车牌识别--Opencv传统图像处理+Pytorch搭建卷积神经网络
一.原理与步骤
可以用传统的机器学习方式,确定图片中车牌的位置,之后对车牌进行相应的处理,图像分割,尺寸调整,平滑图像等,再事先利用神经网络,搭建网络模型、训练模型、保存模型参数,最后把前面分割好的图像转换成能适应这个网络模型的图像格式,传入网络模型,最后得到预测结果。本文用到的车牌图片如有侵犯,请联系,立即删~
流程图如下:

二.模块化编程调试
1. 字符识别
介绍:在本节中我用神经网络对字符进行识别,我应用pytorch这个深度学习框架,分别进行了卷积神经网络模型的搭建、GPU下模型训练、模型参数保存和下载、单照片模型测试,最终实现字符识别。
具体:
a. 数据集:我用的数据集比较小,它的好处是训练比较快,基本能满足本项目的需求,缺点是,有些比较模糊的图象是回识别不出来,数据集具体如下,规格是20203

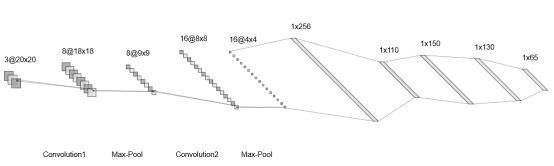
b. CNN网络模型搭建:根据项目需求,卷积神经网络模型可以胜任这个任务,设计搭建了这个网络模型,代码如下:其中包含两个卷积层、池化层、rule层、以及四个全连接层,最后输出65个得分结果,本项目中分类器的种类有65个。
'''定义网络模型的类'''
class Net(nn.Module): #要继承这个类
def __init__(self):
super(Net ,self).__init__() #父类初始化
'''定义网络结构'''
self.conv1 = nn.Conv2d(3 , 8 , 3 ) #输入颜色通道 :1 输出通道:6,卷积核:5*5 卷积核默认步长是1 30*30
self.conv2 = nn.Conv2d(8 , 16 , 2 )#这是第二个卷积层,输入通道是:6 ,输出通道:16 ,卷积核:3*3 30*30
self.pool = nn.MaxPool2d(2, 2) # 最大池化层 10*10
#self.conv3 = nn.Conv2d(16 , 8 , 2)#第三个卷积层,输入层的输入通道要和上一层传下来的通道一样,这里给了填充是2,这个参数默认是:0,填充可以把边缘信息、特征提取出来,不流失 14*14
self.fc1 = nn.Linear(16*4*4 , 110)
self.fc2 = nn.Linear(110 , 150)
self.fc3 = nn.Linear(150 , 130)
self.fc4 = nn.Linear(130 , 65) #三个全连接层 65 是最终输出有65个类别
def forward(self , x): #前向传播,把整个网络模型,顺序连接起来,init里面只是对层初始化(需要用到的层)
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
#x = F.relu(self.conv3(x))
x = x.view( -1 ,16*4*4) #转录成可以传入全连接层的的形状
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
可视图如下:
c. 训练模型,保存参数,代码如下:具体包含前向传播、反向传播、计算误差、优化器计算、更新参数、保存模型参数(权重值,卷积核值等)
def train_net(self):
self.net = Net() # 把模型的定义一下
criterion = nn.CrossEntropyLoss() # 定义一个计算损失值 赋给一个对象
optimizer = optim.SGD(self.net.parameters(), lr=learning_rate, momentum=0.9)
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(Setloader.trainset_loader(self), 0):
inputs, labels = data
optimizer.zero_grad()
outputs = self.net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 200 == 199:
print('[%d ,%5d]loss:%.3f' % (epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
print('finished training!')
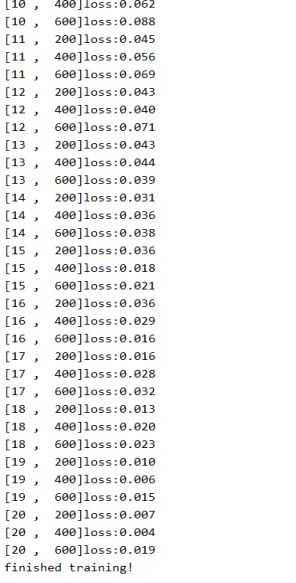
torch.save(self.net.state_dict(), 'zuoye_net_homewords.pkl') # 训调整学习率和网络模型epoch数,使最终训练效果达到最优。如下图,可以看到训练到20个epoch时,mini-batch的loss已经逐渐下降到0.019。从一开始loss是4+下降到0.019,说明网络模型是有在学习也学习得不错。训练时如果要用GPU训练,这需要安装cuda,以及在代码中将网络模型、照片、标签传到对应的GPU上。
d. 测试:

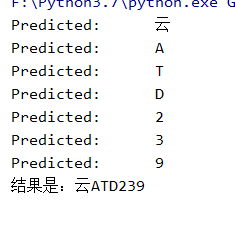
2. 车牌定位与分割
介绍:在一张照片中必须先找到车牌的位置之后再对车牌区域ROI进行图像分割、形态学变换。这部分对整个项目来说很重要,应该这个环节是前提。有传统机器视觉的方法、以及深度学习两种方法对车牌定位,深度学习的方法需要大量的样本、应用目标识别等算法YOLO系列、SSD系列均可以实现并达到很好的效果。但考虑没有很好的GPU以及不想做打标等费时不讨好的工作,故选择应用传统的机器视觉的方案进行车牌定位。在这个部分,应用了传统机器视觉识别的办法,做到了可以识别10张以上不同场景的车牌,效果已经很好了。
具体:引用opencv,对图像进行如下处理,形象相关调参,实现本小节的功能
a. hsv颜色变换


b. 图像平滑、形态学变换


c. 找图像中的外接矩形


d. 根据矩形长宽比、矩形面积筛选车牌,实现车牌的定位(如下文效果所示)
e. 对车牌ROI进行透视变换,字符分割


识别效果效果:可识别出在不同场景,不同光强下的车辆车牌







这部分是要识别好车牌的前提,该部分要先定位好图像中的车牌,把车牌识别好,去除车牌中存在的干扰,才能更有利于字符的分割。本部分应该针对特定场景下的,设计的算法会比较稳定识别率也会比较高。关于图像分割部分,要尽量不字符提取出来,而且不要包含太多噪声。深度学习网络应该提高其泛化能力,最终才能实现更高的识别效果,甚至是产品级别。
img = cv2.imread('G:\deep_learming\pytorch\data\car_pai\jk3.jpg',1)
imgg= img.copy()
img = cv2.cvtColor(img , cv2.COLOR_BGR2HSV)
lower_blue = np.array([100, 100, 100])
upper_blue = np.array([120, 220, 255])
img2 = cv2.inRange(img, lower_blue, upper_blue) # img1通道是HSV不是BGR了 在指定图像中选定范围像素点
img2 = cv2.bilateralFilter(img2 ,35 ,75 ,71)
cv2.namedWindow('show')
cv2.imshow('show', img2)
cv2.waitKey(-1)
cv2.destroyAllWindows()
kernel = np.ones((13, 13), np.uint8)
closing_img = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, kernel)
closing_img = cv2.bilateralFilter(closing_img,25,75,75)
contours , hierarchy = cv2.findContours(closing_img,1,2)
for i in range(len(contours)):
cnt = contours[i]
rect = cv2.minAreaRect(cnt)
box = cv2.boxPoints(rect)
box = np.int0(box) #左下角 左上角 右上角 右下角
mianji = rect[1][0] * rect[1][1] # 车牌面积不应太小 ,太小就丢弃
# print(mianji)
if rect[2] >= -45:
if rect[1][1] != 0:
bili = (rect[1][0]) / (rect[1][1])
else:
print('error')
bili = 1 #这种情况是不可能的车牌不可能一边是0,这里做特殊处理
else:
if rect[1][0] != 0:
bili = rect[1][1] / rect[1][0]
# imgg = cv2.drawContours(imgg, [box], 0, (0, 0, 255), 2)
if (bili > 2.15 and bili < 4) and mianji>700:
# print(bili)
imgg = cv2.drawContours(imgg,[box],0,(0,0,255),2)
left_point_x = np.min(box[:, 0])
right_point_x = np.max(box[:, 0])
top_point_y = np.min(box[:, 1])
bottom_point_y = np.max(box[:, 1])三.效果



固定的场景下识别率还是很好的,至于第三张图片中的渝没有识别错误,这和本项目所用的数据集太小有关,并没有包含足够多的样本,训练时就无法找到足够的特征,针对这种情况在不改变网络模型的条件下,有两种方法:1.增大数据集,2.数据增强
四.源码
想要完整源码,请关注我,之后会整理好文件,把本次用到的数据集和图片,源码等打包放到我的github上。
2020.7.15更新
源码地址:https://github.com/ZJ-science/car_nn_demo,有用欢迎star~