则只需记录y的值);
- 恢复数据:通过已知过直线的2点确定直线方程。
d1,d2,y1,y2,这4个数据中,任意丢失2个,都可以通过等式关系 y=d1+d2⋅x恢复。
丢失1个数据块时可只用 y1的方程;
丢失2个数据块时需解二元一次方程组;
若y1或 y2丢失, 则通过重新取点的方式恢复。
我们可以在直线上取任意多个点,但恢复时最多只需要2个。这个例子实现了2+m的冗余策略。
(2)k=3, 4, 5…时数据块的冗余
直线方程只需2个值确定,但如果用描点方式为更多数据块生成冗余数据,则需要使用高次的曲线,记录更多数据。
例如:二次曲线抛物线 y=ax2+bx+c需要3个值确定,同时也需要抛物线上3个点的坐标找回这条抛物线。
- 通过高次曲线生成冗余数据
如果有k个数据块,可将k个数据作为系数,定义1条关于x的高次曲线:
![]()
生成m个冗余数据:
取m个不同的x值(1, 2, 3…m),记录这条曲线上m个不同点的坐标:(1,y1),(2,y2)…(m,ym);存储所有数据块d1,d2…dk和所有校验块y1,y2…ym。
恢复数据:
当数据丢失时,平面直角坐标系上m个点可唯一确定1条m-1次幂的关于x的曲线。确定这条曲线,就能找回它的系数,即数据块d1,d2…dk。
以上就是EC算法的几何解释:通过曲线上的点确定曲线的过程。
- 从曲线方程得到系数矩阵
在曲线上取点的过程中,可直接为x取自然数(1, 2, 3…)来计算y的值;
y1=d1+d2⋅1+d3⋅12+..+dk⋅1k−1
y2=d1+d2⋅2+d3⋅22+..+dk⋅2k−1
y3=d1+d2⋅3+d3⋅32+..+dk⋅3k−1...把上面等式写成矩阵的形式,可得到EC校验块的生成矩阵Generator-Matrix:

y1,y2…ym为校验块的数据,矩阵中为系数。
这就是著名的Vandermonde 矩阵。
Vandermonde矩阵只是EC中一种系数的选择方式,其他常用的系数矩阵还有 Cauchy 矩阵等。
EC解码过程:求解n元一次方程组
现在我们知道,EC 就是:
有1组数字: d1,d2,d3…dk,另外记录m个校验用的数字y1,y2,y3…ym,使这k+m个数字中任意丢失m个,都能从剩下的k个中恢复所有k+m个数字。
EC生成校验块的过程称之为EC编码,当数据丢失需要找回时,使用EC解码过程。
如上面章节所说,EC编码过程是编码矩阵(Vandermonde)和数据块列相乘:

解码过程如下:
假设有q(q≤m)个数字丢失,在上述编码矩阵中选择 y1,y2..yq,组成的一次方程组,求解丢失的数据。
例如:d2,d3丢失(u2,u3表示), 因为只丢失2块数据,只需2个校验块来恢复数据:

该矩阵表示的方程组有2个未知数u2,u3,解方程即可得到这2块丢失的数据。
- Vandermonde 矩阵保证方程组有解
对于k+m的EC来说,任意丢失m个数据块都可将其找回。
Vandermonde矩阵保证了任意m行m列组成的子矩阵都是线性无关的,构成的方程有确定解。

Vandermonde的行列式的值为:
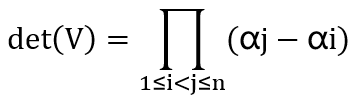
只要αi都不同,则 Vandermonde 矩阵的行列式就不为0,矩阵可逆,方程有唯一解。
容易证明,Vandermonde矩阵任意m×m的子矩阵可保证永远有唯一解。
以上我们讨论了EC在有理数范围内全部内容,但尚不能直接应用于计算机的代码开发商。
关于纯数学和计算机算法之间的问题,以及如何解决,并将EC真正应用到生产环境,将在《xp的分布式系统系列教程之- Erasure-Code(实践与分析篇)》中继续探讨。
作者:张炎泼,白山云合伙人兼研发副总裁,曾就职于新浪、美团云等。目前主要负责白山云科技对象存储研发、数据跨机房分布和修复问题解决等工作。以实现100PB级数据存储为目标,其带领团队完成全网分布存储系统的设计、实现与部署工作,将数据“冷”“热”分离,使冷数据成本压缩至1.2倍冗余度。