这是关于编译原理的第三篇笔记。

编译有五大步骤,本篇笔记将会讲解编译的第一步:词法分析。
词法分析的任务是:从左往右逐个字符地扫描源程序,产生一个个的单词符号。也就是说,它会对输入的字符流进行处理,再输出单词流。执行词法分析的程序即词法分析器,或者说扫描器。
1.词法分析的成果
词法分析的成果就是由一系列单词符号构成的单词流。单词符号其实就是 token,一般有以下五大类:
- 关键字:例如
while,if,int等 - 标识符:变量名、常量名、函数名等
- 常数:例如,
100,'text',TRUE等 - 运算符:例如
+,*,/等 - 界符:逗号,分号,括号,点等
具体来说,一个单词符号在形式上是这样的一个二元式:(单词种别,单词符号的属性值)。
单词种别:
单词种别通常用整数编码。一个语言的单词符号如何分种,分成几种,怎样编码是一个技术问题。它取决于处理上的方便。
- 标识符一般统归为一种。比如说变量
a和b,可能我们都只用1作为它们的单词种别。 - 常数则宜按类型(整、实、布尔等)分种,比如说整数可能用
2表示,布尔值可能用3表示。 - 关键字可以把全体视为一种,也可以一字一种。
- 运算符可以把具有一定共性的运算符视为一种,也可以一符一种。
- 界符一般是一符一种。
单词符号的属性值
由上面的单词种别可以知道,关键字、运算符、界符基本都是一字(或者一符)对应一个种别,所以只依靠单词种别即可确切地判断出具体是哪一种单词符号了。但是标识符和常数却不是这样,一个种别可能对应好几个单词符号。所以我们需要借助单词符号的属性值做进一步的区分。
对于标识符类型的单词符号,它的属性值通常是一个指针,这个指针指向符号表的某个表项,这个表项包含了该单词符号的相关信息;对于常数类型的单词符号,它的属性值也是一个指针,这个指针指向常数表的某个表项,这个表项包含了该单词符号的相关信息。
以 while(i>=j)i++ 为例,它的单词符号流大概如下:
<(,->
<>=,->
<),->
<++,->
<;,-> 注意:实际上,对于关键字、界符这些,应该用整数表示单词种别,不过这里为了便于区分,直接用对应的单词符号表示了。对于标识符,由于 id 这个单词种别可能对应多个标识符,所以可以看到我们用不同的指针进行了标识。其它不需要标识的,则统一用短横线代替。
2. 词法分析的要点
2.1 是否作为一趟?
按照我们常规的想法,应该是词法分析器扫描整个源程序,产生单词流,之后再由语法分析器分析生成的单词。如果是这样,那么就说词法分析器独立负责了一趟的扫描。但其实,更多的时候我们认为词法分析器并不负责独立的一趟,而是作为语法分析器的子程序被调用。也就是说,一上来就准备对源程序进行语法分析,但是语法分析无法处理字符流,所以它又回过头调用了词法分析器,将字符流转化成单词流,再去分析它的语法。以此类推,后面每次遇到字符串流,都是这样的一个过程。
2.2 输入和预处理
字符流输入后首先到达输入缓冲区,在词法分析器正式对它进行扫描之前,还得先做一些预处理的工作。预处理子程序会对一定长度的字符流进行处理,包括去除注释、合并多个空白符、处理回车符和换行符等。处理完之后再把这部分字符流送到扫描缓冲区。此时,词法分析器才正式开始拆分字符流的工作。
词法分析器对扫描缓冲区进行扫描时一般使用两个指示器:起点指示器指向当前正在识别单词的开始位置,搜索指示器用于向前搜索以寻找单词的终点。问题在于,就算缓冲区再大,也难保不会出现突破缓冲区长度的单词符号。也就是说,输入缓冲区把处理好的一段字符流送到扫描缓冲区时,扫描缓冲区可能装不下这段字符流,在这种情况下,如果依然只用一个缓冲区存放字符流,可能会导致某个过长的单词符号无法被正确读取。因此,扫描缓冲区最好使用如下一分为二的区域:
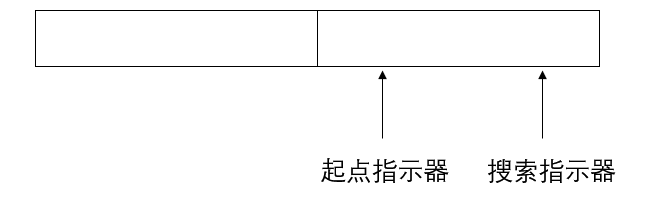
这样,在搜索指示器向前搜索到 A 半区边缘时,如果发现还没有找到单词符号的终点,那么就会调用预处理程序把剩下的部分送到 B 半区,搜索指示器再来到 B 半区扫描。这样就可以避免截断,从而将这个过长的单词符号顺利衔接起来。如果单词符号实在太长,两个半区都无法解决,那就没辙了。所以应该对单词符号的长度加以限制。
2.3 超前扫描
像 FORTRAN 这样的语言,关键字不加保护(只要不引起矛盾,用户可以用它们作为普通标识符),关键字和用户自定义的标识符或标号之间没有特殊的界符作间隔。这使得关键字的识别变得很麻烦。比如 DO99K=1,10 和 DO99K=1.10。前者的意思是,K 从 1 变到 10 之后,跳转到第 99 行执行;后者的意思是,为变量 DO99K 赋值 1.10。问题在于,我们并不能在扫描到 DO 的时候就肯定这是一个关键字,事实上,它既有可能是关键字,也有可能作为标识符的一部分。而具体是哪一种,只有在我们扫描到 =1 后面才能确定 —— 如果后面是逗号,则这是关键字,如果是点号,则是标识符的一部分。
也就是说,我们需要超前扫描到达第一个界符 =,但是 = 还不能确定,再继续超前扫描到达第二个界符(逗号或者点号),这时候才能完全确定。
3. 词法分析的模型
3.1 状态转换图
状态转换图是设计词法分析程序的一种模型,我们可以借助这个模型体会识别某个特定字符串的过程。它是一张有限方向图,结点表示状态,结点之间的箭弧上有字符,表示遇到该字符就将其读进来,并且转换到另一个状态。以下面这张图为例,在状态 0 下如果输入的是字母,则将字母读进来,并进入状态 1 ;在状态 1 下如果输入的是字母或者数字,则将其读进来并重新进入状态 1 。不断重复,直到输入的不是字母和数字,这时候也将其读进来,并进入状态 2。状态 2 是终态,有一个 * 作为标记,标记着多读进来一个不属于目标的符号,应该把它退还给原输入串。这张图实际表示的是标识符类型的输入串。
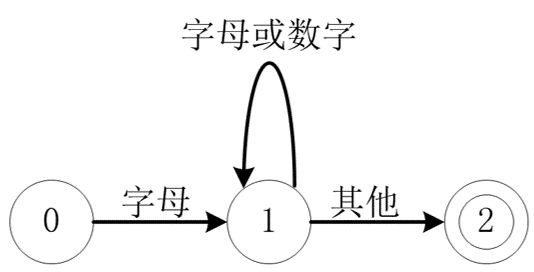
状态转换图的结点(状态)个数是有限的,其中有一个初态,以及至少一个终态(同心圆表示)。
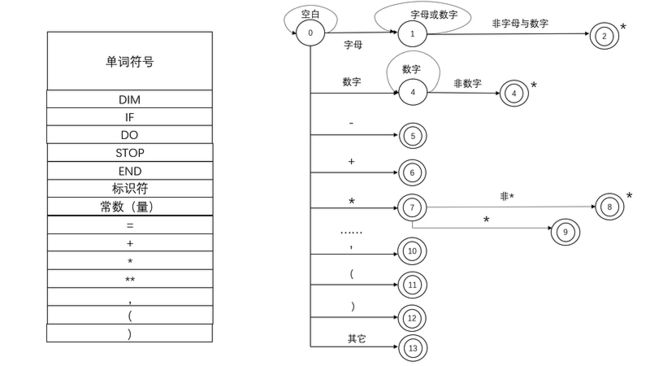
左图是 FORTRAN 语言的一些单词符号,右图是对应的状态转换图:
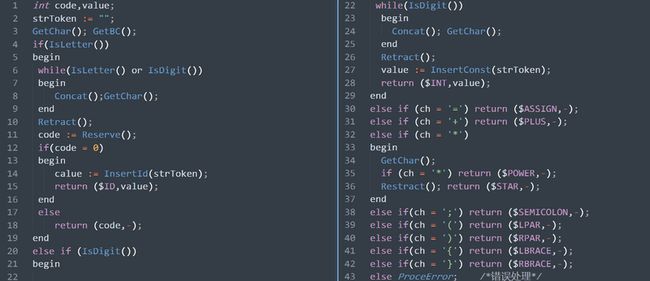
状态转换图的实现:

比如上面的状态转换图,它的词法分析器大概如下:
3.2 正规式与有限自动机
状态转换图是制造词法分析器的模型,不过这个模型过于具体,我们应该想个办法,用一种更接近数学的、更为形式化的方法来表示状态转换图。而这种状态转化图的形式化表达,就是有限自动机。由于有限自动机涉及到了正规式、正规集等其它概念,所以我们这里先普及一下这些概念。
① 正规式与正规集
推导
正规式和正规集都是相对于字母表来说的概念,通常说“xx 字母表的正规式是......,字母表的正规集是......”。对于正规式和正规集,我们采用递归的方式进行定义。即,对于某个给定的字母表 ∑,规定:
-
ε和Ø都是该字母表的正规式,这两个正规式分别表示了{ε}和Ø这两个正规集 - 字母表上的任意一个元素
a都是字母表的正规式,它表示了{a}这个正规集 - 如果
a和b都是字母表上的正规式,且分别表示了L(a)和L(b)这两个正规集。那么,(a|b),(ab),(a)*也都是正规式,它们分别代表了L(a)∪L(b),L(a)L(b)和(L(a))*这几个正规集。(笛卡尔积和闭包) - 仅由有限次使用上面三条规则而得到的表达式才是字母表上的正规式,仅由这些正规式表示的字集才是字母表上的正规集
根据上面这四条规则,我们可以递归列举出某个字母表的正规式和对应的正规集
例如对于给定的字母表 ∑ = {a,b},我们可以像下面这样推导出它的正规式和对应的正规集:
ba* :a 是正规式,所以 a* 也是正规式(规则二),所以 ba* 也是正规式(规则二)。a 表示 {a} 这个集合,加上星号则表示该集合的闭包,b 表示 {b} 这个集合,所以并排放在一起表示两个集合作笛卡尔积运算
等价的正规式
如果两个正规式 U 和 V 表示的正规集相同,则认为这两个正规式等价,记作 U = V。例如,b(ab)* 和 (ba)*b 就是等价的两个正规式。它们表示的集合形如 {ba,bb,bab,babab,babababab,......}。可以看出这个集合的元素特点是,以 b 开头,后面跟着 a 和 b 自由组合的符号串。在没有引入正规式的概念之前,要表示这样的集合是比较麻烦的,但现在则方便很多。
正规式运算规则
对于正规式 U,V,W,它们满足下面的运算规律:
1、交换律:U|V=V|U
2、结合律:U|(V|W)=(U|V)|W
3、结合律:(UV)W=U(VW)
4、分配律:U(V|W) = UV|UW
5、分配律: (V|W)U = VU|WU
6、零一律:εU=U
7、零一律:Uε=U
最后再来看一道题:
令 ∑={d,. ,e,+,-},其中d为 0~9 中的数字,则 ∑ 上的正规式
d*(.dd*|ε)(e(+|-|ε)dd*|ε)表示的是?
先来划分结构,以 d* 开头,说明第一个部分是一个整数,第二个部分是 (.dd*|ε),可以取空,第三个部分是 (e(+|-|ε)dd*|ε) ,同样可以取空。如果后面两个部分都取空,则肯定代表一个整数;如果第二个部分不取空,则会出现小数点,表明这时候会是一个小数;如果第三个部分不取空,则会出现 e,表明这是一个用科学计数法表示的数字。综上,这个正规式表示的是所有无符号数构成的集合。
有个需要注意的地方是,d* 已经可以表示所有整数了,为什么小数点后使用的是 dd* 而不是 d* 呢?这里其实是起到一个占位的作用,因为单纯用 d* 的话,其实也包括了空符号串,但是既然出现了小数点,后面至少要跟一位数,不能为空。所以这里用 dd*。对于 e 后面也是同理,既然出现了 e,后面就不能为空了。
② 确定有限自动机
1. 确定有限自动机的结构
我们先来回顾一下这副状态转换图:
考虑到要用形式化的方法来表示它,我们得先考虑转换图的一些重要组成因素。
- 首先想到的是,必须得有一个集合用来保存所有的状态
- 还需要有一个集合用来保存所有的输入字符
- 在某一个状态下,根据输入的字符不同,会跳转到不同的状态,这三者构成一个联系,多个联系自然也需要保存起来
- 初态是特殊的,需要单独保存
- 终态也是特殊的,需要单独保存
那么,我们可以构造一个有限的状态集合 S ,用以保存该转换图的所有状态;构造一个有限的字母集合 ∑,用以保存每一个输入的字符;构造包括多个单值映射对 的 δ,每一对都表示从“当前状态和输入字符”到“跳转状态”的映射关系。具体地说,用 δ(s,a) = a' 表示,当前状态为 s 且输入字符为 a 时,跳转到状态 a';此外,需要用来自于状态集合 S 的 s0 作为唯一的初态;最后,构造一个终态集合 F,它是 S 的子集,可取空。
这样,我们就有了 S,∑,δ,s0,F。这五个元素在一起就构成了我们要讲的是确定有限自动机。即,确定有限自动机 DFA 可用如下的五元式表示:
M = {S,∑,δ,s0,F}
2. 确定有限自动机的其它表示
正如我们所说的,有限自动机是抽象层面上的形式化表达,而它在具体层面上的表达就是之前所讲的状态转换图。另外,确定有限自动机还可以用一个矩阵来表示,这样的矩阵即 状态转换矩阵。它的行表示当前状态,列表示输入字符,而矩阵元素则表示跳转状态,也就是 δ(s,a) 的值。
以 DFA M = ({0,1,2,3,4},{a,b},δ,0,{3}) 为例,如果它的映射如下:
δ(0,a) = 1 δ(0,b) = 2
δ(1,a) = 3 δ(1,b) = 2
δ(2,a) = 1 δ(2,b) = 3
δ(3,a) = 3 δ(3,b) = 3那么它的状态转换矩阵如下所示:
| 当前状态 | a | b |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | 1 | 3 |
| 3 | 3 | 3 |
3. 确定有限自动机的作用
确定有限自动机是状态转换图的形式化表达,它可以用于识别(或者说读出、接受)正规集。
对于 ∑* 中的任何一个字 a,若存在一条从初态结点到某一终态结点的通路,且这条通路上所有箭弧的标记符连接成的字等于 a,则称 a 为 DFA M 所识别(读出或接受)。
如果 M 的初态结点同时也是终态结点,那么就说空符号串可以被 M 所识别。
DFA M 可以识别的字的全体记为 L(M)。
看下面的例子:
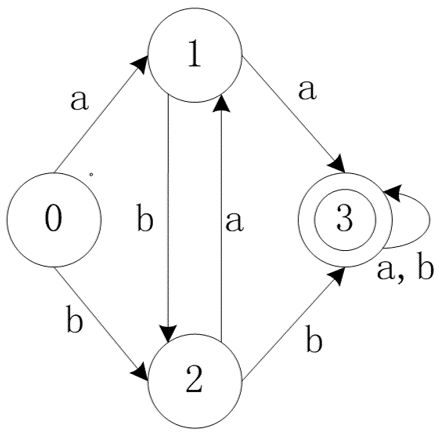
这是某个确定有限自动机对应的状态转换图,那么这个 DFA M 可以识别什么样的正规集呢?我们可以先走几条路线看看(假定在遇到状态 3 就停止),不难发现它可以识别出诸如 aa,bb,abb,baa 这样的符号串。这样的符号串的特点是,中间要么是 aa ,要么是 bb,所以首先确定中间是 (aa|bb)。由于 aa 和 bb 都可以独立存在,说明 (aa|bb)的前面和后面必须可以是空符号串,说到空符号串,我们会想到闭包,所以它的前面后面必定会分别出现一个闭包。考虑前面,可以出现 a 或者 b,所以前面应该是 (a|b)*;考虑后面,我们在遇到状态 3 的时候就停止了,但实际上,在这之后遇到 a 或者 b,状态变化会循环往复,也就是说,不管遇到什么样的 ab 组合符号串,都能够被识别并循环转换到状态 3,这里说明后面的状态是任意的,所以确定后面是 (a|b)*。
结合起来,这个有限自动机可以识别的正规集可以用正规式 (a|b)*(aa|bb)(a|b)* 表示。
③ 非确定有限自动机
1. “确定”和“不确定”指的是什么?
“确定”指的是,五元式中的映射是一个单值函数,也就是说,在当前状态下,面对某个输入字符,其跳转状态是唯一确定的,即只会跳转到某一个值。但是,有的时候映射是多值函数,也就是说,在某个输入字符下有多个跳转状态可供选择。具有这样特点的有限自动机,就叫做非确定有限自动机。
2. 非确定有限自动机的结构
非确定有限自动机可以用如下的五元式表示:
M = {S,∑,δ,s0,F}
- S 仍然是状态集合,∑ 仍然是输入字符集合,F 仍然是终态集合。
- 但是,s0 不再表示单个初态,而是表示一个非空的初态集合
- 另外,正如前面所说的,δ 不再是一个从“当前状态和输入字符”到“跳转状态”的单值映射,而是从“当前状态和输入字符集合闭包”到“跳转状态集合”的子集映射。简单地说就是,它接受的不一定是单个字符,且在单一输入下可以跳转到多个状态
3. 非确定有限自动机的作用
非确定有限自动机同样可以用于识别(或者说读出、接受)正规集。
对于 ∑* 中的任何一个字 a,若存在一条从初态结点到某一终态结点的通路,且这条通路上所有箭弧的标记符连接成的字等于 a,则称 a 为 NFA M 所识别(读出或接受)。
如果 M 的初态结点同时也是终态结点,或者存在一条从某个初态结点到某个终态结点的 ε 通路,那么就说空符号串 ε 可以被 M 所识别。(因为输入符号来自于集合闭包,所以输入符号接受空符号串 ε)
看下面的例子:
假设有非确定有限自动机 NFA M=({0,1,2,3,4},{a,b},δ,{0},{2,4}) ,其中,
δ(0,a)={0,3} δ(2,b)={2}
δ(0,b)={0,1} δ(3,a)={4}
δ(1,b)={2} δ(4,a)={4}
δ(2,a)={2} δ(4,b)={4}可以看到,有不少 δ 是被映射到 S 的一个子集,而不是像确定 DFA 那样映射到一个输入字符。这个 NFA 对应的状态转换图如下:
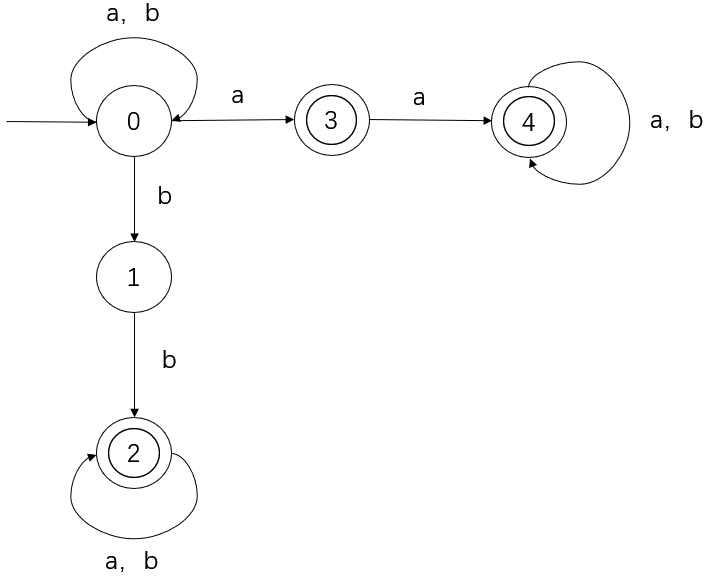
这里会发现,这个 NFA 所能识别的正规集和之前的 DFA 是一样的,都是含有相继两个 a 或者相继两个 b 的符号串。事实上,尽管 DFA 是 NFA 的特例,但是对于每个 NFA M,都会有一个 DFA M‘ 与之对应,使得 L(M) = L(M')。这时候,我们就说 NFA M 等价于 DFA M’。
③ 非确定有限自动机的确定化
非确定有限自动机的确定化,指的就是将非确定有限自动机转换为一个与之等价的确定有限自动机。总的来说分为两步,第一步是利用等价转换规则细化 NFA 状态转换的过程;第二步是利用子集法对第一步转化得到的 NFA 进行确定化。由于第二步又涉及到了一些概念,所以这里我们先来对这些概念进行解释。
相关概念:
(1)空闭包集合
若 I 是一个状态集合的子集,那么 I 会有一个空闭包集合,记作 ε-closure(I)。这个空闭包集合同样是一个状态集合,它的元素符合以下几点:
-
I的所有元素都是空闭包集合的元素 - 对于
I中的每一个元素,从该元素出发经过任意条 ε 弧能够到达的状态,都是空闭包集合的元素
以下面这张图为例:
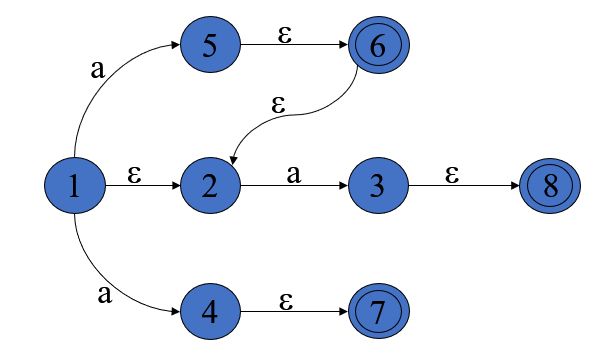
ε-closure({5,3,4}) 会等于多少呢?这里的 I 是 {5,3,4},所以空闭包集合一定包含了5,3,4。从 5 出发,经过一条 ε 弧到达 6,两条 ε 弧到达 2,所以 6 和 2 也是闭包集合的元素;从 3 出发,经过一条 ε 弧到达 8,所以 8 也是;从 4 出发,经过一条 ε 弧 7,所以 7 也是。综上,ε-closure({5,3,4}) = {5,3,4,6,2,8,7} 。
(2)Ia
若 I 是一个状态集合的子集,那么它相对于状态 a 的 Ia 等于 ε-closure(J)。其中,J 表示的是,从 I 中每个状态出发,经过标记为 a 的单条弧而到达的状态的集合。也就是说,Ia 表示的是从 I 中每个状态出发,经过标记为 a 的弧而到达的状态,再加上从这些状态出发,经过任意条 ε 弧能够到达的状态。
还是以这幅图为例:
当 I 是 {1,2} 的时候,Ia 等于多少呢?
- 从 1 出发,经过 a 弧能够到达 5 和 4,所以 5,4 属于
Ia。从 5,4 出发,经过 ε 弧能够到达 6,2,7,所以 6,2,7 属于Ia - 从 2 出发,经过 a 弧能够到达 3,所以 3 属于
Ia。从 3 出发,经过 ε 弧能够到达 8,2,7,所以 8 属于Ia
综上,Ia = {5,4,6,2,7,3,8}
下面,介绍具体的确定化过程。
第一步:规则转换
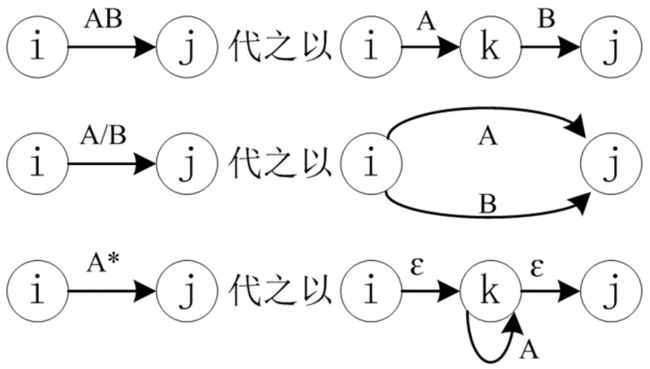
第一条和第二条都好理解,重点在第三条规则。为什么右边的图可以等价于左边的图呢?A* 其实表示的是类似 {ε,A,AA,AAA,AAAA,......} 这样的集合,因为 A 自由组合形成的符号串是可以用一个 A 的自循环来表示的,所以中间有一个自循环,而 ε 则可以用 εε 来表示,所以考虑在前后各加一个 ε,对于 A 的符号串不影响。
第二步:子集法转换
子集法的核心是,针对上面规则转换后得到的 NFA,画出它的状态转换矩阵,这个矩阵的矩阵元素是映射的子集,不是单值,而我们要做的事情就是把这个子集用一个单值来表示。也就是说,对于 NFA 的每一组映射状态集,都用一个来自 DFA 的映射单值与之对应,从而求出等价的 DFA。
假设经过第一步,我们已经得到下面的 NFA:
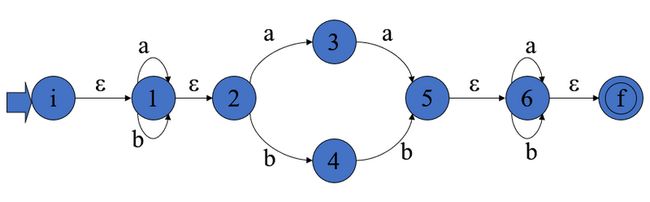
选取 NFA 的初态集合的空闭包作为初始集合 I,这个集合 I 将是 ε-closure({i}) = {i,1,2} 。同时由于输入符号只有 a 和 b,所以第二列为 Ia ,第三列为 Ib。得到如下这个表:
Ia |
Ib |
|
|---|---|---|
{i,1,2} |
根据前面的说法求解 Ia 和 Ib。从 i 出发没有 a 弧,无视之;从 1 出发经过 a 弧 到达 1,从 2 出发经过 a 弧到达 3;从 1 出发经过 ε 弧到达 2,从 1 出发没有 ε 弧。所以,Ia = {1,2,3}。从 i 出发没有 b 弧,无视之;从 1 出发经过 b 弧到达 1,从 2 出发经过 b 弧到达 4。从 1 出发经过 ε 弧到达 2,从 4 出发没有 ε 弧,所以 Ib = {1,2,4}。记新得到的两个
集合为 A 和 B,得到下面的表:
Ia |
Ib |
|
|---|---|---|
{i,1,2} |
A:{1,2,3} |
B:{1,2,4} |
将新得到的集合 A 和 B 作为第一列的元素,得到下面的表:
Ia |
Ib |
|
|---|---|---|
{i,1,2} |
A:{1,2,3} |
B:{1,2,4} |
A:{1,2,3} |
||
B:{1,2,4} |
分别对 A 集合和 B 集合求解对应的 Ia 和 Ib,得到下表(对于同样形式的集合仍采取之前命名,仅对新出现集合给定新的命名):
Ia |
Ib |
|
|---|---|---|
{i,1,2} |
A:{1,2,3} |
B:{1,2,4} |
A:{1,2,3} |
C:{1,2,3,5,6,f} |
B:{1,2,4} |
B:{1,2,4} |
A:{1,2,3} |
D:{1,2,4,5,6,f} |
将新得到的 C、D 集合作为第一列的元素,同样求解 Ia 和 Ib,得到下面的表:
Ia |
Ib |
|
|---|---|---|
{i,1,2} |
A:{1,2,3} |
B:{1,2,4} |
A:{1,2,3} |
C:{1,2,3,5,6,f} |
B:{1,2,4} |
B:{1,2,4} |
A:{1,2,3} |
D:{1,2,4,5,6,f} |
C:{1,2,3,5,6,f} |
C:{1,2,3,5,6,f} |
E:{1,2,4,6,f} |
D:{1,2,4,5,6,f} |
F:{1,2,3,6,f} |
D:{1,2,4,5,6,f} |
同理,继续推导,直到再也没有新集合出现:
Ia |
Ib |
|
|---|---|---|
{i,1,2} |
A:{1,2,3} |
B:{1,2,4} |
A:{1,2,3} |
C:{1,2,3,5,6,f} |
B:{1,2,4} |
B:{1,2,4} |
A:{1,2,3} |
D:{1,2,4,5,6,f} |
C:{1,2,3,5,6,f} |
C:{1,2,3,5,6,f} |
E:{1,2,4,6,f} |
D:{1,2,4,5,6,f} |
F:{1,2,3,6,f} |
D:{1,2,4,5,6,f} |
E:{1,2,4,6,f} |
F:{1,2,3,6,f} |
D:{1,2,4,5,6,f} |
F:{1,2,3,6,f} |
C:{1,2,3,5,6,f} |
E:{1,2,4,6,f} |
现在,用字母命名代替所有的集合(初始集合给定名字 S),得到下面的矩阵:
Ia |
Ib |
|
|---|---|---|
| S | A | B |
| A | C | B |
| B | A | D |
| C | C | E |
| D | F | D |
| E | F | D |
| F | C | E |
这个矩阵实际上已经是一个 DFA 矩阵。我们再以初始集合 S 将作为初态,包含原始 NFA 终态的集合(即 C、D、E、F)作为终态,画出它对应的状态转换图,如下:
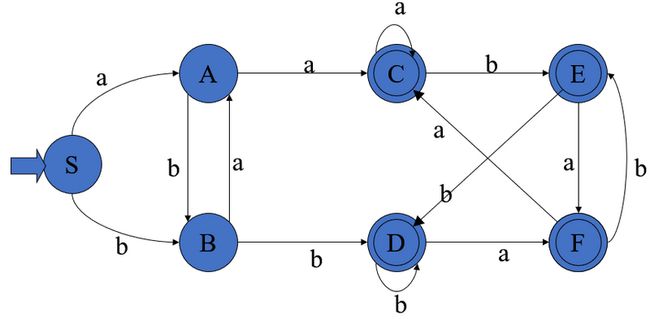
那么,这个转换图实际上就是与最初 NFA 等价的 DFA 所对应的转换图了,到这里,我们就完成了对非确定有限自动机进行确定化的工作了。
最后我们再对这篇笔记涉及的知识点做一下回顾。首先我们解释了词法分析的结果,也就是单词符号,之后讲解了一些词法分析过程中的要点(预处理、超前扫描),最后则是本篇笔记的重点,词法分析的模型,包括状态转换图以及它的形式化表达 —— 有限自动机。
到这里,词法分析的内容还没有结束。剩下的内容我们将在下一篇笔记中继续讲解。