大数据组件-MapReduce编写规范,WordCount,实现SQL的join,共同好友,实现手机流量统计,实现小文件合并,分区放置文件,分组求TopN案例;MR分区,计数器,排序,规约,运行机制;
目录
- Mapreduce编程规范
- 1.Map 阶段 2 个步骤
- 2.Shule 阶段 4 个步骤
- 3.Reduce 阶段 2 个步骤
- WordConut案例
- 1.数据准备工作
- (1)创建一个新文件
- (2)向其放入以下数据并保存
- (3)上传到hdfs
- (4)配置maven
- 2.Mapper
- 3.Reducer
- 4.定义主类,形成job任务,提交执行
- MapReduce运行模式
- 1.集群运行模式
- (1)打包
- (2)jar包上传linux
- (3)运行
- 2.本地运行模式
- MapReduce分区
- 1.分区的概述
- 2.分区的代码实现步骤
- (1)定义Mapper
- (2)自定义Partitoner
- (3)定义Reducer
- (4)主类中设置分区类和ReduceTask个数
- MapReduce计数器
- 1.方式1:我们用上一个实现分区中MyMapper类来实现计数器
- 2.方式2:我们用上一个实现分区中MyReducer类来实现计数器
- MapReduce排序和序列化
- 1.排序的实现:自定义数据类型SortBean实现接口WritableComparable
- 2.Mapper
- 3.Reducer
- 4.Main入口
- MapReduce规约
- 1.规约的概念
- 2.规约实现步骤
- (1)自定义一个combiner继承Reducer,重写reduce方法
- (2)在jobMain中设置job.setCombinerClass(CustomCombiner.class)
- MapReduce实现手机流量统计案例
- 需求1:手机流量统计求和
- (1) 自定义map的输出value对象FlowBean类
- (2)定义Mapper类
- (3)定义Reducer类
- (4)main入口
- 需求2:手机流量倒叙排序
- (1)定义FlowBean类,实现排序与序列化
- (2)定义Mapper类
- (3)定义Reducer类
- (4)main入口
- 需求3:手机号码分区
- (1)定义类实现Patitioner接口
- (2)在job任务中指定分区类,和设置Reducer个数
- Mapreduce运行机制总览***
- MapReducer实现SQL语句的join案例
- 1.Reduce端实现SQL的join
- (1)定义Mapper
- (2)定义Reducer
- (3)定义主类
- 2.Map端实现SQL的join
- (1)Reducer端实现join的问题
- (2)Map端实现join
- MapReduce共同好友案例
- 1.MapReducer01
- (1)定义Mapper
- (2)定义Reducer
- (3)定义主类
- 2.MapReducer02
- (1)定义Mapper
- (2)定义Reducer
- (3)定义主类
- 通过自定义输入输出组件来实现特定需求
- 1.自定义InputFormat合并小文件
- (1)自定义InputFormat
- a.MyRecordReader
- b.MyInputforamt
- (2)Mapper类
- (3)设置job输出类
- 2.自定义OutputFormat实现数据分区放置
- (1)Mapper
- (2)自定义OutputFormat
- a.MyRecordWriter
- b.MyOutputFormat
- (3)主类JobMain
- 自定义分组求TopN案例
- 1.分组概念
- 2.需求
- 3代码实现
- (1)定义OrderBean排序类
- (2)定义Mapper
- (3)定义MyPartition分区类
- (4)orderGroupComparator分组类
- (5)定义Reduce
- (6)定义JobMain
Mapreduce编程规范
ctrl+n 搜索类

1.Map 阶段 2 个步骤
- 设置 InputFormat 类, 将数据切分为 Key-Value(K1[这一行相对文件的偏移量]和V1[表示这一行的文本数据]) 对, 输入到第二步
- 自定义 Map 逻辑, 将第一步的结果转换成另外的 Key-Value(K2和V2) 对, 输出结果
2.Shule 阶段 4 个步骤
- 对输出的 Key-Value 对进行分区 ,就是进行分类
- 对不同分区的数据按照相同的 Key 排序
- (可选) 对分组过的数据初步规约, 降低数据的网络拷贝
- 对数据进行分组, 相同 Key 的 Value 放入一个集合中
3.Reduce 阶段 2 个步骤
- 对多个 Map 任务的结果进行排序以及合并, 编写 Reduce 函数实现自己的逻辑, 对输入的 Key-Value 进行处理, 转为新的 Key-Value(K3和V3)输出
- 设置 OutputFormat 处理并保存 Reduce 输出的 Key-Value 数据
WordConut案例
1.数据准备工作
(1)创建一个新文件
cd /export/servers
vim wordcount.txt
(2)向其放入以下数据并保存
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world hadoop
(3)上传到hdfs
hdfs dfs -mkdir /wordcount/
hdfs dfs -put wordcount.txt /wordcount/
(4)配置maven
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<!--编译插件-->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<!--打包插件-->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.Mapper
| java类型 | 对应hadoop类型 |
|---|---|
| String | Text |
| Long | LongWritable |
创建一个WordCountMapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*四个泛型解释:
KEYIN:K1的类型
VALUEIN:V1的类型
KEYOUT:K2的类型
VALUEOUT:V2的类型
*/
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
//map方法将K1V1 转为 K2和V2
/*
参数:
key :K1 行偏移量
value:V1 每一行的文本数据
context:表示上下文对象,起到桥梁作用,把map阶段处理完成的数据给shuffle
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
LongWritable longWritable = new LongWritable();
//1.将一行的文本数据进行拆分
String[] split = value.toString().split(",");
//2.遍历数组:组装K2,V2
for (String word : split) {
//3.将k2,v2写入上下文中
text.set(word);
longWritable.set(1);
context.write(text,longWritable);
}
}
}
3.Reducer
如何将新的k2,v2转为k3,v3?
| k2 | v2 |
|---|---|
| hello | <1,1,1> |
| world | <1,1> |
| hadoop | <1> |
| k3 | v3 |
|---|---|
| hello | 3 |
| woeld | 2 |
| hadoop | 1 |
我们通过观察,可以发现k2和k3是没有发生变化的,唯一变化的是v2的数字集合,到v3变为:集合聚合成为单一数字了.
通过上述分析我们创建一个WordCountReducer类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*四个泛型解释:
KEYIN:K2类型
VALUEIN:v2类型
KETOUT:K3类型
VALUEOUT:V3类型
*/
public class WordCountReducer extends Reducer <Text, LongWritable,Text,LongWritable>{
//reduce作用:将新的k2,v2转化为k3,v3,将k3,v3写入上下文中
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
//1.遍历集合,将集合中的数字相加,得到v3
for (LongWritable val : values) {
sum += val.get(); //sum就是v3
}
//2.将k3,v3写入上下文中
context.write(key,new LongWritable(sum));
}
}
4.定义主类,形成job任务,提交执行
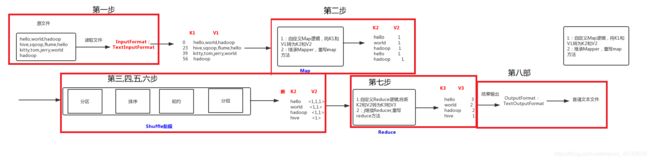
此主类有固定的模板
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
//该方法用于指定一个job任务
@Override
public int run(String[] args) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "wordcount");
//2.如果打包运行失败,则需要加该配置
job.setJarByClass(JobMain.class);
//2.配置job任务对象
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class); //指定输入类,读取文件
TextInputFormat.addInputPath(job,new Path("hefs://node01:8020/wordcount"));//指定源文件路径
//第二步:指定Map阶段的处理方式和数据类型
job.setMapperClass(WordCountMapper.class); //设置map阶段的指定类
job.setOutputKeyClass(Text.class); //设置map阶段k2的类型
job.setOutputValueClass(LongWritable.class);//设置v2的类型
//第三,四,五,六步:进入shuffle阶段,先默认处理
//第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步:
Path path = new Path("hdfs://node01:8020/wordcount_out");
job.setOutputFormatClass(TextOutputFormat.class); //采用什么样的输出方式
TextOutputFormat.setOutputPath(job,path);//目标目录已经存在是不能运行的
//----------------------以下是为了解决目标目录存在运行失败问题-----------
//获取文件系统
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
//判断目录是否存在
boolean b1 = fileSystem.exists(path);
if (b1){
//删除目标目录
fileSystem.delete(path,true);
}
//------------------截止----------------
//等待任务结束
boolean b = job.waitForCompletion(true);
return b ? 0:1; //如果b返回true返回0,否则返回1
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);//返回0任务执行成功
System.exit(run);
}
}
 三元运算符的格式
三元运算符的格式
[条件语句] ? [表达式1] : [表达式2]
其中如条件语句为真(即问号前面的条件成立)执行表达式1,否则执行表达式2.
MapReduce运行模式
1.集群运行模式
- 将 MapReduce 程序提交给 Yarn 集群, 分发到很多的节点上并发执行
- 处理的数据和输出结果应该位于 HDFS 文件系统
- 提交集群的实现步骤: 将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启 动
(1)打包
把我的程序打成jar包
 把打好的jar包复制粘贴到桌面,方便续向linux上传
把打好的jar包复制粘贴到桌面,方便续向linux上传
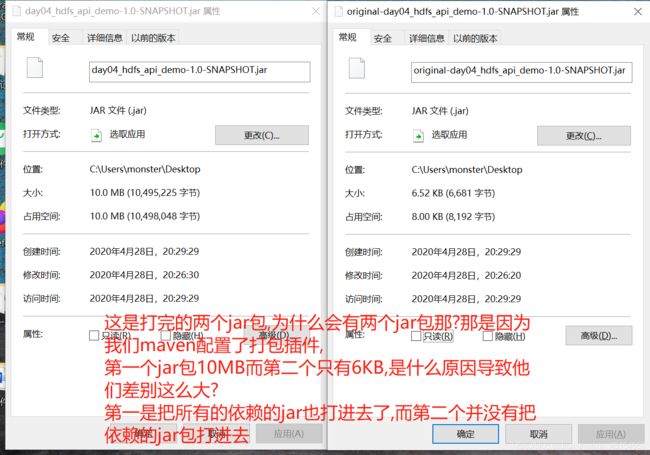
(2)jar包上传linux
在/export/servers路径下创建jar_text目录,把打好的jar包上传至此目录
cd /export/servers
mkdir jar_text
cd jar_text
(3)运行
在jar_text目录下进行如下操作:
hadoop jar original-day04_hdfs_api_demo-1.0-SNAPSHOT.jar yuge.JobMain //主类全路径名
怎样找到主类全路径名?
 运行完成
运行完成
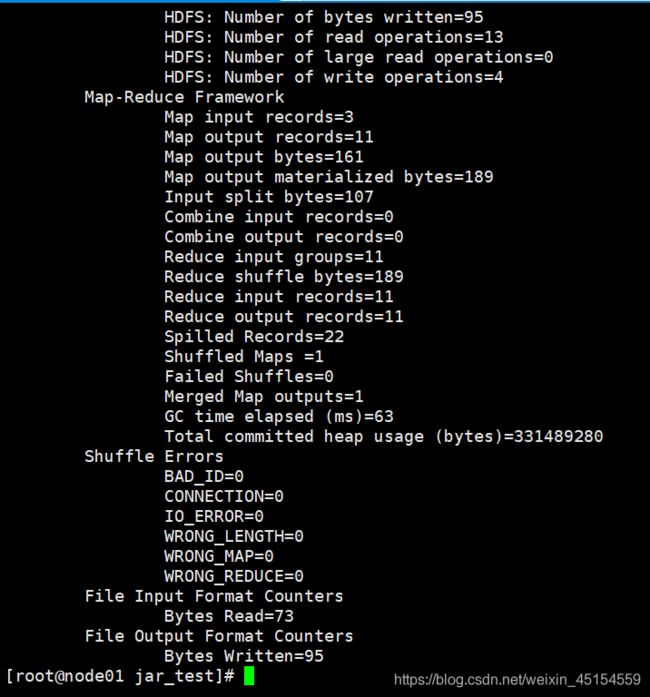
我们要去我们根路径下wordcount_out中找到我们到运行结果报告

2.本地运行模式
1.MapReduce程序是在本地以单进程的形式运行
2.处理的数据及输出的结果都在本地文件系统
这里直接右键run运行即可
package yuge;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
//该方法用于指定一个job任务
@Override
public int run(String[] args) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "wordcount");
//2.配置job任务对象
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class); //指定输入类,读取文件
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\input"));//指定源文件路径(本地路径)
//第二步:指定Map阶段的处理方式和数据类型
job.setMapperClass(WordCountMapper.class); //设置map阶段的指定类
job.setOutputKeyClass(Text.class); //设置map阶段k2的类型
job.setOutputValueClass(LongWritable.class);//设置v2的类型
//第三,四,五,六步:进入shuffle阶段,先默认处理
//第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步:
job.setOutputFormatClass(TextOutputFormat.class); //采用什么样的输出方式
TextOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\output")); //输出文件路径(本地路径)
//等待任务结束
boolean b = job.waitForCompletion(true);
return b ? 0:1; //如果b返回true返回0,否则返回1
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);//返回0任务执行成功
System.exit(run);
}
}
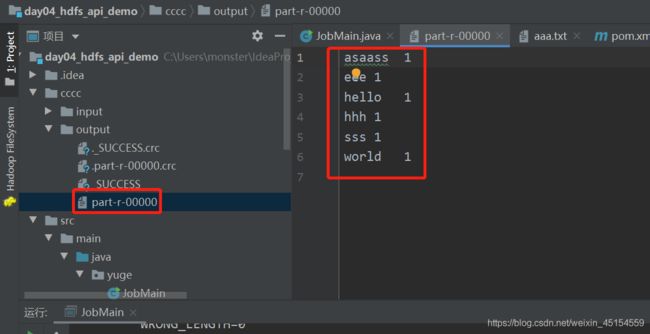
本地模式的使用场景?
本地模式非常便于进行业务逻辑的 Debug , 只要在IDEA中打断点即可
MapReduce分区
1.分区的概述
我们通过MapTask产生很多对键值对,这个时候面对我们一个多元化的结果时,使用一个单一的ReduceTask产生单一的结果文件,已不能满足我们的需求,我们需要使用不同的ReduceTask,分析键值对数据,产生不同的结果,这个时候我们需要对数据进行标号分区,传入不同的分析模型中.
2.分区的代码实现步骤
(1)定义Mapper
package yuge01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
k1-行偏移量LongWritable
v1-文本数据Text
k2-包含分区的行文本数据Text
v2-没有意义填一个占位符NullWriter
*/
public class MyMapper extends Mapper<LongWritable, Text,Text,NullWritable> {
//map这个方法是用来实现:传入k1,v1参数,将其转化为k2,v2
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
context.write(v1, NullWritable.get()); //这里NullWritable是一种类型,我们这里是要一个参数,所有要用.get()调用一下他的主类
}
}
(2)自定义Partitoner
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitoner extends Partitioner<Text,NullWritable> {
/*getPartition这个方法是用来指定我们分区规则的方法
返回的是int类型,就是我们的分区编号
param1:k2
param2:v2
param3:ReduceTask个数
*/
@Override
public int getPartition(Text text, NullWritable nullWritable, int i) {
String result = text.toString().split("\t")[5];
if (Integer.parseInt(result)>15){
return 1;
}
else {
return 0;
}
}
}

(3)定义Reducer
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
//reduce方法实现:将新k2,新v2转化为k3,v3
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get()); //NullWritable获取一个空对象
}
}
(4)主类中设置分区类和ReduceTask个数
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务,.run第二个参数是Tool接口的实现类对象
int run = ToolRunner.run(configuration, new MyJob(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), "words");
job.setJarByClass(MyJob.class);
//配置job对象任务:共计8步
//步骤一:读取文件
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/input"));
//步骤二:自定义map类和数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//步骤三:指定分区类
job.setPartitionerClass(MyPartitoner.class);
//步骤七:指定reducer类和数据类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置reducer task个数
job.setNumReduceTasks(2);
//步骤八:指定输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/out/partition_out"));
//等待任务结束
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
}
MapReduce计数器
1.方式1:我们用上一个实现分区中MyMapper类来实现计数器
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
k1-行偏移量LongWritable
v1-文本数据Text
k2-包含分区的行文本数据Text
v2-没有意义填一个占位符NullWriter
*/
public class MyMapper extends Mapper<LongWritable, Text,Text,NullWritable> {
//map这个方法是用来实现:传入k1,v1参数,将其转化为k2,v2
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
/*1.定义计数器
param1:定义计数器类型
param2:定义计数器的名称
*/
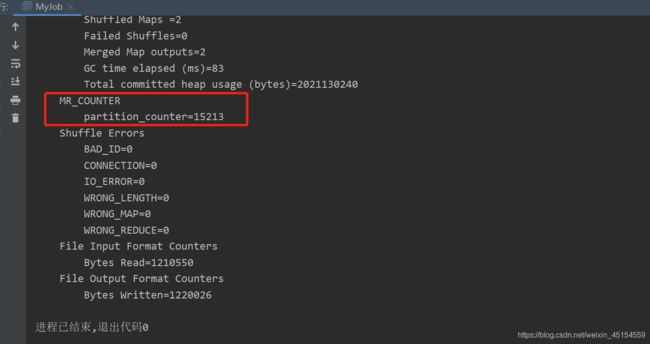
Counter counter = context.getCounter("MR_COUNTER", "partition_counter");
counter.increment(1L);//每次执行该方法,则计数器变量值加1
context.write(v1,NullWritable.get());
}
}
2.方式2:我们用上一个实现分区中MyReducer类来实现计数器
package yuge01;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
public static enum Counter{
MY_INPUT_RECOREDS,MY_INPUT_BYTES //我们随意定义两种类型不同的计数器
}
//reduce方法实现:将新k2,新v2转化为k3,v3
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//方式2:使用枚举来定义计数器
context.getCounter(Counter.MY_INPUT_BYTES).increment(1L); //调用其中的一种类型计数器
context.write(key,NullWritable.get()); //NullWritable获取一个空对象
}
}

MapReduce排序和序列化
什么叫序列化:把对象转化成字节流
主要是对象通过网络传输,对象保存到磁盘中
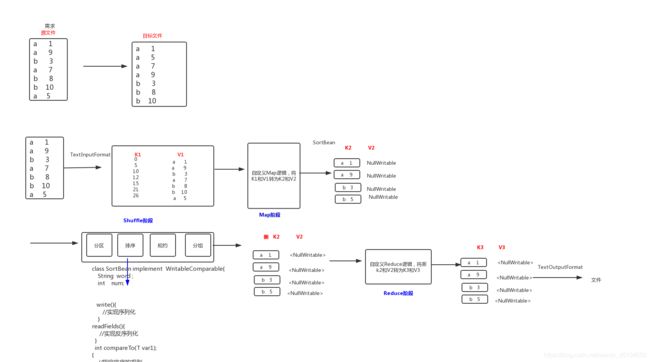
1.排序的实现:自定义数据类型SortBean实现接口WritableComparable
文件sort.txt数据格式如下
a 1
a 9
b 3
a 7
b 8
b 10
a 5
要求:
第一列按照字典顺序进行排列
第一列相同的时候, 第二列按照升序进行排列
设置一个实现WritableComparable接口的SortBean类
因为此类要经历网络传输,所以此类必须要实现序列化和反序列化
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class SortBean implements WritableComparable<SortBean> {
private String word;
private int num;
@Override
public String toString() {
return word +"\t" + num;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
//实现比较器,指定排序规则
/*
第一列word按照字典顺序进行排列
第一列相同的时候, 第二列num按照升序进行排列
这里我们仅仅需要,告诉比较器什么时候大于0什么时候是小于0的,
其他的不要关心,比较器会自动完成,帮助我们进行排序2
*/
@Override
public int compareTo(SortBean o) {
//先对第一列word进行排序
int result = this.word.compareTo(o.getWord());
//如果第一列相同,按照第二列num进行排序
if (result==0){
return this.num-o.getNum();
}
return result;
}
//序列化反序列化都是固定写法
//实现序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(word);
out.writeInt(num);
}
//实现反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.word = in.readUTF();
this.num = in.readInt();
}
}

2.Mapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text,SortBean, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.将文本数据v1进行拆分,并将数据封装到SortBean对象,就可以得到k2
String[] split = value.toString().split("\t");
SortBean sortBean = new SortBean();
sortBean.setWord(split[0]);
sortBean.setNum(Integer.parseInt(split[1]));
//2.将k2,v2写入上下文
context.write(sortBean,NullWritable.get());
}
}
3.Reducer
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//k2,v2-->k3,v3
public class MyReducer extends Reducer<SortBean, NullWritable,SortBean,NullWritable> {
@Override
protected void reduce(SortBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
4.Main入口
在hdfs上创建input目录,把sort.txt文件上传至input目录下
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class sortMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//创建job对象
Job job = Job.getInstance(super.getConf(), "words");
//配置job任务共计8步
//1.指定文件读取类,输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/input"));
//2.设置map类和数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(SortBean.class);
job.setMapOutputValueClass(NullWritable.class);
//3.4.5.6
//排序我们在mapper步骤时已经实现了
//7.设置reduce类和数据类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(SortBean.class);
job.setOutputValueClass(NullWritable.class);
//8.设置输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/output1"));
//等待执行
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration,new sortMain(),args);
System.exit(run);
}
}

MapReduce规约
1.规约的概念
规约是作用于map端的,是对map端的输出数据做一次合并,通过减少输出量从而达到优化MapReduce的目的
规约其实就是把Reudcer的事情提前在map端做一下
2.规约实现步骤
(1)自定义一个combiner继承Reducer,重写reduce方法
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyCombiner extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum =0;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key,new LongWritable(sum));
}
}
(2)在jobMain中设置job.setCombinerClass(CustomCombiner.class)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
//该方法用于指定一个job任务
@Override
public int run(String[] args) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "wordcount");
//2.如果打包运行失败,则需要加该配置
job.setJarByClass(JobMain.class);
//2.配置job任务对象
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class); //指定输入类,读取文件
TextInputFormat.addInputPath(job,new Path("hefs://node01:8020/wordcount"));//指定源文件路径
//第二步:指定Map阶段的处理方式和数据类型
job.setMapperClass(WordCountMapper.class); //设置map阶段的指定类
job.setOutputKeyClass(Text.class); //设置map阶段k2的类型
job.setOutputValueClass(LongWritable.class);//设置v2的类型
//第三:分区,四:排序,六:分组,先默认处理
//第五步:规约
job.setCombinerClass(MyCombiner.class)
//第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//第八步:
Path path = new Path("hdfs://node01:8020/wordcount_out");
job.setOutputFormatClass(TextOutputFormat.class); //采用什么样的输出方式
TextOutputFormat.setOutputPath(job,path);//目标目录已经存在是不能运行的
//等待任务结束
boolean b = job.waitForCompletion(true);
return b ? 0:1; //如果b返回true返回0,否则返回1
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new JobMain(), args);//返回0任务执行成功
System.exit(run);
}
}
MapReduce实现手机流量统计案例
数据文件data_flow.dat
需求1:手机流量统计求和
统计每个手机号的上行数据包总和,下行数据包总和,上行总流量之和,下行总流量之和
分析:以手机号码作为key值,上行流量,下行流量,上行总流量,下行总流量四个字段作为value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输入
(1) 自定义map的输出value对象FlowBean类
此类要作为map类中的一种自定义数据类型,后面要经历网络传输,所有必须要实现序列化和反序列化,故而要继承Writable接口
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable {
private Integer upFlow; //上行数据包数
private Integer downFlow; //下行数据包数
private Integer upCountFlow; //上行流量总和
private Integer downCountFlow; //下行流量总和
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getDownFlow() {
return downFlow;
}
public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
}
public Integer getUpCountFlow() {
return upCountFlow;
}
public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
}
public Integer getDownCountFlow() {
return downCountFlow;
}
public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
}
@Override
public String toString() {
return upFlow + "\t"+downFlow +
"\t"+upCountFlow +
"\t"+downCountFlow;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(upCountFlow);
out.writeInt(downCountFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readInt();
this.downFlow = in.readInt();
this.upCountFlow = in.readInt();
this.downCountFlow = in.readInt();
}
}
(2)定义Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//将v2的四个字段封装成为一个FlowBean对象
public class FlowCountMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
@Override
protected void map(LongWritable key, Text v1, Context context) throws IOException, InterruptedException {
//将k1,v1转为k2,v2
String k2 = v1.toString().split("\t")[1];
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(Integer.parseInt(v1.toString().split("\t")[6]));
flowBean.setDownFlow(Integer.parseInt(v1.toString().split("\t")[7]));
flowBean.setUpCountFlow(Integer.parseInt(v1.toString().split("\t")[8]));
flowBean.setDownCountFlow(Integer.parseInt(v1.toString().split("\t")[9]));
context.write(new Text(k2),flowBean);
}
}
(3)定义Reducer类
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
//将新的k2,v2转成k3,v3
//1.遍历集合,并将集合中对应字段累计
Integer upFlow= 0; //上行数据包数
Integer downFlow = 0; //下行数据包数
Integer upCountFlow = 0; //上行流量总和
Integer downCountFlow = 0; //下行流量总和
for (FlowBean value : values) {
upFlow += value.getUpFlow();
downFlow += value.getDownFlow();
upCountFlow += value.getUpCountFlow();
downCountFlow += value.getDownCountFlow();
}
//2.创建FlowBean并给对象赋值
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(upFlow);
flowBean.setDownFlow(downFlow);
flowBean.setUpCountFlow(upCountFlow);
flowBean.setDownCountFlow(downCountFlow);
context.write(key,flowBean);
}
}
(4)main入口
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Myjob extends Configured implements Tool {
//该方法用于指定一个job任务
@Override
public int run(String[] args) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "flow_count");
//2.配置job任务对象
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class); //指定输入类,读取文件
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/flow_input"));//指定源文件路径
//第二步:指定Map阶段的处理方式和数据类型
job.setMapperClass(FlowCountMapper.class); //设置map阶段的指定类
job.setOutputKeyClass(Text.class); //设置map阶段k2的类型
job.setOutputValueClass(FlowBean.class);//设置v2的类型
//第三:分区,四:排序,六:分组,先默认处理
//第五步:规约
//第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(FlowCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//第八步:
Path path = new Path("hdfs://node01:8020/flow_output");
job.setOutputFormatClass(TextOutputFormat.class); //采用什么样的输出方式
TextOutputFormat.setOutputPath(job,path);//目标目录已经存在是不能运行的
//等待任务结束
boolean b = job.waitForCompletion(true);
return b ? 0:1; //如果b返回true返回0,否则返回1
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new Myjob(), args);//返回0任务执行成功
System.exit(run);
}
}
需求2:手机流量倒叙排序
是在需求1的基础上,在对上行数据包数进行倒叙排列
(1)定义FlowBean类,实现排序与序列化
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements WritableComparable<FlowBean> {
private Integer upFlow;
private Integer downFlow;
private Integer upCountFlow;
private Integer downCountFlow;
@Override
public String toString() {
return upFlow +
"\t" + downFlow +
"\t" + upCountFlow +
"\t" + downCountFlow;
}
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getDownFlow() {
return downFlow;
}
public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
}
public Integer getUpCountFlow() {
return upCountFlow;
}
public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
}
public Integer getDownCountFlow() {
return downCountFlow;
}
public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
}
@Override
public int compareTo(FlowBean o) {
//return this.upFlow-o.upFlow; //升序
//降序
return o.upFlow-this.upFlow;
}
//序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(upCountFlow);
out.writeInt(downCountFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readInt();
this.downFlow = in.readInt();
this.upCountFlow = in.readInt();
this.downCountFlow = in.readInt();
}
}
(2)定义Mapper类
注意事项:这里你要实现上行流量包排序,那这后面的整个字段必须是key,因为只有key是可以产生排序,而val是不会产生排序的
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowSortMapper extends Mapper<LongWritable, Text,FlowBean,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//把k1,v1转化为k2,v2
String v2 = value.toString().split("\t")[0];
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(Integer.parseInt(value.toString().split("\t")[1]));
flowBean.setDownFlow(Integer.parseInt(value.toString().split("\t")[2]));
flowBean.setUpCountFlow(Integer.parseInt(value.toString().split("\t")[3]));
flowBean.setDownCountFlow(Integer.parseInt(value.toString().split("\t")[4]));
context.write(flowBean,new Text(v2));
}
}
(3)定义Reducer类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowSortMapper extends Mapper<LongWritable, Text,FlowBean,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//把k1,v1转化为k2,v2
String v2 = value.toString().split("\t")[0];
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(Integer.parseInt(value.toString().split("\t")[1]));
flowBean.setDownFlow(Integer.parseInt(value.toString().split("\t")[2]));
flowBean.setUpCountFlow(Integer.parseInt(value.toString().split("\t")[3]));
flowBean.setDownCountFlow(Integer.parseInt(value.toString().split("\t")[4]));
context.write(flowBean,new Text(v2));
}
}
(4)main入口
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Myjob extends Configured implements Tool {
//该方法用于指定一个job任务
@Override
public int run(String[] args) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "flow_sort");
//2.配置job任务对象
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class); //指定输入类,读取文件
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/flow_output"));//指定源文件路径
//第二步:指定Map阶段的处理方式和数据类型
job.setMapperClass(FlowSortMapper.class); //设置map阶段的指定类
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
//第三:分区,四:排序,六:分组,先默认处理
//第五步:规约
//第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(FlowSortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//第八步:
Path path = new Path("hdfs://node01:8020/sort_output");
job.setOutputFormatClass(TextOutputFormat.class); //采用什么样的输出方式
TextOutputFormat.setOutputPath(job,path);//目标目录已经存在是不能运行的
//等待任务结束
boolean b = job.waitForCompletion(true);
return b ? 0:1; //如果b返回true返回0,否则返回1
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new Myjob(), args);//返回0任务执行成功
System.exit(run);
}
}
需求3:手机号码分区
在需求一的基础上,继续完善,将不同的手机号分到不同的数据文件的当中去,需要自定义分区来实现,这里我们自定义来模拟分区,将以下数字开头的手机号进行分开
135 开头数据到一个分区文件
136 开头数据到一个分区文件
137 开头数据到一个分区文件
其他分区
设置分区:
(1)定义类实现Patitioner接口
package flow_count_demo;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class FlowPartition extends Partitioner<Text,FlowBean> {
//该方法用来指定分区规则-->就是返回对应的分区编号
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
String phoneNum = text.toString();
if (phoneNum.startsWith("135")){
return 0;
}
else if (phoneNum.startsWith("136")){
return 1;
}
else if (phoneNum.startsWith("137")){
return 2;
}
else {
return 3;
}
}
}
(2)在job任务中指定分区类,和设置Reducer个数
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Myjob extends Configured implements Tool {
//该方法用于指定一个job任务
@Override
public int run(String[] args) throws Exception {
//1.创建一个job任务对象
Job job = Job.getInstance(super.getConf(), "flow_partition");
//2.配置job任务对象
//第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class); //指定输入类,读取文件
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/flow_input"));//指定源文件路径
//第二步:指定Map阶段的处理方式和数据类型
job.setMapperClass(FlowCountMapper.class); //设置map阶段的指定类
job.setOutputKeyClass(Text.class); //设置map阶段k2的类型
job.setOutputValueClass(FlowBean.class);//设置v2的类型
//第三:分区,四:排序,六:分组,先默认处理
//第五步:规约
//分区
job.setPartitionerClass(FlowPartition.class);
//第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(FlowCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//设置reducer个数
job.setNumReduceTasks(4);
//第八步:
Path path = new Path("hdfs://node01:8020/flow_partition");
job.setOutputFormatClass(TextOutputFormat.class); //采用什么样的输出方式
TextOutputFormat.setOutputPath(job,path);//目标目录已经存在是不能运行的
//等待任务结束
boolean b = job.waitForCompletion(true);
return b ? 0:1; //如果b返回true返回0,否则返回1
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//启动job任务
int run = ToolRunner.run(configuration, new Myjob(), args);//返回0任务执行成功
System.exit(run);
}
}
Mapreduce运行机制总览***
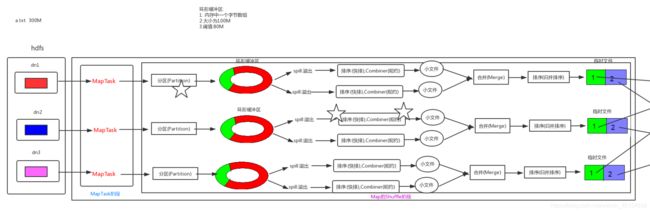 这里的Merge合并不是内容合并而是一种集中方式,是把一堆的小文件,放置在一个文件夹中,便于传输
这里的Merge合并不是内容合并而是一种集中方式,是把一堆的小文件,放置在一个文件夹中,便于传输
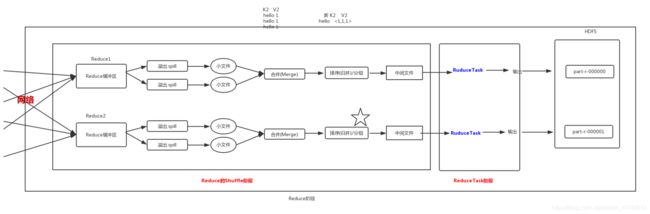
 在哪里我们能进行配置那?
在哪里我们能进行配置那?
cd /export/servers/hadoop-2.7.5/etc/hadoop/
ls
 不进行配置默认就是上述表格所表示的那些值
不进行配置默认就是上述表格所表示的那些值
MapReducer实现SQL语句的join案例

1.Reduce端实现SQL的join
(1)定义Mapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,Text> {
@Override
protected void map(LongWritable key, Text v1, Context context) throws IOException, InterruptedException {
//1.判断数据来自哪一个文件
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String name = fileSplit.getPath().getName();
if (name=="product.txt"){
//来自商品表
String[] split = v1.toString().split(",");
context.write(new Text(split[0]),v1);
}else{//来自订单表
String[] split = v1.toString().split(",");
context.write(new Text(split[-2]),v1);
}
}
}
(2)定义Reducer
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReduceJoinReduce extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text k2, Iterable<Text> v2, Context context) throws IOException, InterruptedException {
//解决商品拼接在前面
String first = "";
String second = "";
for (Text val : v2) {
if (val.toString().startsWith("p")) {
first = val.toString();
} else {
second += val.toString();
}
}
//v3 其实就是(first+second)
context.write(k2,new Text(first+"\t"+second));
}
}
(3)定义主类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//定义job任务
Job job = Job.getInstance(super.getConf(), "ReduceJoin");
//八步骤
//1.指定输入类,以及输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/join_input"));
//2.指定mapper类,及其数据类型
job.setMapperClass(ReduceJoinMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
//3.4.5.6.shuffle
//7.指定Reducer类,及其数据类型
job.setReducerClass(ReduceJoinReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//8.指定输出类,以及输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/join_output"));
//9.等待执行完毕
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
2.Map端实现SQL的join
(1)Reducer端实现join的问题
在Map端并没有对数据进行合并操作,而是将所有数据通过网络发送到Reduce端,在经历网络过程中,如果传输量过大网络传输的性能就会大大降低,会拖累最终的计算结果生成
(2)Map端实现join
适用于小表关联大表的情形
package mapJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class Jobmain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//获取job对象
Job job = Job.getInstance(super.getConf(), "mapJoin");
//job对象配置(8步)
//将小表放入分布式缓存
job.addCacheFile(new URI("hdfs://node01:8020/cache_file/product.txt"));
//第一步指定输入类和输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\input"));
//第二步指定map类和数据类型
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//
//第八部指定输出类和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\output"));
//等待job结束
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception {
//启动job任务
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new Jobmain(), args);
System.exit(run);
}
}

MapReduce共同好友案例
以下是qq的好友列表数据,冒号前是一个用户,冒号后是该用户的所有好友(数据中的好友关系是单向的)
A:B,C,D,F,E,O
B:A,C,E,K
C:A,B,D,E,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
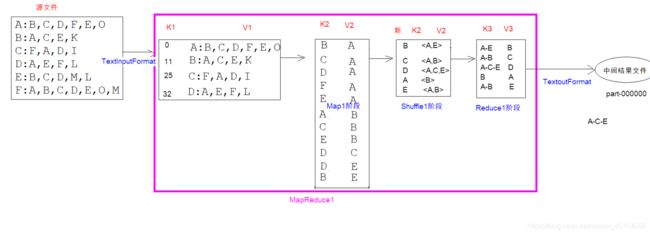 map的shuffle阶段不需要自己代码实现,他会自动的完成分组,把相同k对应的v值放置在同一集合中
map的shuffle阶段不需要自己代码实现,他会自动的完成分组,把相同k对应的v值放置在同一集合中
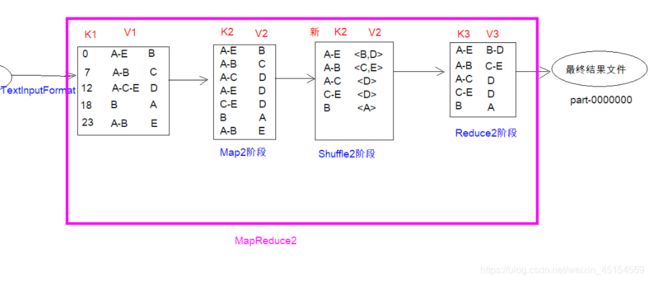 通过两个MapReduce来实现上述内容
通过两个MapReduce来实现上述内容
1.MapReducer01
(1)定义Mapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text,Text,Text> {
@Override
protected void map(LongWritable key, Text v1, Context context) throws IOException, InterruptedException {
String[] split = v1.toString().split(":");
String[] lst = split[1].split(",");
String v2 = split[0];
for (int i = 0; i < lst.length; i++) {
context.write(new Text(lst[i]),new Text(v2));
}
}
}
(2)定义Reducer
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text k2, Iterable<Text> v2, Context context) throws IOException, InterruptedException {
//变量集合,并将每一个元素进行拼接
StringBuffer Buffer = new StringBuffer();
for (Text text : v2) {
Buffer.append(text.toString()).append("-");
}
//k2就是v3
context.write(new Text(Buffer.toString()),k2);
}
}

(3)定义主类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//定义job
Job job = Job.getInstance(super.getConf(), "together_mapreduce");
//job设置
//指定读入类,及读入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\input\\orders.txt"));
//指定mapper类,及数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定reducer类,及数据类型
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输出类,和输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\output"));
//等待job结束
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
2.MapReducer02
(1)定义Mapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Arrays;
public class MyMapper extends Mapper<LongWritable, Text,Text,Text> {
@Override
protected void map(LongWritable key, Text v1, Context context) throws IOException, InterruptedException {
//1:拆分行文本数据,得到v2
String[] split = v1.toString().split("\t");
String k2 = split[0];
//2:继续以"-"为分隔符拆分行文本数据
String[] k2_split = k2.split("-");
//3:对拆分后的数组进行排序
Arrays.sort(k2_split);
String v2 = split[1];
//4.对数组中的元素进行两两组合,得到k2
/*
A B C
A B C
*/
for (int i = 0; i < k2_split.length-1; i++) {
for (int j = i+1; j < k2_split.length; j++) {
String k2_result = k2_split[i] + "-" + k2_split[j];
context.write(new Text(k2_result),new Text(v2));
}
}
}
}
(2)定义Reducer
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, Text,Text,Text> {
@Override
protected void reduce(Text new_k2, Iterable<Text> new_v2, Context context) throws IOException, InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
for (Text text : new_v2) {
stringBuffer.append(text.toString()).append("-");
}
context.write(new_k2,new Text(stringBuffer.toString()));
}
}
(3)定义主类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//定义job
Job job = Job.getInstance(super.getConf(), "together_result");
//job设置8步
//1.指定输入类,输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\output\\part-r-00000"));
//2.指定mapper类,数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//map的shuffle阶段3.4.reduce的shuffle阶段5.6,默认
//7.指定reducer类,数据类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//8.指定输出类,输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\day04_hdfs_api_demo\\cccc\\result"));
//等待job结束
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
通过自定义输入输出组件来实现特定需求
1.自定义InputFormat合并小文件
文件数据:自己可以写两到三个.txt文件
一个小文件内容就是一个BytesWritable
在业务处理之前,在HDFS上使用mapreduce程序对小文件进行合并
(1)自定义InputFormat
原来是一行一行的读,现在的需求是一整个文件的读,所有我们要重写RecordReader变为自定的
a.MyRecordReader
package MapReduce.example;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class MyRecordReader extends RecordReader<NullWritable, BytesWritable> {
//initialize的configuration想别其他方法所使用,需要向上提取
private Configuration configuration = null;
private FileSplit fileSplit = null;
private boolean processed = false;
private BytesWritable bytesWritable = new BytesWritable();
private FileSystem fileSystem = null;
private FSDataInputStream inputStream = null;
//初始化工作
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//获取configuration对象
configuration = taskAttemptContext.getConfiguration();
//获取文件的切片
fileSplit = (FileSplit) inputSplit;
}
//该方法用于获取k1,v1
/*
k1:NullWriter
v1:BytesWritable
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!processed){//文件没有读取完就是false,我们取反后就会继续读取
//1.获取源文件的字节输入流
//1.1获取源文件的文件系统FileSystem
fileSystem = FileSystem.get(configuration);
//1.2通过FileSystem获取文件字节输入流
inputStream = fileSystem.open(fileSplit.getPath());
//2.读取源文件数据到普通字节数组byte[]
byte[] bytes = new byte[(int)fileSplit.getLength()];
IOUtils.readFully(inputStream,bytes,0,(int)fileSplit.getLength());
//3.将字节数组中数据封装到BytesWeitable
bytesWritable.set(bytes,0,(int)fileSplit.getLength());
processed = true;
return true;
}
return false;
}
//返回k1
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
//返回v1
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return bytesWritable;
}
//获取文件读取进度
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
//进行资源释放
@Override
public void close() throws IOException {
inputStream.close();
fileSystem.close();
}
}
b.MyInputforamt
package MapReduce.example;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class MyInputFormat extends FileInputFormat<NullWritable, BytesWritable>{
//这里是定义了如何读取文件
@Override
public RecordReader createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//1.创建自定义RecordReader对象
MyRecordReader myRecordReader = new MyRecordReader();
//2.将inputSplithecontext对象传递给MyRecordReader
myRecordReader.initialize(inputSplit,taskAttemptContext);
return myRecordReader;
}
//设置文件是否可以被切割
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false; //不可以被切割
}
}
(2)Mapper类
package MapReduce.example;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class SequenceFileMapper extends Mapper<NullWritable, BytesWritable, Text,BytesWritable> {
@Override
protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException {
//获取文件的名字作为k2
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String name = inputSplit.getPath().getName();
context.write(new Text(name),value);
}
}
(3)设置job输出类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//定义job
Job job = Job.getInstance(super.getConf(),"meger_file");
//job配置8步
//指定输入类,和输入路径
job.setInputFormatClass(MyInputFormat.class);
MyInputFormat.addInputPath(job,new Path("file:///C:\\Users\\monster\\Desktop\\input"));
//指定Mapper类,和数据类型
job.setMapperClass(SequenceFileMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
//不需要设置Reducer类,但是必须设置数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
//指定输出类,和输出路径
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\MapReducerfile\\data\\output"));
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
2.自定义OutputFormat实现数据分区放置
数据文件(ordercomment.csv)
这里我们可以模仿TextOutputFormat的创建,来实现我们的MyOutputFormat
(1)Mapper
package partitionPlaced;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
(2)自定义OutputFormat
a.MyRecordWriter
package partitionPlaced;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class MyRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream badCommentOutputStream;
private FSDataOutputStream goodCommentOutputStream;
public MyRecordWriter() {
}
public MyRecordWriter(FSDataOutputStream badCommentOutputStream, FSDataOutputStream goongCommentOutputStream) {
this.badCommentOutputStream = badCommentOutputStream;
this.goodCommentOutputStream = goongCommentOutputStream;
}
/**
*
* @param text:一行的文本内容
* @param nullWritable:空
* @throws IOException
* @throws InterruptedException
*/
@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
//1.从行文本数据获取第9个字段
String[] split = text.toString().split("\t");
int comment = Integer.parseInt(split[9]);
//2.根据字段的值来判断评论的类型,然后将对应的数据写入不同的文件夹文件中
if (comment <= 1){
//好评或者中评
goodCommentOutputStream.write(text.toString().getBytes());
goodCommentOutputStream.write("\r\n".getBytes());
}else {
//差评
//写数据到文件夹中
badCommentOutputStream.write(text.toString().getBytes());
badCommentOutputStream.write("\r\n".getBytes());
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
IOUtils.closeStream(goodCommentOutputStream);
IOUtils.closeStream(badCommentOutputStream);
}
}
b.MyOutputFormat
package partitionPlaced;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MyOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//1.获取目标文件输出流(两个)
//1.2得到文件系统
FileSystem fileSystem = FileSystem.get(taskAttemptContext.getConfiguration());
//1.3通过文件系统获取输出流
FSDataOutputStream badCommentOutputStream = fileSystem.create(new Path("file:///C:\\Users\\monster\\IdeaProjects\\MapReducerfile\\data\\bad_comment\\bad_comment.txt"));
FSDataOutputStream goodCommentOutputStream = fileSystem.create(new Path("file:///C:\\Users\\monster\\IdeaProjects\\MapReducerfile\\data\\good_comment\\good_comment.txt"));
//2.将输出流传给MyRrcordWriter
MyRecordWriter myRecordWriter = new MyRecordWriter(badCommentOutputStream, goodCommentOutputStream);
return myRecordWriter;
}
}
(3)主类JobMain
package partitionPlaced;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//定义job
Job job = Job.getInstance(super.getConf(), "pattition_store");
//job8步
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\MapReducerfile\\data\\input"));
//指定Mapper类,和数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//不需要设置Reducer类,但是必须设置数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//指定输出类和输出路径
job.setOutputFormatClass(MyOutputFormat.class);
//这个指定文件是放置校验文件辅助性文件
MyOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\MapReducerfile\\data\\assist"));
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}

自定义分组求TopN案例
1.分组概念
分组是mapreduce当中reduce端的一个功能组件,主要的作用是决定哪些数据作为一组,调用一次reduce的逻辑,默认是每个不同的key,作为多个不同的组,每个组调用一次reduce逻辑,我们可以自定义分组实现不同的key作为同一个组,调用一次reduce逻辑

默认的分组是k相同的数据v值放在一个集合之内,通过我们自定义分组,设置订单id相同就是一组,订单id相同,其对应的v值放入到一个集合之内
2.需求
数据源:三个字段依次是订单id,商品id,成交金额
Order_0000001 Pdt_01 222.8
Order_0000001 Pdt_05 25.8
Order_0000002 Pdt_03 522.8
Order_0000002 Pdt_04 122.4
Order_0000002 Pdt_05 722.4
Order_0000003 Pdt_01 222.8
求出每一个订单成交金额最大的一笔交易
3代码实现
(1)定义OrderBean排序类
定义OrderBean实现WritableComparable接口的排序方法
package groupByOrders;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId;
private Double price;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
@Override
public String toString() {
return orderId + '\t' +
price;
}
@Override
public int compareTo(OrderBean o) {
int i = this.orderId.compareTo(o.orderId);
if (i==0){
//降序排列
i = this.price.compareTo(o.price) * -1;
}
return i;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeDouble(price);
}
@Override
public void readFields(DataInput in) throws IOException {
this.orderId =in.readUTF();
this.price = in.readDouble();
}
}

(2)定义Mapper
package groupByOrders;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text,OrderBean, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
OrderBean orderBean = new OrderBean();
String[] split = value.toString().split("\t");
orderBean.setOrderId(split[0]);
orderBean.setPrice(Double.parseDouble(split[1]));
context.write(orderBean,value);
}
}
(3)定义MyPartition分区类
把相同订单id的放置在一起,使用同一个Reduce处理
package groupByOrders;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartition extends Partitioner<OrderBean,Text> {
@Override
public int getPartition(OrderBean orderBean, Text text, int i) {
return (orderBean.getOrderId().hashCode() & 2147483647) % i;
}
}
(4)orderGroupComparator分组类
在这里插入代码片
(5)定义Reduce
package groupByOrders;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<OrderBean,Text,Text,NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int i =0;
for (Text k3 : values) {
context.write(k3,NullWritable.get());
i++;
if (i>=1){//我求top1.想求几,我就设置几
break;
}
}
}
}
(6)定义JobMain
package groupByOrders;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//创建job
Job job = Job.getInstance(super.getConf(), "group_by_orders");
//job设置共计8步
//1.设置输入类和输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\MapReducerfile\\data\\input"));
//2.指定Mapper类和数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputValueClass(Text.class);
job.setMapOutputKeyClass(OrderBean.class);
//3.分区
job.setPartitionerClass(MyPartition.class);
// 4.5.6.
//6.分组
job.setGroupingComparatorClass(OrderGroupComparator.class);
//7指定Reduce类和数据类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置Reduce数量,不设置Reduce数量,默认只有一个Reduce,文件输出到一个文件
//job.setNumReduceTasks(3);
//指定输出类,设置输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\monster\\IdeaProjects\\MapReducerfile\\data\\output"));
//等待job结束
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}