Spark总结(SparkSQL)
什么是SaparkSQL?
SaprkSQL是spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataSet并且作为分布式SQL查询引擎的作用。
SparkSQL的由来
我们学过Hive,它是将Hive SQL转化为MapReduce然后提交集群上去运行,大大简化了编写MapReduce的程序的复杂性,但是由于计算的时候效率比较慢。所以SparkSql应运而生(刚开始的时候叫shark),SaprkSQL将Spark SQL转化为RDD,然后提交集群执行,执行效率很快。
Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制。
SparkSQL和Hive的效率比较
SparkSQL是兼容Hive语法的SQL执行引擎,由于底层计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,如果全部加载到内存的话,将快10倍以上。
SparkSQL的特性
SparkSQL on Hive:Hive只作为存储角色,Spark负责sql解析和执行。总的来说就是把hive的底层mapreduce换成spark的。
Hive on SparkSQL:Hive即作为存储有负责解析,Spark负责执行。
干什么的?
首先SparkSQL支持查询原生的RDD(RDD是spark平台的核心理念,是Spark能够高效处理大数据的各种场景的基础)。然后就是能在scala中写SQL语句,支持简单的SQL语法检查,能够在scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用
怎么用?
想要学会怎么用就先搞清楚Dataset/DataFrame
Dataset DataFrame和RDD
RDD是一个弹性分布式数据容器,特点是只有数据没有数据结构
DataFrame也是一个分布式数据容器;除了数据本身,还记录了数据结构,即schema(列的别名,通过这个别名可以知道有哪些列,每一列的数据和数据类型。);
DataSet是Spark中最上层的数据抽象,不仅包含了数据,schema,且还包含了数据集的类型;DataSet是由多个DataFrame组成的数据集,并且将数据集声明了具体的数据类型(比如:人相当于DataSet,一群人的数据:名字,年龄等等组成的数据就是DataFrame);也就是说把数据集做成了一个java对象的形式,数据集中的每一列就是样例类中的属性;
具体的参考:https://blog.csdn.net/weixin_43681796/article/details/89500999
ps:
(1)DataSet是面向对象的思想,把数据变成了对象的属性。
(2)DataSet是强类型,比如可以有DataSet[Car],DataSet[Person](汽车对象数据集,人对象数据集);DataFrame=DataSet[Row],DataFrame是DataSet的特例。
(3)在后期的Spark版本中,DataSet会逐步取代RDD和DataFrame成为唯一的API接口。
SparkSQL的魅力
SparkSQL的魅力就在于,它的底层将关系型数据库和非关系型数据库等数据源都关联到了一起,所以只要用SQL语句就可以了,不用管底层是什么数据源。SparkSQL的数据源可以是JSON类型的字符串,JDBC,Parquent,Hive,HDFS等。
SparkSQL的流程顺序
首先拿到SQL后进行解析,解析得到逻辑计划,再经过一批优化规则转换成最佳的逻辑计划,在经过SparkPlanner册celue转换成一批物理计划,最后经过消费模型转换成一个个的Spark任务执行。

小点:
谓词下推(底层优化中的一种)
提早进行数据过滤以及有可能更好地利用索引

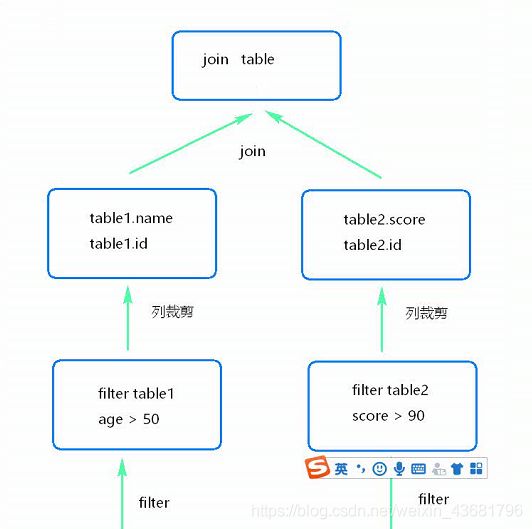
Dataset是1.6测试使用的,基本没人使用。但是2.0以后都在使用dataset了。
Dataset中包括了RDD和元数据信息(这就是一个完整的表)
Dataframe = dataset
Schema信息,字段顺序按照字典排序(也就是asc码)
打印数据信息时,默认打印20行