动手学数据分析——chapter 1
1 pandas基础
1、数据的导入
1.1 相对路径导入
通过pandas导入数据,在相对路径的情况下比较方便,直接在直接调用pandas的read_csv函数,参数为要导入的CSV数据的文件名:
df = pd.read_csv('train.csv')
df.head(5)
调用head()函数可以查看数据的前几行的内容,这样对数据的所有列有一个清晰的把握。
1.2 绝对路径导入
df = pd.read_csv('/Users/Chauncy/chapter1/train.csv')
df.head(5)
1.3 逐块读取
逐块读取相对与全文整体读取,增加了数据的可操作性;相对于逐行读取又有一定的完整性。是介于两者之间的一种操作。
chunker = pd.read_csv('train.csv',chunksize = 1000)
1.4 更改表头
在数据处理当中,很多原始数据的表头都是英文的,尤其是一些比较有名的数据集,所以更改数据的表头说明很有必要,可以增加可读性。
df = pd.read_csv('train.csv',names=['乘客ID','是否幸存','舱位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱',\
'登船港口'],index_col = '乘客ID',header=0)
df.head()
2 观察数据
通过观察数据可以观察数据的大致组成,大致的信息包括数据量的大小、多少列、各列的内容以及是否包括null等
2.1 查看数据基本信息
调用pandas对象中的info()函数
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 是否幸存 891 non-null int64
1 舱位等级 891 non-null int64
2 姓名 891 non-null object
3 性别 891 non-null object
4 年龄 714 non-null float64
5 兄弟姐妹个数 891 non-null int64
6 父母子女个数 891 non-null int64
7 船票信息 891 non-null object
8 票价 891 non-null float64
9 客舱 204 non-null object
10 登船港口 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 83.5+ KB
2.2 观察数据的指定行
通过head()函数和tail()函数
df.head(10)
df.head(10)
3 数据另存为新的文件
df.to_csv('train_chinese.csv')
4 pandas中的数据类型
pandas中有两种数据类型,分别是DataFrame和Series
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
example_1 = pd.Series(sdata)
example_1

data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
example_2 = pd.DataFrame(data)
example_2
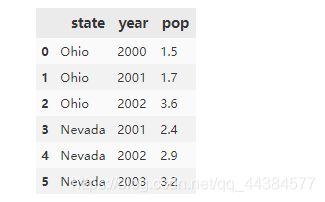
pandas中默认的数据类型就是DataFrame
5 查看数据
# 按行查看数据,比如查看前三行
df.head(3)
# 查看DataFrame数据的每列的表头
df.columns
# 查看指定列的数据的前几行
df['是否幸存'].head(3)
6 删除指定列
del df['a']
7 按列隐藏元素
df.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
8 筛选
8.1 筛选年龄小于10岁的
df[df["年龄"]<10].head(3)

8.2 筛选10-50岁的乘客,并把这个数据作为一个新的对象,命名为midage
midage = df[(df["年龄"]>10)& (df["年龄"]<50)]
midage.head(3)
8.3 显示指定行中的指定列的数据
midage = midage.reset_index(drop=True)
midage.head(3)
midage.loc[[100],['舱位等级','性别']]

8.4 显示指定单元格的数据
使用loc()方法
midage.loc[[100,105,108],['舱位等级','姓名','性别']]

使用iloc()方法
midage.iloc[[100,105,108],[2,3,4]]
