Pytorch自然语言处理(2) 使用torchtext工具包进行csv格式的文本预处理
在训练NLP模型时,我们要做的第一件事是对数据集进行预处理。torchtext提供了一系列非常方便的API供用户使用,完美囊括了旧有的sklearn, keras等工具包的功能。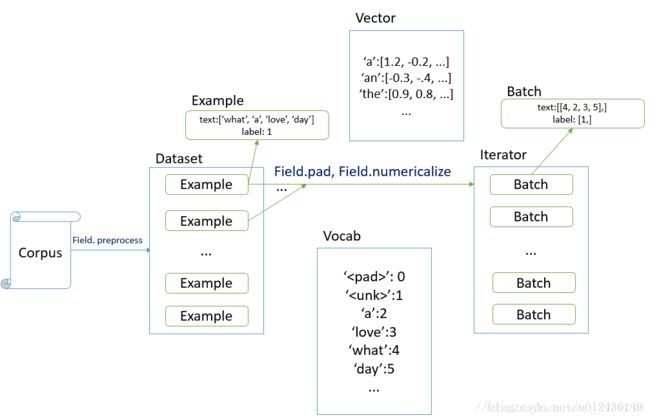
本文主要介绍如何使用torchtext处理csv格式的数据。首先我们会介绍用到的类,然后给出示例代码进行说明。
1. 创建Field类
Field类用于定义数据处理的规则,并利用规则构造字典(初始化一个Vocab类)。
它的构造函数为
Field(sequential=True, use_vocab=True, init_token=None, eos_token=None,
fix_length=None, dtype=torch.int64, preprocessing=None, postprocessing=None,
lower=False, tokenize=None, tokenizer_language='en', include_lengths=False,
batch_first=False, pad_token='', unk_token='', pad_first=False,
truncate_first=False, stop_words=None, is_target=False)
这里解释几个重要参数
-
sequential 表示输入数据是否为序列,如果为False,则不对输入数据符号化(tokenize),默认值为True。一般来说对于文本数据应为True,对于标签数据应为False。
-
use_vocab 是否使用Vocab,默认为True
-
batch_first 生成的tensor的第一个维度是否为batch
-
lower 是否转小写
-
pad_token, unknown_token 自定义补全符号、未知符号,默认值为"
", “ ”,
举例:声明一个数据处理规则用于处理文本
TEXT = data.Field(sequential=True, batch_first=True, lower=True, pad_token=PAD_TOKEN)
2. 分割数据集
构建三部分数据集(train, dev, test),数据集分别保存在三个csv文件中。
直接看例子。
train_data, dev_data, test_data = data.TabularDataset.splits(
path = 'data/',
train='task2_train.csv',
validation = 'task2_dev.csv',
test='task2_test.csv',
format = 'csv',
fields = datafields
)
这里通过三个.csv文件初始化三个dataset对象,fields的格式必须为list of tuples,每一个tuple是二元组,分别表示列名和对应的field。例如我们只想获得文本数据和对应的标签,而忽略其余无关紧要的两列,只需要将忽略的列表的tuple第二个元素传入None即可。
datafields = [("PhraseId", None),
("SentenceId", None),
("Phrase", TEXT),
("Sentiment", LABEL)]
3. 构建字典
根据训练数据构造字典,字典具有的功能包括
- stoi, itos 符号和索引的双向转换
- vectors 每个索引对应的向量,如果要获得某个符号的embedding,需要首先进行stoi的映射再look up这里的vectors
- Vocab 词典,需要通过调用成员方法build_vocab实现
一般来说,无键值参数(*kargs)初始化了specials参数,和
键值参数**kwargs一起作为Vocab的构建参数传入Vocab的构造函数中去。
例如使用glove.6B.50d预训练模型根据train_data初始化一个词典,并将
TEXT.build_vocab(train_data, vectors='glove.6B.50d', unk_init = lambda x:torch.nn.init.uniform_(x,a=-0.25,b=0.25))
LABEL.build_vocab(train_data)
# Set PAD_TOKEN row to be all zero
PAD_INDEX = TEXT.vocab.stoi[PAD_TOKEN]
TEXT.vocab.vectors[PAD_INDEX] = 0.0
4. 构造迭代器
torchtext提供了三种类型的迭代器类型
- BucketIterator 在打乱(shuffle)数据的同时尽量减少padding的长度(一般用于train set)
- Iterator 普通的迭代器,一般用于测试集和验证集
- BPTTIterator 没用过不太清楚
下面使用BucketIterator构造训练集,指定了要生成batch的原数据集,batch_size和随机打乱
train_iterator = data.BucketIterator(train_data, batch_size = BATCHSIZE, train=True, shuffle=True, device=DEVICE)