当前大多数图像语义分割算法都是基于深度学习的方式,但是深度学习的效果很大程度上是依赖于大量训练数据的。目前的图像分割方法无非两种,一种是通过标注人员手动标注,如Cityscapes(提供无人驾驶环境下图像分割的数据集)中的标注,但这种方法需要花费大量的人力、物力和时间。例如,下面这张包含28个目标事例的图,处理它就需要人工手动点击580次,这真的要点到手疼。

另一种则是将目标分割看作是像素标注的问题(pixel-labeling problem)自动完成分割工作。但是这种方法自身有较大的不精确性,而又无法通过人员干涉来修正,所以很难用来作为地面实况的评测数据。那么在填充评测数据集(例如Cityscapes)时,我们能否做到既可以自动标注以节省成本,在需要的时候又能通过人工修正来保证精度呢?
下面我们引入两篇CVPR的论文来给出答案:
一.(CVPR 2017) Annotating Object Instances with a Polygon-RNN
1.简介
作者采用了一种不同于像素标注的方法,而是将目标分割看做是一个多边形预测的问题(polygon prediction problem),然后基于深度学习实现“半自动化”目标事例的标注。

那这篇文章为何称为半自动目标事例标注呢?这是因为以下两点:
①、这篇文章算法首先需要给定一个bounding box真值,然后使用一个RNN(Recurrent Neural Network),文中称为Polygon-RNN在这个目标框中画出目标一个多边形圈住的轮廓。因为相比较手动标注目标轮廓,bounding box标注只要两下鼠标点击即可,容易很多(见上方右图)。
②、算法标注轮廓过程,人为可干预从而产生更精确的标注结果。这块细节下文再仔细介绍过程。
2 Polygon-RNN:
2.1 介绍
我们再来好好总结一下整个过程,作者是想创建一个有效的标注工具(annotation tool),从而以多边形形式标注目标事例。当给定bounding box中的图像块(image patch),文章算法基于RNN可以预测一个封闭的多边形来圈出目标的轮廓。多边形设计方法就是先找到一个起点,然后以顺时针方式连续生成多边形的其他顶点,顺序连接所有顶点即形成这个圈出目标轮廓的多边形。
作者是想创建一个有效的标注工具(annotation tool),从而以多边形形式标注目标事例。当给定bounding box中的图像块(image patch),文章算法基于RNN可以预测一个封闭的多边形来圈出目标的轮廓。多边形设计方法就是先找到一个起点,然后以顺时针方式连续生成多边形的其他顶点,顺序连接所有顶点即形成这个圈出目标轮廓的多边形。
模型是一个RNN,每一次迭代预测一个多边形顶点。RNN每一次的迭代输入包含以下三个方面:
第一是图片的CNN特征表示(图中绿色方块);
第二是前两个RNN迭代输出的顶点(图中t-1和t-2的结果),依一个方向形成多边形;
第三是起点,帮助RNN决定何时封闭多边形。
整个网络框架如下图:
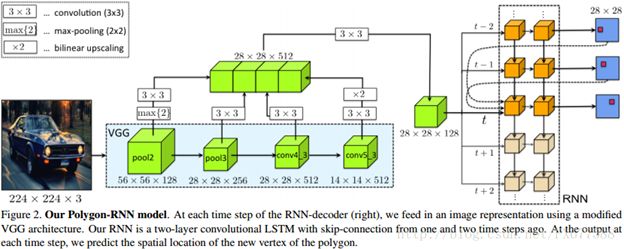
网络是端到端(end-to-end)训练RNN+CNN,其中关键是帮助CNN能够微调(fine-tuned)来预测目标边界,并且帮助RNN从这些边界学习来利用其循环特性编码目标形状。